
Содержание
полезный разобрать слово по составу
35 БАЛЛ.Закончите высказывания, используя глаголы «мочь», «получаться», «удаваться» [4, с. 7].
1. Я мечтал увидеть президента, когда был в столице. Но
…
2. У меня сегодня невезучий день! Пирог сгорел, экзамен не
3. Я хотел построить на пляже дом из песка, но
4. На соревнованиях спортсмен хотел занять первое место, но у него заболела нога, и он
5. Мы хотели доехать до города, но по дороге автобус сломался, и мы вернулись домой. Так
6. Я очень хотел сделать домашнее задание, но электричество отключили и
Составьте 5 вопросов для совещания плиииииз
Как вы понимаете высказывание «Кто хочет прожить эту жизнь не напрасно, дарите добро каждый день, ежечасно»? (Желательно развёрнуто, в формате мини-со
…
чинения).
40баллов
Прочитайте текст об увлечениях великих людей. Озаглавьте его. С какой целью использованы подзаголовки? Напишите свое мнение (2-3 предложения
…
) о том, являются ли описанные увлечения великих людей «разумными развлече ниями». Что вы можете добавить к информации, данной в тексте?
Что вы можете добавить к информации, данной в тексте?
Продолжение текста :
Кроме чемоданов, ученый мастерил рамки, обложки, переплетал и прошивал книги. Знание химии и в этом деле сослужило ему добрую службу. Менделеев изобрел свой рецепт прочного клея, чем, конечно, повысил качество своих чемоданов.
А. Эйнштейн. Скрипач
Гениальный физик был многогранной личностью, и у него было много
разных увлечений.
Одним из них была игра на скрипке. И в этом деле он преуспел. Боль ше всего ему нравилось исполнять произведения Моцарта. Именно в его произведениях физика покоряла та прозрачность и гармония, которую он искал, строя свои теории Вселенной.
Кроме этого, Эйнштейн очень любил читать, он был страстным по клонником Достоевского, Брехта и Толстого. Еще одно большое увле чение гения физики-коллекционирование марок. Он говорил, что это помогает ему расслабиться, переключиться с напряженной умственной деятельности на творческое мышление.
когда переписываешь стихотворение, с красной строки нужно начинать писать?
Хелп, срочно, ВПР 8 КЛАСС, кто все порешает, 100БАЛЛОВ!!!
Помогите пожалуйста упражнение 238 по русскому языку 8 класс срочно! Пж
9. 3 сочинение утрата в.и.белов
3 сочинение утрата в.и.белов
придумать одно сложное предложение с «НЕ» разными частями речи
1. Расставить знаки препинания, графически объяснить их. НЕБО УСЫПА.ОЕ ЗВЕЗДАМИ НАКЛ. НЯЕТСЯ НАДДОРОгой по которой (НЕ)ТОРОпливо ИДЕТ ЧЕЛОВЕК.
…
2. Расставить знаки препинания, построить схемы.ЧЕЛОВЕК ОДАРЕН РАЗУМОМ И ТВОРЧЕСкой силой что(БЫ) ПР. УМНОЖАТЬ ТО ЧТО ЕМУ ДАНО. НЕЛЬЗЯдопустить что(БЫ) Люди НАПРАВЛЯЛИ НА СВОЕ СОБСТВЕ ОЕ УН. ЧТОЖЕНИЕ ТЕ СИЛЫ КОТОРЫЕ ИМУДАЛОСЬ ОТКРЫТЬ И ПОКОРИТЬ. 3. Разобрать по составу слова: ПОБЕЛЕЛА, ПЕРЕЗРЕВШАЯ,появляются,ЗАПОЗДАЛАЯ,высохшиЕ. 4. Сделать синтаксический разбор предл.: Я ВОСХИЩАЮСЬДОБРЫМИ ЛЮДЬМИ ПОТОМУ ЧТО) они ИЗЛУЧАЮТ СВЕТЛУЮ ЭНЕРГИЮ.
Разбор слова по составу — морфемный разбор, правила, примеры
Существует чёткое правило, которое надо выполнять, чтобы сделать разбор слова по составу без ошибок. Для этого надо строго следовать порядку разбора, не пропуская ни одного шага, и помнить об указанных ниже особых и трудных случаях.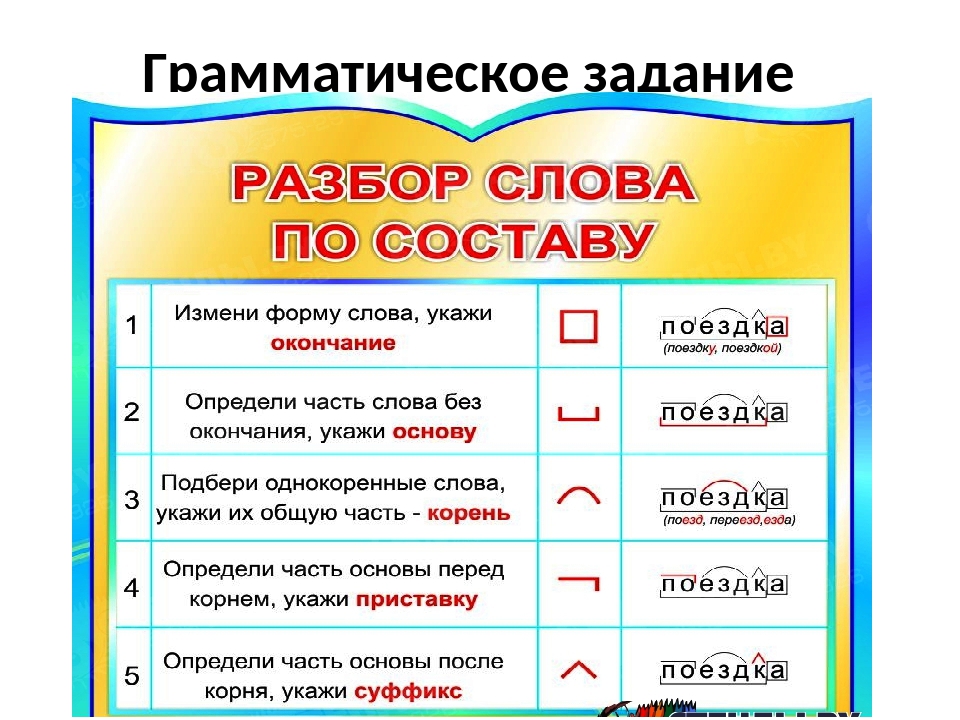
Алгоритм разбора слова по составу
Алгоритм разбора слова по составу — пошаговая последовательность. Она помогает правильно выполнить работу. Используемый приём сравнения развивает логическое мышление.
Обязательная поэтапность разбора любого слова по составу:
- Выделение окончания
- Определение основы
- Подбор однокоренных слов, выделение корня.
- В последнюю очередь выделение приставок и суффиксов
Чтобы правильно, безошибочно выделить окончание, необходимо образовать другую словоформу. Сопоставить две формы одного и того же слова. Изменившаяся часть слова — окончание. Оставшаяся без изменения — основа.
Особенности определения окончания на примере разных частей речи
Разбор по составу существительного
Например, слово «пеналом». Образуя форму слова, изменяем падеж: «пеналу». Изменилась часть –ом. Значит, это окончание.
Образовывать форму слова необходимо, чтобы не ошибиться в трудных случаях: сравним слова «коров» и «столов». В первом слове окончание нулевое, а –ов — часть корня («корова»), во втором — -ов окончание.
В первом слове окончание нулевое, а –ов — часть корня («корова»), во втором — -ов окончание.
Важно помнить о наречии «домой», где — ой — суффикс: у существительных 2 склонения («дом — 2 склонение») нет окончания –ой. Наречия не изменяются, значит, у него вообще нет окончания. Всё слово — основа.
Имя прилагательное
Слово «волшебными» поставим в форму женского рода единственного числа: «волшебная». Сравниваем формы слова, изменяется часть –ыми. Это окончание.
Чтобы правильно выделить корень в слове, обязательно требуется подбирать родственные слова. Важно помнить: приставки, а также суффиксы изменяют лексическое значение. Подбор однокоренных слов помогает без ошибок определить эти морфемы.
Примеры
Бесполезный — то, в чём нет никакой пользы
полезный
польза
Общая часть — корень — польз- . Приставка бес- стоит перед корнем, после него — суффикс –н.
Парашютист — человек, спускающийся с парашютом
парашют
Состав слова: корень, суффикс -ист и нулевое окончание.
Глагол «повторяете» настоящего времени. Попробуем изменить лицо: «повторяют». Вывод: окончание –ете.
«Заставили» — «заставила»: в первом глаголе окончание –и.
Примеры разбора слов по составу
Разбор слова Настенный
- Изменяем форму слова: настенная. Окончание –ый.
- Основа настенн-.
- Подбираем однокоренные слова: стена, пристенок. Находим корень: -стен-
- Сопоставляем все родственные слова: видим приставку на-, суффикс –н-.
- Доказываем наличие этих морфем в других словах: на-поль-н-ый, на-столь-н-ый.
Разбор слова Сползает
- Изменяем форму слова: сползают. Окончание –ет.
- Основа сполза-.
- Подбираем однокоренные слова: ползёт, заползал, ползание. Находим корень: -полз-
- Сопоставляем все однокоренные слова: видим приставку с-, суффикс –а-.
- Доказываем наличие этих морфем в других словах: с-бивают, с-пис-а-ть, прочит-а-ть.
Разбор слова Запевает
- Изменяем форму слова: запеваю.
 Окончание –ет.
Окончание –ет. - Основа запева-.
- Подбираем однокоренные слова: петь, пение, запевала. Находим корень: -пе-
- Сопоставляем все родственные слова: видим приставку за-, суффикс –ва-.
Разбор слова Повторяла
- Изменяем форму слова: повторяли. Окончание –а.
- Основа повторя-.
- Подбираем однокоренные слова: вторить, второй. Находим корень: -втор-
- Сопоставляем все однокоренные слова: видим приставку по-, суффикс –я-.
Разбор слова Преподаватель
- Изменяем форму слова: преподавателю. Окончание нулевое.
- Основа преподаватель.
- Подбираем однокоренные слова: преподавать, подавать, давать (знания), дать. Находим корень: -да-.
- Сопоставляем все родственные слова: видим приставки пре-, по-, суффикс –ва-.
Разбор слова Вверху
- Это наречие. Неизменяемое слово. У неизменяемых слов вообще нет окончания.
- Основа всё слово вверху.
- Подбираем однокоренные слова: наверху, верховный, верх.
 Находим корень: -верх-.
Находим корень: -верх-. - Сопоставляем все однокоренные слова: видим приставку в-, суффикс –у.
Разбор слова Разноцветный
- Изменяем форму слова: разноцветное. Окончание -ый.
- Основа разноцветн-.
- Подбираем однокоренные слова: разный, разница, различие, цветной, цвет. Находим два корня: разн-, -цвет-. Это сложное прилагательное.
- Сопоставляем все однокоренные слова: видим соединительную гласную –о-, суффикс –н-.
Изучение состава слова играет значительную роль при формировании орфографической зоркости.
Дети начинают понимать и запоминают: все части слова неизменны в написании и не зависят от произношения.
Трудные случаи при разборе слова по составу
Проводя анализ слов, школьники не всегда обращают внимание на лексическое значение разбираемого слова. Это часто приводит к ошибкам, особенно при выделении суффиксов.
- слова оканчиваются на -чик-, –щик-, -ист, -ушк.
В словах с такими суффиксами подбор однокоренных слов обязателен. (Мяч-ик — мяч, ключ-ик— ключ, рез-чик — резать, ящик, хрящ-ик — хрящ, камен-щик — камень; аист, лист; ушко, нес-ушк-а).
(Мяч-ик — мяч, ключ-ик— ключ, рез-чик — резать, ящик, хрящ-ик — хрящ, камен-щик — камень; аист, лист; ушко, нес-ушк-а).
Анализируя состав слова «каменщик», находим существительное, от которого оно образовано: камень; «плащик» — это небольшой плащ. Соответственно видим в словах суффиксы –щик, -ик.
Необходимо обучить детей разграничению понятий «оканчивается на…» и «окончание». Слово «автобус» оканчивается на –бус (-ус, -с), но окончание нулевое.
Непонимание разницы в значениях приводит к частым ошибкам при морфемном анализе глаголов в неопределённой форме.
- элемент –ть (читать, считать)
в учебных пособиях разных авторов рассматриваются или как суффикс, или как окончание. В любом случае предшествующий гласный в эту часть слова не входит.
Рассмотрим –ть как окончание неопределённой формы. Слово «ускорять» оканчивается на –ять (это важно при определении спряжения глагола), здесь –я- — суффикс и окончание –ть. «Побороть» оканчивается на –оть: -о- — суффикс, окончание –ть.
Умение разбирать последовательно слово по составу приобретается при постоянной работе по алгоритму. Нарушение последовательности или игнорирование приводит к ошибкам. Внимание к слову — основа успеха.
Морфемный разбор
Разбор слова по составу называют ещё морфемным разбором.
Сначала определяют границы окончания, изменяя форму слова (склоняют или спрягают слово). Затем выясняют часть речи, иначе разбор будет неправильным. Изменяемая часть является окончанием. В нём содержится грамматическое значение слова.
Домик-ом – существительное Т.п. и ед.ч.
Чёрн-ому – прилагательное м.р., ед.ч. и П.п.
Плыл-и – глагол мн.ч.
Окончания могут быть многозначными, одно и то же окончание выражает несколько разных грамматических значений (сравните: стекл-о – сущ. ед.ч. и стекл-о – глаг. ср.р. и ед.ч.).
Полк-а – существительное И.п. и ед.ч.
Знал-а – глагол ж.р. и ед.ч.
Прекрасн-а – прилагательное ж. р. и ед.ч.
р. и ед.ч.
Окончание существительного состоит из одной буквы (земл-я, стран-а, арми-я, окн-о, мор-е, собрани-е, подлежаще-е) или бывает нулевым (стол, конь, врач, воробей, гений, мышь, осень).
Окончание прилагательного или причастия в полной форме состоит из двух букв, в краткой форме сокращается на одну букву или становится нулевым в форме мужского рода (син-ий, голуб-ой, син-яя, голуб-ая, син-ее, голуб-ое; нежен, нежн-а, нежн-о, нежн-ы).
Прилагательные синий и лисий внешне похожи, но относятся к разным разрядам (первое качественное, второе притяжательное) и отвечают на разные вопросы. А кроме этого, они еще отличаются своими окончаниями: в слове лисий выделяется суффикс -ий, а окончание нулевое.
Окончание у глаголов выделяется не так просто. Сначала нужно определить его форму. Если это инфинитив (начальная форма), то он не изменяется, то есть не имеет непостоянных признаков, а значит, у него нет никакого окончания. В большинстве случаев он легко узнается по особым приметам: -ть, -ти, -чь (плыть, нести, беречь).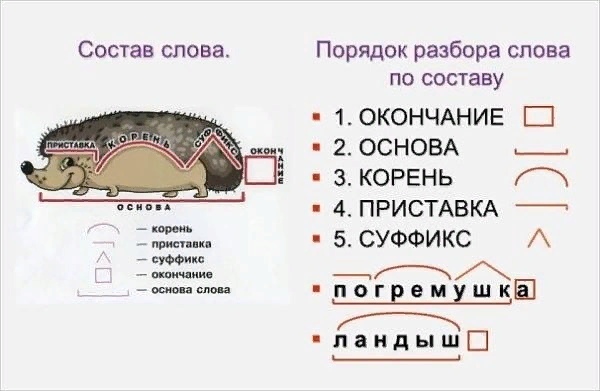
Форма прошедшего времени глагола определяется по суффиксу -л- (пел, пел-а, пел-о, пел-и, смеял-ся, смеял-а-сь, смеял-о-сь, смеял-и-сь). Здесь нужно отбросить постфикс -ся или -сь, потому что окончание стоит перед ним.
Формы настоящего и будущего времени глагола легко вспомнить (буквы Е, У, Ю есть в глаголах I спряжения, а буквы И, А, Я – в глаголах II спряжения): делаешь, делаете, делаем, делают; стоишь, стоите, стоим, стоят.
В повелительном наклонении глагола перед окончанием может быть суффикс И, а окончание ТЕ: ид-и-те, пиш-и-те (или режь, режь-те, возь-ми, стой).
Местоимения не разбираем по составу в школе, слишком странно выглядит их корень (к-ого-нибудь, ч-ем-то).
Числительные имеют не одно окончание, а сразу два, причем одно из них находится в середине слова: семьсот, сем-и-сот, семь-ю-ст-ами, сем-и-ст-ах.
В деепричастиях, наречиях, категории состояния, служебных словах, междометиях и звукоподражаниях окончание искать совсем не будем, так как это неизменяемые части речи.
После окончания выделяем основу слова. Она может совпадать с корнем (берег, гор-а), и это непроизводная основа. Она может включать в себя приставку, суффикс (пере-ход, бес-полез-н-ый, дом-ик) и быть производной основой.
Основа простая, если состоит из одного корня (красн-ый), она становится сложной, если имеет несколько корней (пар-о-ход). В основе содержится лексическое значение слова. В основу входят и постфиксы -ся, -сь. Тогда она становится прерывистой (сме-ёшь-ся – основа смеся). В основу не включаются интерфиксы (соединительные гласные О-Е): тепл-о-ход, птиц-е-фабрика.
В каждом слове присутствует корень. Это главная часть слова, в которой заключается общее значение всех однокоренных слов (трав-а, трав-к-а, трав-инк-а, трав-ян-ой, трав-ян-ист-ый). В нём часто видны чередования гласных и согласных звуков (рАсти – срАщение – вырОс; друг – друзья – дружба).
Приставка – знАчимая часть слова, которая находится перед корнем и служит для образования новых слов и форм слов. Приставка состоит из одного звука или нескольких, как гласного, так и согласного (у-нёс, с-петь, по-розовел, при-вкус, сверх-герой). В слове можно найти более одной приставки: без-от-чётный, пере-с-читывать.
Приставка состоит из одного звука или нескольких, как гласного, так и согласного (у-нёс, с-петь, по-розовел, при-вкус, сверх-герой). В слове можно найти более одной приставки: без-от-чётный, пере-с-читывать.
Каждая приставка имеет своё значение, может быть многозначной, к ней легко подобрать приставку-синоним или антоним.
Приставка бес- имеет значение отсутствия (бес-порядок, бес-конечность).
Приставка вы- имеет синоним по- (вы-мыть и по-мыть).
Приставка в- имеет антоним вы- (в-толкнуть – вы-толкнуть).
Есть даже приставки-омонимы: по-мёрзли, по-бежали, по-сидели, по-стирали.
Новые слова: не-счастье, ис-писать, бес-полезный.
Формы слова: наи-лучший, с-делать.
И по своему происхождению приставки бывают исконными и иноязычными: под-нести, контр-игра.
Суффикс – знАчимая часть слова, которая находится после корня и служит для образования новых слов и форм слов. Одно слово иногда содержит несколько суффиксов: за-бол-е-ва-ем-ость. Некоторые суффиксы выступают в разных вариантах: буфет-чик, стеколь-щик.
Некоторые суффиксы выступают в разных вариантах: буфет-чик, стеколь-щик.
Суффиксы, как и приставки, тоже обладают лексическим значением, есть многозначные суффиксы, есть суффиксы-синонимы и омонимы.
Суффиксы -ек, -ик обладают уменьшительно-ласкательным значением: орех – ореш-ек, дом – дом-ик.
Синонимические суффиксы: стакан-чик и газет-чик; учи-тель и выключа-тель.
Суффиксы-омонимы: свин-ин-а, солом-ин-а, голос-ин-а, царап-ин-а, шир-ин-а.
Новые слова: син-ев-а, дожд-лив-ый, капитан-ск-ий.
Формы слов: тиш-е, красив-ее, пе-ть, прыга-л, бежа-вш-ий, увиде-в.
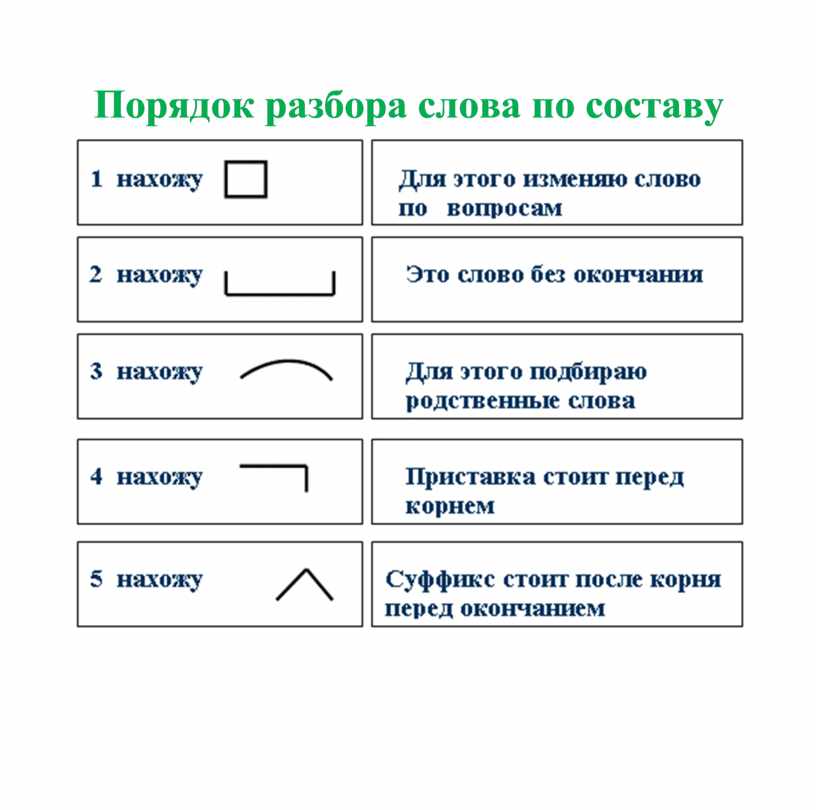
Порядок разбора слова по составу
- Определить часть речи.
- Обозначить окончание слова (если есть).
- Выделить основу.
- Через ряд однокоренных слов найти корень слова, отметить чередование звуков.
- Установить приставку или приставки.
- Установить суффикс или суффиксы.

Образец разбора слова по составу
Переплетение – сущ. ед.ч., И.п., нет переплетени-я или переплетени-ем, окончание Е.
Основа «переплетени». Однокоренные слова: плету, плеть, плетешь. Корень «плет».
Приставка пере- служит для образования нового слова.
Суффикс -ени[j] служит для образования нового слова.
Пере-плет-ени-е.
Порозовел – глагол, прошедшее время, ед.ч., м.р., окончание нулевое.
Основа «порозове» (-л – формообразующий суффикс). Однокоренные слова: розовый, розоветь. Корень «роз».
Приставка по- обозначает начало действия, служит для образования нового слова.
Суффикс -ов- служит для образования нового слова.
Суффикс -е- служит для образования нового слова.
По-роз-ов-е-л Ø
Выполните разбор по составу следующих слов:
Побеседовать
Беспорядочный
Невосприимчивость
Избранный
Сгнивший
Усмехаясь
Направо
Проверьте себя!
Состав слова и методика его изучения на уроках русского языка в начальной школе курсовая по педагогике
ОГЛАВЛЕНИЕ ВВЕДЕНИЕ ГЛАВА I. МОРФЕМНЫЙ СОСТАВ СЛОВА. 1. Понятие морфем. 2. Виды морфем. 3. Значение морфем. ГЛАВА II. МЕТОДИКА ИЗУЧЕНИЯ СОСТАВА СЛОВА В НАЧАЛЬНЫХ КЛАССАХ. 1. Причины трудностей и ошибок младших школьников в разборе слов по составу. 2. Распределение программного материала и содержание работы. 3. Методы и приемы изучения состава слов. ЗАКЛЮЧЕНИЕ ЛИТЕРАТУРА. ПРИЛОЖЕНИЕ. ВВЕДЕНИЕ Тема курсовой работы «Состав слова и методика его изучения в начальной школе на уроках русского языка» значима в современном языкознании, потому что задача пропедевтической работы состоит в подготовке учащихся к пониманию семантической (смысловой) и структурной соотносимости, которая существует в языке между однокоренными словами. Такая задача обусловлена, во-первых, тем, что понимание семантико-структурной соотносимости слов по своей лингвистической сущности является основой усвоения особенностей однокоренных слов и образования слов в русском языке. Во-вторых, указанная задача продиктована трудностями, с которыми сталкиваются младшие школьники при изучении однокоренных слов и морфем.
МОРФЕМНЫЙ СОСТАВ СЛОВА. 1. Понятие морфем. 2. Виды морфем. 3. Значение морфем. ГЛАВА II. МЕТОДИКА ИЗУЧЕНИЯ СОСТАВА СЛОВА В НАЧАЛЬНЫХ КЛАССАХ. 1. Причины трудностей и ошибок младших школьников в разборе слов по составу. 2. Распределение программного материала и содержание работы. 3. Методы и приемы изучения состава слов. ЗАКЛЮЧЕНИЕ ЛИТЕРАТУРА. ПРИЛОЖЕНИЕ. ВВЕДЕНИЕ Тема курсовой работы «Состав слова и методика его изучения в начальной школе на уроках русского языка» значима в современном языкознании, потому что задача пропедевтической работы состоит в подготовке учащихся к пониманию семантической (смысловой) и структурной соотносимости, которая существует в языке между однокоренными словами. Такая задача обусловлена, во-первых, тем, что понимание семантико-структурной соотносимости слов по своей лингвистической сущности является основой усвоения особенностей однокоренных слов и образования слов в русском языке. Во-вторых, указанная задача продиктована трудностями, с которыми сталкиваются младшие школьники при изучении однокоренных слов и морфем.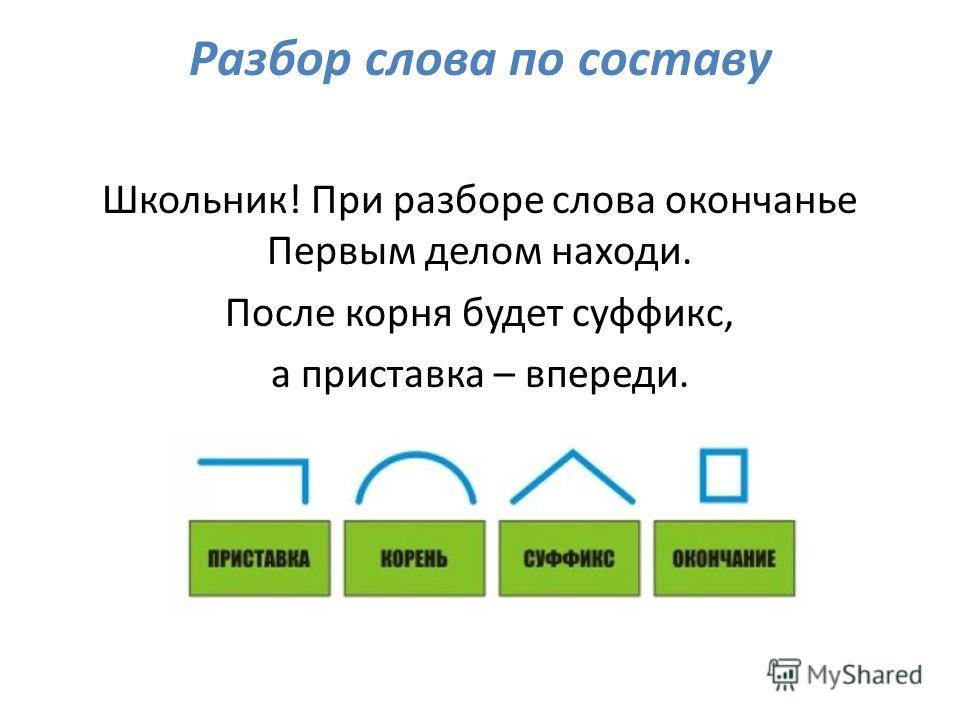 Цель работы: рассмотреть морфемный состав слова и методику изучения в начальных классах. Задачи: — подобрать, изучить и систематизировать литературу по теме; — описать морфемный состав слова в современном русском языке; — рассмотреть методы и приемы работы по изучению состава слова; — изучить опыт работы учителей школ по данной теме. Объект исследования: состав слова. Предмет исследования: методика изучения состава слова в начальной школе, на уроках русского языка. Методы исследования: Теоретические методы: 1) изучение методологических основ; 2) изучение «истории вопроса» и изучение всей литературы по вопросу, анализ всего прошлого опыта, сопоставление прошлого опыта с современным положением дела; Окончания являются носителями сразу нескольких грамматических значений: рода, числа, падежа у имен, лица, числа у глаголов. Носителем лексического значения является только корневая морфема. Синкретические морфемы, совмещающие словообразовательное и грамматическое значения, в языке немногочисленны.
Цель работы: рассмотреть морфемный состав слова и методику изучения в начальных классах. Задачи: — подобрать, изучить и систематизировать литературу по теме; — описать морфемный состав слова в современном русском языке; — рассмотреть методы и приемы работы по изучению состава слова; — изучить опыт работы учителей школ по данной теме. Объект исследования: состав слова. Предмет исследования: методика изучения состава слова в начальной школе, на уроках русского языка. Методы исследования: Теоретические методы: 1) изучение методологических основ; 2) изучение «истории вопроса» и изучение всей литературы по вопросу, анализ всего прошлого опыта, сопоставление прошлого опыта с современным положением дела; Окончания являются носителями сразу нескольких грамматических значений: рода, числа, падежа у имен, лица, числа у глаголов. Носителем лексического значения является только корневая морфема. Синкретические морфемы, совмещающие словообразовательное и грамматическое значения, в языке немногочисленны. Это, главным образом, глагольные приставки. Например, приставки в-/во-, до-, за- и др. в сочетании с глаголом идти, выражая, например, движения (внутрь, к предмету, за предметом и т.д.) в то же время изменяют вид глагола, переводя его из несовершенного вида в совершенный. Два признака морфем – обобщенность и нелинейность (парадигматический характер) – однозначно являются интегральным. Парадигматический характер морфемы проявляется в ее способности входить в сопоставление с единицами, обладающими структурной общностью, но различающимися по смыслу, что подтверждает ее типовой, а следовательно, и обобщенный характер. Это можно показать на примере имен существительных с суффиксом – щик – чик, обозначающими лицо по профессии или занятию: гардероб-щик -, морожен-щик -, прицеп-щик-, обход-чик — , рез-чик — , разнос-чик-, лет-чик — – и т.д. Что касается слова, то оно изучается в морфемике с грамматической точки зрения. В этом плане наряду с его внутренним строением и членимостью на значимые части рассматриваются особенности его словоизменения и формообразования [1, С.
Это, главным образом, глагольные приставки. Например, приставки в-/во-, до-, за- и др. в сочетании с глаголом идти, выражая, например, движения (внутрь, к предмету, за предметом и т.д.) в то же время изменяют вид глагола, переводя его из несовершенного вида в совершенный. Два признака морфем – обобщенность и нелинейность (парадигматический характер) – однозначно являются интегральным. Парадигматический характер морфемы проявляется в ее способности входить в сопоставление с единицами, обладающими структурной общностью, но различающимися по смыслу, что подтверждает ее типовой, а следовательно, и обобщенный характер. Это можно показать на примере имен существительных с суффиксом – щик – чик, обозначающими лицо по профессии или занятию: гардероб-щик -, морожен-щик -, прицеп-щик-, обход-чик — , рез-чик — , разнос-чик-, лет-чик — – и т.д. Что касается слова, то оно изучается в морфемике с грамматической точки зрения. В этом плане наряду с его внутренним строением и членимостью на значимые части рассматриваются особенности его словоизменения и формообразования [1, С.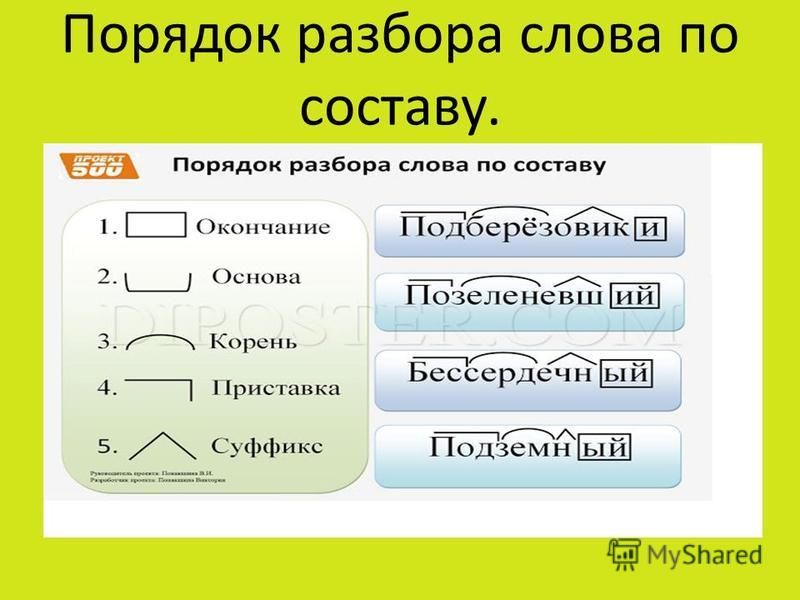 55]. Кроме интегрально-дифференциальных у морфемы есть и собственно различительные признаки. Наиболее важным из них являются признак ее минимальности, проявляющийся в невозможности дальнейшего членения морфемы на более мелкие части без нарушения ее смысловой целостности. В противном случае образуются незначимые единицы низшего уровня – фонемы. К различительным признакам морфемы относится и ее структурная выделяемость в составе слова, поэтому морфема связана с единицами высшего, синтаксического уровня не прямо, а опосредованно, об этом свидетельствует невозможность выступать в качестве члена предложения и занимать в нем определенную синтаксическую позицию. Что касается признака повторяемости морфемы, то это характерное для нее свойство (большинство морфем употребляются минимум в двух словах одного и того же словообразовательного ряда: учи-тель, писа-тель, ваяя-тель, оформи-тель и т.п.) относится не всеми лингвистами к числу ее обязательных дифференциальных признаков. Таким образом, наиболее предполагаемым понятием морфемы является понятие, в которой говорится, что морфема – это минимально значимая единица языка, у которой план выражения может отсутствовать при сохранении известной смысловой целостности.
55]. Кроме интегрально-дифференциальных у морфемы есть и собственно различительные признаки. Наиболее важным из них являются признак ее минимальности, проявляющийся в невозможности дальнейшего членения морфемы на более мелкие части без нарушения ее смысловой целостности. В противном случае образуются незначимые единицы низшего уровня – фонемы. К различительным признакам морфемы относится и ее структурная выделяемость в составе слова, поэтому морфема связана с единицами высшего, синтаксического уровня не прямо, а опосредованно, об этом свидетельствует невозможность выступать в качестве члена предложения и занимать в нем определенную синтаксическую позицию. Что касается признака повторяемости морфемы, то это характерное для нее свойство (большинство морфем употребляются минимум в двух словах одного и того же словообразовательного ряда: учи-тель, писа-тель, ваяя-тель, оформи-тель и т.п.) относится не всеми лингвистами к числу ее обязательных дифференциальных признаков. Таким образом, наиболее предполагаемым понятием морфемы является понятие, в которой говорится, что морфема – это минимально значимая единица языка, у которой план выражения может отсутствовать при сохранении известной смысловой целостности. Морфема – единица двуплановая, обладающая и формой и содержанием. Этим она принципиально отличается от фонемы, не имеющей значения, а также от слога. Морфема – единица воспроизводимая, говорящий не создает морфем в речи, а берет их из хранящегося в памяти «инвентаря» языковых единиц, тогда как предложения относятся к числу единиц, создаваемых говорящим непосредственно в речевом общении. 2. Виды морфем. Корнем, или корневой морфемой, является неделимая общая часть всех родственных слов, содержащая в себе основной элемент их лексического значения. На основе общности значения корневых морфем в словообразовательной системе языка образуются гнезда родственных слов. При этом в составе корня происходят различные чередования как гласных, так и согласных звуков, например к//ч – волк, волч-ий; г//ж – сапог, сапож-н- ый; х//ш, о//нудь звука – мох, за-мш-ел-ый; м//мл – корм-и-ть, кормл-ени-е; и// е – замиро-а-ть, за-мер-е-ть и т.д. Корневые морфемы могут быть свободными (молодой, молодость) и связанными (улица, переулок).
Морфема – единица двуплановая, обладающая и формой и содержанием. Этим она принципиально отличается от фонемы, не имеющей значения, а также от слога. Морфема – единица воспроизводимая, говорящий не создает морфем в речи, а берет их из хранящегося в памяти «инвентаря» языковых единиц, тогда как предложения относятся к числу единиц, создаваемых говорящим непосредственно в речевом общении. 2. Виды морфем. Корнем, или корневой морфемой, является неделимая общая часть всех родственных слов, содержащая в себе основной элемент их лексического значения. На основе общности значения корневых морфем в словообразовательной системе языка образуются гнезда родственных слов. При этом в составе корня происходят различные чередования как гласных, так и согласных звуков, например к//ч – волк, волч-ий; г//ж – сапог, сапож-н- ый; х//ш, о//нудь звука – мох, за-мш-ел-ый; м//мл – корм-и-ть, кормл-ени-е; и// е – замиро-а-ть, за-мер-е-ть и т.д. Корневые морфемы могут быть свободными (молодой, молодость) и связанными (улица, переулок).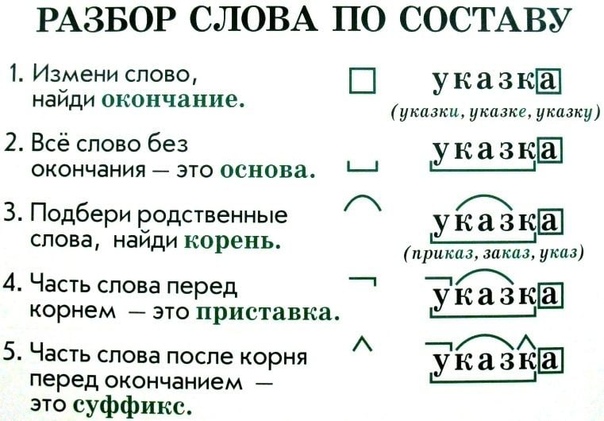 Корень это такая минимальная значимая часть, которая противопоставлена всем другим морфемам, т.е. аффиксам: приставкам, суффиксам, окончаниям и некоторым другим. Корень в отличии от аффиксов –обязательная часть в слове. Если слово состоит из одной морфемы, то это корень: тут, и, кино и т.п. Корень составляет основу непроизводных, или по-другому, немотивированных, слов: сын, голова, дом и т.п. Значение таких простых слов «никак не связано с их звуковым обликом, не вытекает из него, о нем нельзя догадаться, его нужно знать. Если вам не известно, что значат сочетания звуков, образующие слова собака, лошадь, стена, дело, окно, яйцо и другие подобные, то вы догадаться об этом не можете. А значение производных слов определяется значением слов простых, мотивировано им, подобно тому, как свойства химических соединений зависят от свойств входящих в них элементов» (4, С. 6). Слова, имеющие общую мотивацию, составляют группы однокоренных слов. То, что в лингвистике трактуется как общая мотивация, в школьной практике называют сходством по смыслу.
Корень это такая минимальная значимая часть, которая противопоставлена всем другим морфемам, т.е. аффиксам: приставкам, суффиксам, окончаниям и некоторым другим. Корень в отличии от аффиксов –обязательная часть в слове. Если слово состоит из одной морфемы, то это корень: тут, и, кино и т.п. Корень составляет основу непроизводных, или по-другому, немотивированных, слов: сын, голова, дом и т.п. Значение таких простых слов «никак не связано с их звуковым обликом, не вытекает из него, о нем нельзя догадаться, его нужно знать. Если вам не известно, что значат сочетания звуков, образующие слова собака, лошадь, стена, дело, окно, яйцо и другие подобные, то вы догадаться об этом не можете. А значение производных слов определяется значением слов простых, мотивировано им, подобно тому, как свойства химических соединений зависят от свойств входящих в них элементов» (4, С. 6). Слова, имеющие общую мотивацию, составляют группы однокоренных слов. То, что в лингвистике трактуется как общая мотивация, в школьной практике называют сходством по смыслу.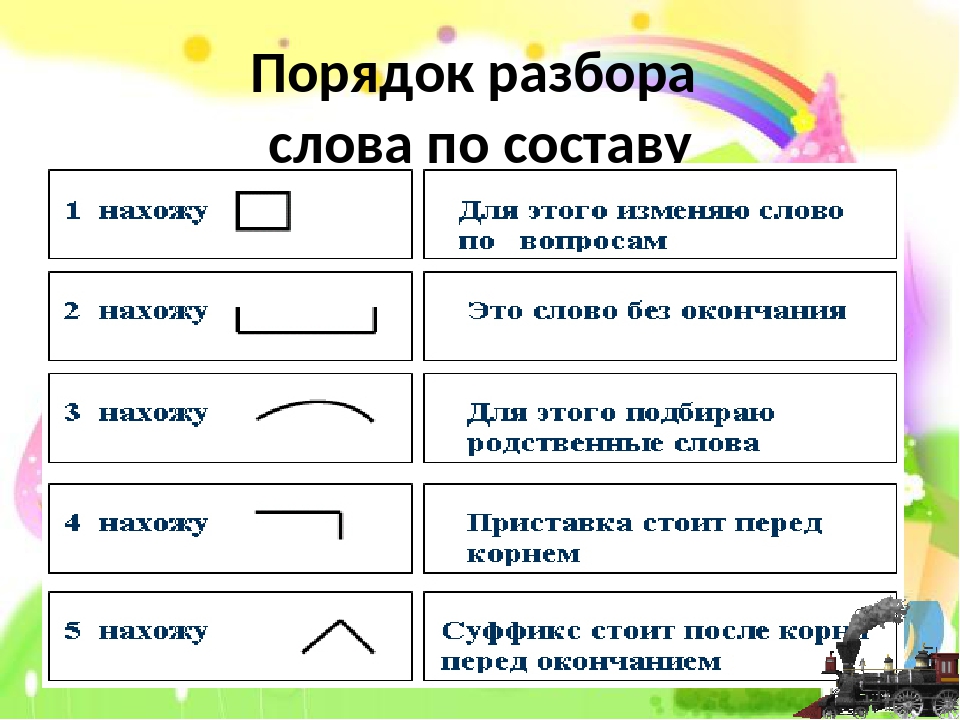 Однако слово «смысл» нередко для ребенка оказывается лишенным определенного содержания. Если же регулярно показывать, что родственные слова соотносятся с одним и тем же словом, у детей сформируется способ (действие), с помощью которого они будут устанавливать наличие или отсутствие родства слов, и в то же время наполнится конкретным содержанием выражение «сходны по смыслу». Возьмем, например, слова зимовать, зимник, зимовье, зимний. Работая с ними, не следует ограничиваться указанием на то, что эти слова имеют общую часть зим- и сходны по смыслу, нужно проанализировать значение каждого из слов, обратившись к мотивирующему: зимовать – проводить зиму, зимник – дорога для езды зимой, зимовье – помещение, где живут зимой, зимний – относящийся к зиме и т.п. Материал, позволяющий учить детей устанавливать смысловые связи между словами, имеется в учебнике. Это упражнения, где сопоставляются подобное слово, то при этом способе приставка будет найдена безошибочно: выехать, заехать, переехать, объехать и т.
Однако слово «смысл» нередко для ребенка оказывается лишенным определенного содержания. Если же регулярно показывать, что родственные слова соотносятся с одним и тем же словом, у детей сформируется способ (действие), с помощью которого они будут устанавливать наличие или отсутствие родства слов, и в то же время наполнится конкретным содержанием выражение «сходны по смыслу». Возьмем, например, слова зимовать, зимник, зимовье, зимний. Работая с ними, не следует ограничиваться указанием на то, что эти слова имеют общую часть зим- и сходны по смыслу, нужно проанализировать значение каждого из слов, обратившись к мотивирующему: зимовать – проводить зиму, зимник – дорога для езды зимой, зимовье – помещение, где живут зимой, зимний – относящийся к зиме и т.п. Материал, позволяющий учить детей устанавливать смысловые связи между словами, имеется в учебнике. Это упражнения, где сопоставляются подобное слово, то при этом способе приставка будет найдена безошибочно: выехать, заехать, переехать, объехать и т. д. Но в словах, о которых говорилось выше, так может быть найдена несуществующая приставка «приез-» или суффикс «ия» в глаголе прошедшего времени и т.п. Вспомним всеобщий способ анализа морфемной структуры слова в лингвистики. Морфема выделяется путем подбора слов, имеющих общий семантический признак и одинаковый по фонемному составу отрезок. Та к, напримет, слово зимний анализиреется в составе трех групп слов: 1-я: зимний, зима, зимушка, зимовье, зимовать, зимовщик и т.д.; 2-я: зимний, теплый, синий, добрый, крепкий и т.д.; 3-я: зимний, умный, летний, пыльный, каменный и т.д. В первый ряд вошли слова, имеющие общую мотивацию: все они объясняются с помощью слова зима. Сравнение буквенного состава слов позволяет выделить общий отрезок зим — — корень. Во втором ряду-слова, имеющие со словом зимний одни и те же грамматические значения; именительный падеж, мужской род, единственное число. Выразителем этих значений служит окончание прилагательных – ий/ый. Если изменить какое-либо из грамматических значений этих слов изменится и буквенный состав окончания.
д. Но в словах, о которых говорилось выше, так может быть найдена несуществующая приставка «приез-» или суффикс «ия» в глаголе прошедшего времени и т.п. Вспомним всеобщий способ анализа морфемной структуры слова в лингвистики. Морфема выделяется путем подбора слов, имеющих общий семантический признак и одинаковый по фонемному составу отрезок. Та к, напримет, слово зимний анализиреется в составе трех групп слов: 1-я: зимний, зима, зимушка, зимовье, зимовать, зимовщик и т.д.; 2-я: зимний, теплый, синий, добрый, крепкий и т.д.; 3-я: зимний, умный, летний, пыльный, каменный и т.д. В первый ряд вошли слова, имеющие общую мотивацию: все они объясняются с помощью слова зима. Сравнение буквенного состава слов позволяет выделить общий отрезок зим — — корень. Во втором ряду-слова, имеющие со словом зимний одни и те же грамматические значения; именительный падеж, мужской род, единственное число. Выразителем этих значений служит окончание прилагательных – ий/ый. Если изменить какое-либо из грамматических значений этих слов изменится и буквенный состав окончания. Наконец, 3 –й ряд. Эти слова обозначают признак, свойственный предмету, названия которого содержится в корне. У всех этих слов есть часть –н-, она находится после корня. Значит, все эти слова образованы с помощью суффикса –н-. Всеобщий способ нахождения в слове морфем, естественно, распространяется на приставки и суффиксы. Отсюда следует, что, проверяя, верно ли выделена приставка или суффикс, нужно подбирать разные слова, имеющие то же дополнительное значение и ту же по фонемному составу часть. Конечно, это не значит, что нельзя использовать подбор однокоренных слов с разными приставками, просто нужно иметь в виду, что этот прием не гарантирует, как и всякий другой частный способ, от ошибок. Всеобщий же способ решения морфемных задач даёт однозначный ответ [11, C. 67]. Кроме того, полезно иметь в виду некоторые особенности приставок и суффиксов, которые подсказывают приемы работы с ними. Так, известно, что приставки как бы «приклеиваются» к слову спереди. Отбрасывая приставку, получаем целое, ни в чем не деформированное слово той же части речи: от глагола – глагол (выбросил — бросил), от прилагательного – прилагательное (подводный — водный) и т.
Наконец, 3 –й ряд. Эти слова обозначают признак, свойственный предмету, названия которого содержится в корне. У всех этих слов есть часть –н-, она находится после корня. Значит, все эти слова образованы с помощью суффикса –н-. Всеобщий способ нахождения в слове морфем, естественно, распространяется на приставки и суффиксы. Отсюда следует, что, проверяя, верно ли выделена приставка или суффикс, нужно подбирать разные слова, имеющие то же дополнительное значение и ту же по фонемному составу часть. Конечно, это не значит, что нельзя использовать подбор однокоренных слов с разными приставками, просто нужно иметь в виду, что этот прием не гарантирует, как и всякий другой частный способ, от ошибок. Всеобщий же способ решения морфемных задач даёт однозначный ответ [11, C. 67]. Кроме того, полезно иметь в виду некоторые особенности приставок и суффиксов, которые подсказывают приемы работы с ними. Так, известно, что приставки как бы «приклеиваются» к слову спереди. Отбрасывая приставку, получаем целое, ни в чем не деформированное слово той же части речи: от глагола – глагол (выбросил — бросил), от прилагательного – прилагательное (подводный — водный) и т. п. Конечно, это не относится к словам, образованным префиксально – суффиксальным способом (подснежник). За то суффиксы часто «переводят» слово из одной части речи в другую: от существительного образуют прилагательное (сон — сонный), от прилагательных – глаголы (белый — белить) и т.п. При чем каждый суффикс сочетается с основой определенного типа. Так, суффикс – тьель- присоединяется к глагольным основам (учить — учитель), а суффикс – щик- к именам существительным (камень-каменщик) и т.п. Подсказывая способы контроля за правильностью выделения приставок и суффиксов, целесообразно обращать внимание детей на эти и другие особенности словообразовательных морфем. С помощью приставок обычно происходит образование новых слов в пределах одной и той же части речи: автор – со-автор., носить – вы-носить, вне-из-вне и т.д. Приставки в русском языке чаще всего используются для словопроизводства глаголов, прилагательных, наречий. Для образования разных форм одного и того же слова пристьавки используются менее активно, чем суффиксы.
п. Конечно, это не относится к словам, образованным префиксально – суффиксальным способом (подснежник). За то суффиксы часто «переводят» слово из одной части речи в другую: от существительного образуют прилагательное (сон — сонный), от прилагательных – глаголы (белый — белить) и т.п. При чем каждый суффикс сочетается с основой определенного типа. Так, суффикс – тьель- присоединяется к глагольным основам (учить — учитель), а суффикс – щик- к именам существительным (камень-каменщик) и т.п. Подсказывая способы контроля за правильностью выделения приставок и суффиксов, целесообразно обращать внимание детей на эти и другие особенности словообразовательных морфем. С помощью приставок обычно происходит образование новых слов в пределах одной и той же части речи: автор – со-автор., носить – вы-носить, вне-из-вне и т.д. Приставки в русском языке чаще всего используются для словопроизводства глаголов, прилагательных, наречий. Для образования разных форм одного и того же слова пристьавки используются менее активно, чем суффиксы. Тем не менее они могут быть и формообразующими: делать – с-делать, бледность – по-бледнеть, слепнуть – о-слепнуть. Приставки русского языка могут присоединяться к словам разных частей речи. Приставкам не свойственна закрепленность за определенными частями речи в связи с большой степенью ответственности и универсальности выражаемых ими значений. Так, приставка со- выражающая значение «совместности», возможна в составе существительных со- товарищ, со-участник; глаголов со-существовать, со-переживать; прилагательных со- звучный, со-предельный и др. Присоединение приставок к основам разных слов не меняет коренным образом их значение. Приставки придают этому значению новые смысловые оттенки. Так, глаголы у-бежать, при-бежать, по существу, обозначают то же действие, что и глагол бежать. Приставки показывают лишь разное направление этого действия. Наречие пре-отлично и прилагательное пре- семпатичный обозначают те же признаки, что и слова отлично и симпатичный, но приставка пре- придает значению данных признаков оттенок высшей степени качества.
Тем не менее они могут быть и формообразующими: делать – с-делать, бледность – по-бледнеть, слепнуть – о-слепнуть. Приставки русского языка могут присоединяться к словам разных частей речи. Приставкам не свойственна закрепленность за определенными частями речи в связи с большой степенью ответственности и универсальности выражаемых ими значений. Так, приставка со- выражающая значение «совместности», возможна в составе существительных со- товарищ, со-участник; глаголов со-существовать, со-переживать; прилагательных со- звучный, со-предельный и др. Присоединение приставок к основам разных слов не меняет коренным образом их значение. Приставки придают этому значению новые смысловые оттенки. Так, глаголы у-бежать, при-бежать, по существу, обозначают то же действие, что и глагол бежать. Приставки показывают лишь разное направление этого действия. Наречие пре-отлично и прилагательное пре- семпатичный обозначают те же признаки, что и слова отлично и симпатичный, но приставка пре- придает значению данных признаков оттенок высшей степени качества. В отличие от приставок суффиксы могут иметь не только широкие и отвлеченные значения, но также и конкретные значения. Суффиксы глаголов и прилагательных отличаются большой широтой и отвлеченностью значения. Так, суффиксы –н-, -ов-, -ск- передают лишь отношение к тому, что обозначено бызовым существительным: книж-н-ый (книга), берез-ов-ый (береза), мор-ск-ой (море). Глагольный суффикс – е- в глаголах типа бел-е-ть, красн-е-ть, имеет широкое значение «становиться, делаться, каким-либо». Суффиксы имен существительных более конкретны, чем у глаголов и прилагатнльных. Они используются для наименования лиц по профессии: столяр, маляр, токарь, пекарь, крановщик; по социальному положению: колхозник, школьник; по качественному признаку: мудрец, гордец, храбрец. Если приставки не имеют закрепленности за определенной частью речи, то суффиксам такая закрепленность свойственна, и они не могут использоваться для образования разных частей речи. С помощью строго определенных суффмксов образуются существительные, прилагательные, глаголы, наречия.
В отличие от приставок суффиксы могут иметь не только широкие и отвлеченные значения, но также и конкретные значения. Суффиксы глаголов и прилагательных отличаются большой широтой и отвлеченностью значения. Так, суффиксы –н-, -ов-, -ск- передают лишь отношение к тому, что обозначено бызовым существительным: книж-н-ый (книга), берез-ов-ый (береза), мор-ск-ой (море). Глагольный суффикс – е- в глаголах типа бел-е-ть, красн-е-ть, имеет широкое значение «становиться, делаться, каким-либо». Суффиксы имен существительных более конкретны, чем у глаголов и прилагатнльных. Они используются для наименования лиц по профессии: столяр, маляр, токарь, пекарь, крановщик; по социальному положению: колхозник, школьник; по качественному признаку: мудрец, гордец, храбрец. Если приставки не имеют закрепленности за определенной частью речи, то суффиксам такая закрепленность свойственна, и они не могут использоваться для образования разных частей речи. С помощью строго определенных суффмксов образуются существительные, прилагательные, глаголы, наречия. Так суффикс –ец- употребляется для образования существительных, суффикс –и- только для образования глаголов (пилить, сулить), суффикс –чив- только для образования прилагательных (разборчивый, настойчивый). В некоторых словах суффиксы не получают своего материального выражения. В этом случае принято говорить о наличии в структуре данных словами. Во 2 классе школьники учат: «Окончание служит для связи слов в предложении». Но в сознании детей в этот период понятие связи слов не выходит за рамки семантических связей, в то время как понятие грамматической связи имеет свое специфическое содержание, которое и 0 0 1 Fдолжно быть раскрыто при анализе слово сочетаний. Например, в словосочетании читает книгу слово, называющее действие, может изменяться «как хочет»: читал книгу, читаю книгу, читаем книгу и т. п., а второе слово ему «подчиняется», выступая в форме определенного падежа: сказать «читает книгой» или «читаю книга» нельзя. И это можно показать детям. Таким образом, даже на самом начальном этапе знакомства с окончанием без употребления каких бы то ни было терминов можно раскрыть роль этой части слова как средства выражения особых, 0 0 1 Fфор мальных (грамматических) связей между словами.
Так суффикс –ец- употребляется для образования существительных, суффикс –и- только для образования глаголов (пилить, сулить), суффикс –чив- только для образования прилагательных (разборчивый, настойчивый). В некоторых словах суффиксы не получают своего материального выражения. В этом случае принято говорить о наличии в структуре данных словами. Во 2 классе школьники учат: «Окончание служит для связи слов в предложении». Но в сознании детей в этот период понятие связи слов не выходит за рамки семантических связей, в то время как понятие грамматической связи имеет свое специфическое содержание, которое и 0 0 1 Fдолжно быть раскрыто при анализе слово сочетаний. Например, в словосочетании читает книгу слово, называющее действие, может изменяться «как хочет»: читал книгу, читаю книгу, читаем книгу и т. п., а второе слово ему «подчиняется», выступая в форме определенного падежа: сказать «читает книгой» или «читаю книга» нельзя. И это можно показать детям. Таким образом, даже на самом начальном этапе знакомства с окончанием без употребления каких бы то ни было терминов можно раскрыть роль этой части слова как средства выражения особых, 0 0 1 Fфор мальных (грамматических) связей между словами. По мере накопления знаний о частях речи углубляются знания 0 0 1 Fучащихся об окончании. В то же время конкретизируются пред ставления о связях между словами и формируется всеобщий способ нахождения в слове этой морфемы: 0 0 1 Fа) изменяется конкрет ное грамматическое значение слова; б) сравниваются исходная и полученная формы слова; в) находится изменившаяся часть. Например, изучается род имен прилагательных. Изменяем 0 0 1 Fпри лагательное по роду: добрый (человек), доброе (дело), добрая (девочка). 0 0 1 FСравниваем полученные словоформы: добрый — доб рое — добрая. Отделяем изменяющиеся части: -ый, -ое, -ая. Это и есть окончание, которое говорит, какого рода прилагательное. Даже если не известно, какой признак называет прилагательное, а известно только, какое у него окончание, мы уже можем об этом прилагательном кое-что сказать. Так, если известно, что у данного прилагательного окончание -ое, то можно сказать, что оно связано с 0 0 1 Fсуществительным среднего рода. И чем больше грамма тических сведений о данной части речи накопит учащийся, тем больше сведений о слове будет 0 0 1 Fсообщать ему окончание: оконча ние -ое сообщит не только о роде данного прилагательного, но и о его числе и падеже.
По мере накопления знаний о частях речи углубляются знания 0 0 1 Fучащихся об окончании. В то же время конкретизируются пред ставления о связях между словами и формируется всеобщий способ нахождения в слове этой морфемы: 0 0 1 Fа) изменяется конкрет ное грамматическое значение слова; б) сравниваются исходная и полученная формы слова; в) находится изменившаяся часть. Например, изучается род имен прилагательных. Изменяем 0 0 1 Fпри лагательное по роду: добрый (человек), доброе (дело), добрая (девочка). 0 0 1 FСравниваем полученные словоформы: добрый — доб рое — добрая. Отделяем изменяющиеся части: -ый, -ое, -ая. Это и есть окончание, которое говорит, какого рода прилагательное. Даже если не известно, какой признак называет прилагательное, а известно только, какое у него окончание, мы уже можем об этом прилагательном кое-что сказать. Так, если известно, что у данного прилагательного окончание -ое, то можно сказать, что оно связано с 0 0 1 Fсуществительным среднего рода. И чем больше грамма тических сведений о данной части речи накопит учащийся, тем больше сведений о слове будет 0 0 1 Fсообщать ему окончание: оконча ние -ое сообщит не только о роде данного прилагательного, но и о его числе и падеже. В то же время будет конкретизироваться общее представление об окончании как двусторонней языковой единице, в которой неразрывно связано ее значение с определенным фонемным (звуковым) составом. Например, окончание – ая говорит о том, что это прилагательное женского рода единственного числа именительного падежа. А окончание – ого того же прилагательного отличается от первого не только по звуковому составу, но и по значению: -ого указывает на мужской или средний род, родительный и винительный падеж единственного числа. Чем содержательнее становится понятие окончания как морфемы, выражающей грамматические значения слова, тем легче учащимся различать слова и словоформы. Появляется формальный признак, опираясь на который можно безошибочно отличать словоформы от разных слов: в слове изменилось только окончание – слово осталось тем же; произошли изменения в той части слова, которая находится перед окончание, — появилось другое слово. Важно, что признак этот действует и тогда, когда значения двух или нескольких слов практически идентичны.
В то же время будет конкретизироваться общее представление об окончании как двусторонней языковой единице, в которой неразрывно связано ее значение с определенным фонемным (звуковым) составом. Например, окончание – ая говорит о том, что это прилагательное женского рода единственного числа именительного падежа. А окончание – ого того же прилагательного отличается от первого не только по звуковому составу, но и по значению: -ого указывает на мужской или средний род, родительный и винительный падеж единственного числа. Чем содержательнее становится понятие окончания как морфемы, выражающей грамматические значения слова, тем легче учащимся различать слова и словоформы. Появляется формальный признак, опираясь на который можно безошибочно отличать словоформы от разных слов: в слове изменилось только окончание – слово осталось тем же; произошли изменения в той части слова, которая находится перед окончание, — появилось другое слово. Важно, что признак этот действует и тогда, когда значения двух или нескольких слов практически идентичны. Например, слова рыбочка и рыбонька, стирать и стирка обозначают одно и то же, но поскольку в той части, которая находится перед окончанием, есть различие, значит, это разные слова. Всеми свойствами обычных окончаний характеризуются и так называемые нулевые окончания. О нулевом окончании говорят, когда грамматическое значение есть, а фонемы, которая бы его выражала, нет. Например, в именительном падеже у существительных 2-го склонения окончание нулевое: стол . А другие падежные окончания выражены звуками: стол-а, стол-у и т.д. на уроках же в начальных классах можно слышать, что стол – слово без окончания. В последствии эта «мелочь» оборачивается тем, что ученик средних классов не отличает слова действительно без окончаний, например, наречия, от слов, которые в одной из своих форм имеют нулевое окончание. Поскольку знакомство с нулевыми окончаниями не предусмотрено действующей программой для начальных классов, учитель должен проявить некоторую изобретательность, чтобы не нарушить принцип научности и не вынуждать детей со временем переучиваться.
Например, слова рыбочка и рыбонька, стирать и стирка обозначают одно и то же, но поскольку в той части, которая находится перед окончанием, есть различие, значит, это разные слова. Всеми свойствами обычных окончаний характеризуются и так называемые нулевые окончания. О нулевом окончании говорят, когда грамматическое значение есть, а фонемы, которая бы его выражала, нет. Например, в именительном падеже у существительных 2-го склонения окончание нулевое: стол . А другие падежные окончания выражены звуками: стол-а, стол-у и т.д. на уроках же в начальных классах можно слышать, что стол – слово без окончания. В последствии эта «мелочь» оборачивается тем, что ученик средних классов не отличает слова действительно без окончаний, например, наречия, от слов, которые в одной из своих форм имеют нулевое окончание. Поскольку знакомство с нулевыми окончаниями не предусмотрено действующей программой для начальных классов, учитель должен проявить некоторую изобретательность, чтобы не нарушить принцип научности и не вынуждать детей со временем переучиваться. Можно, например, воспользоваться какой-нибудь описательной, метафорической конструкцией: «В этом падеже у существительного беззвучное, немое окончание, окончание-неведимка» и т.п.[2, C. 207]. Постфиксом называется значимая часть слова, находящаяся после окончания или суффиксов в глагольных формах и служащая для образования новых слов либо разных форм одного и того же слова. В качестве постфикса в русском языке используется единственная служебная морфема –ся (-сь): катал ся, каталась. Постфикс –ся (сь) употребляется также при образовании формы страдательного залога глаголов: читать — читается, строить – строится и т.д. Постфикс –ся употребляется в структуре причастий, а так же в других глагольных формах, где ему предшествует согласный звук. После гласных звуков во всех глагольных формах, кроме причастий, употребляется – сь. Морфемы в структуре слова следуют друг за другом в строго определенном порядке перемещаться, как правило, не могут [2, С. 301]. Соединительные гласные о/е являются служебными морфемами, которые используются для образования сложных слов путем объединения основ двух слов.
Можно, например, воспользоваться какой-нибудь описательной, метафорической конструкцией: «В этом падеже у существительного беззвучное, немое окончание, окончание-неведимка» и т.п.[2, C. 207]. Постфиксом называется значимая часть слова, находящаяся после окончания или суффиксов в глагольных формах и служащая для образования новых слов либо разных форм одного и того же слова. В качестве постфикса в русском языке используется единственная служебная морфема –ся (-сь): катал ся, каталась. Постфикс –ся (сь) употребляется также при образовании формы страдательного залога глаголов: читать — читается, строить – строится и т.д. Постфикс –ся употребляется в структуре причастий, а так же в других глагольных формах, где ему предшествует согласный звук. После гласных звуков во всех глагольных формах, кроме причастий, употребляется – сь. Морфемы в структуре слова следуют друг за другом в строго определенном порядке перемещаться, как правило, не могут [2, С. 301]. Соединительные гласные о/е являются служебными морфемами, которые используются для образования сложных слов путем объединения основ двух слов. Словообразовательным значением морфем о/е «является соединительное значение, сводящееся к объединению значений, составляющих сложную основу мотивирующих слов в одно целостное сложное значение.» При образовании сложного слова соединительная гласная, находящаяся между основами двух слов, нейтрализует грамматическое значение первого из них и тем самым создает возможность для соединения в одно слово двух различных в грамматическом отношении слов, например: огн-е-упорн-ый. грамматическое значение. Лексическое значение слова «создается» путем взаимодействия и слияний в единое целое значений, присущих отдельным морфемам, составляющим данное слово. Поскольку слияние морфем представляет собой не механическое соединение, а взаимодействие и, кроме того, многие префиксы, корни, суффиксы многозначны, то только по морфемному составу трудно (а иногда и невозможно) определить лексическое значение слова. Тем не менее, лексическое значение многих мотивированных слов определяется его морфемным составом (например, последователь, разведчик, сотрудник, прибрежный, прилуниться и т.
Словообразовательным значением морфем о/е «является соединительное значение, сводящееся к объединению значений, составляющих сложную основу мотивирующих слов в одно целостное сложное значение.» При образовании сложного слова соединительная гласная, находящаяся между основами двух слов, нейтрализует грамматическое значение первого из них и тем самым создает возможность для соединения в одно слово двух различных в грамматическом отношении слов, например: огн-е-упорн-ый. грамматическое значение. Лексическое значение слова «создается» путем взаимодействия и слияний в единое целое значений, присущих отдельным морфемам, составляющим данное слово. Поскольку слияние морфем представляет собой не механическое соединение, а взаимодействие и, кроме того, многие префиксы, корни, суффиксы многозначны, то только по морфемному составу трудно (а иногда и невозможно) определить лексическое значение слова. Тем не менее, лексическое значение многих мотивированных слов определяется его морфемным составом (например, последователь, разведчик, сотрудник, прибрежный, прилуниться и т. д.). Особая роль принадлежит корню как смысловому ядру, создающему семантическую общноть однокоренных слов. Указанная особенность языка является одной из причинг, обусловливающих возможность использования членения слова на морфемы в целях выяснения его смысла. Этой возможностью учащиеся начинают осознанно пользоваться по мере усвоения морфемного состава слов и их образования. Лексическое значение многих производных слов осознается учащимися, когда им «открываются» тайны той связи, на которой основано семантическое родство слов. Итак, значение работы над морфемным составом слов состоит, во- первых, в том, что школьники овладевают одним из ведущих способов раскрытия лексического значения слов. Отсюда вытекает задача учителя – создать оптимальные условия для осознания детьми взаимосвязи, существующей в языке между лексическим значением слова и его морфемным составом, целенаправленно руководить на этой основе уточнением словаря учащихся. Во-вторых, даже элементарные знания об образовании слов очень важны для понимания учащимися основного источника пополнения нашего языка новыми словами, как представлено в трудах многих известных лингвистов (Л.
д.). Особая роль принадлежит корню как смысловому ядру, создающему семантическую общноть однокоренных слов. Указанная особенность языка является одной из причинг, обусловливающих возможность использования членения слова на морфемы в целях выяснения его смысла. Этой возможностью учащиеся начинают осознанно пользоваться по мере усвоения морфемного состава слов и их образования. Лексическое значение многих производных слов осознается учащимися, когда им «открываются» тайны той связи, на которой основано семантическое родство слов. Итак, значение работы над морфемным составом слов состоит, во- первых, в том, что школьники овладевают одним из ведущих способов раскрытия лексического значения слов. Отсюда вытекает задача учителя – создать оптимальные условия для осознания детьми взаимосвязи, существующей в языке между лексическим значением слова и его морфемным составом, целенаправленно руководить на этой основе уточнением словаря учащихся. Во-вторых, даже элементарные знания об образовании слов очень важны для понимания учащимися основного источника пополнения нашего языка новыми словами, как представлено в трудах многих известных лингвистов (Л. А. Булаховский, В.В. Виноградов, Е.М. Галкин-Федорук, Е.А. Земская, Н.М. Шанский и др.), новые слова создаются из тех морфем, из того строительного материала, который уже существует в языке, и по тем моделям, которые исторически сложились и закрепились в системе русского словообразования. Наблюдения над образованием слов оказывают положительное влияние на формирование у учащихся активного отношения к слову, подводят к пониманию закономерности развития языка. В-третьих, ознакомление с основами словообразования способствует обогащению знаний школьников об окружающей их действительности. Слова опосредованно (через понятия) соотносятся с предметами, процессами, явлениями. Установление семантико-структурной связи между словами опирается на связь между соотносительными понятиями (например, слова граница и пограничник семантически и структурно связаны, так как они являются наименованиями соотносимых между собой понятий). Фактически познание школьниками семантико-структурной соотносимости слов означает углубление их представлений о связях между предметами, процессами, имеющих место в окружающей жизни.
А. Булаховский, В.В. Виноградов, Е.М. Галкин-Федорук, Е.А. Земская, Н.М. Шанский и др.), новые слова создаются из тех морфем, из того строительного материала, который уже существует в языке, и по тем моделям, которые исторически сложились и закрепились в системе русского словообразования. Наблюдения над образованием слов оказывают положительное влияние на формирование у учащихся активного отношения к слову, подводят к пониманию закономерности развития языка. В-третьих, ознакомление с основами словообразования способствует обогащению знаний школьников об окружающей их действительности. Слова опосредованно (через понятия) соотносятся с предметами, процессами, явлениями. Установление семантико-структурной связи между словами опирается на связь между соотносительными понятиями (например, слова граница и пограничник семантически и структурно связаны, так как они являются наименованиями соотносимых между собой понятий). Фактически познание школьниками семантико-структурной соотносимости слов означает углубление их представлений о связях между предметами, процессами, имеющих место в окружающей жизни. В-четвертых, осознание роли морфем в слове, а также семантического значения приставок и суффиксов содействует формированию у школьников точности речи. Задача учителя – максимально способствовать не только пониманию учащимися лексического значения слова, но и развитию осознанного употребления в контексте слов с определенными приставками и суффиксами. В-пятых, изучение морфемного состава слова имеет большое значение для формирования орфографических навыков. Обусловлено это тем, что ведущим принципом русского правописания является морфологический. Формирование навыков правописания корня, приставок, суффиксов и окончаний на теоретической основе (а только такое письмо может быть сознательным) требует целенаправленного применения фонетических, словообразовательных и грамматических знаний. Поэтому одной из важных задач изучения морфемного состава слова является создание основы знаний и умений, необходимых для формирования навыков правописания морфем слова, и, прежде всего, корня. Наконец, немаловажен и тот факт, что изучение морфемного состава слова заключает в себе большие возможности для развития умственных способностей учащихся, в частности, для формирования у них специфических умственных умений, без которых невозможно сознательное владение словом как языковой единицей, например, умения абстрагировать семантическое значение корня, приставки и суффикса от лексического значения слова, умения вычленять в слове значимые части (морфемы), умения сравнивать слова в целях установления их семантико-структурной общности или различия и т.
В-четвертых, осознание роли морфем в слове, а также семантического значения приставок и суффиксов содействует формированию у школьников точности речи. Задача учителя – максимально способствовать не только пониманию учащимися лексического значения слова, но и развитию осознанного употребления в контексте слов с определенными приставками и суффиксами. В-пятых, изучение морфемного состава слова имеет большое значение для формирования орфографических навыков. Обусловлено это тем, что ведущим принципом русского правописания является морфологический. Формирование навыков правописания корня, приставок, суффиксов и окончаний на теоретической основе (а только такое письмо может быть сознательным) требует целенаправленного применения фонетических, словообразовательных и грамматических знаний. Поэтому одной из важных задач изучения морфемного состава слова является создание основы знаний и умений, необходимых для формирования навыков правописания морфем слова, и, прежде всего, корня. Наконец, немаловажен и тот факт, что изучение морфемного состава слова заключает в себе большие возможности для развития умственных способностей учащихся, в частности, для формирования у них специфических умственных умений, без которых невозможно сознательное владение словом как языковой единицей, например, умения абстрагировать семантическое значение корня, приставки и суффикса от лексического значения слова, умения вычленять в слове значимые части (морфемы), умения сравнивать слова в целях установления их семантико-структурной общности или различия и т. д. Задача учителя – создать в учебном процессе такие условия, при которых усвоение знаний сочетается с формированием адекватных им умственных действий. В настоящее время, согласно утвержденным программам для 4-летней начальной школы, морфемный состав слова изучается во 2-м и 3-м классах. По мнению методистов и учителей, изучение морфемной структуры слов имеет исключительно важное значение в развитии лингвистических способностей детей и их общем развитии. Невозможно переоценить роль понимания структуры слова в обучении чтению и правописанию. Прежде всего мы узнаем слова при чтении и воссоздаем при письме по их значимым частям – морфемам. Кроме того, изучение состава слова заключает в себе богатейшие возможности для развития интереса детей к миру языка. С восхищением слушают младшие школьники «слово о словах», они искренне удивляются тому, что кто-то не понял, почему словом леонить стали обозначать движения человека в открытом космосе; они хотят знать, что значит и как возникло слово перестройка и т.
д. Задача учителя – создать в учебном процессе такие условия, при которых усвоение знаний сочетается с формированием адекватных им умственных действий. В настоящее время, согласно утвержденным программам для 4-летней начальной школы, морфемный состав слова изучается во 2-м и 3-м классах. По мнению методистов и учителей, изучение морфемной структуры слов имеет исключительно важное значение в развитии лингвистических способностей детей и их общем развитии. Невозможно переоценить роль понимания структуры слова в обучении чтению и правописанию. Прежде всего мы узнаем слова при чтении и воссоздаем при письме по их значимым частям – морфемам. Кроме того, изучение состава слова заключает в себе богатейшие возможности для развития интереса детей к миру языка. С восхищением слушают младшие школьники «слово о словах», они искренне удивляются тому, что кто-то не понял, почему словом леонить стали обозначать движения человека в открытом космосе; они хотят знать, что значит и как возникло слово перестройка и т.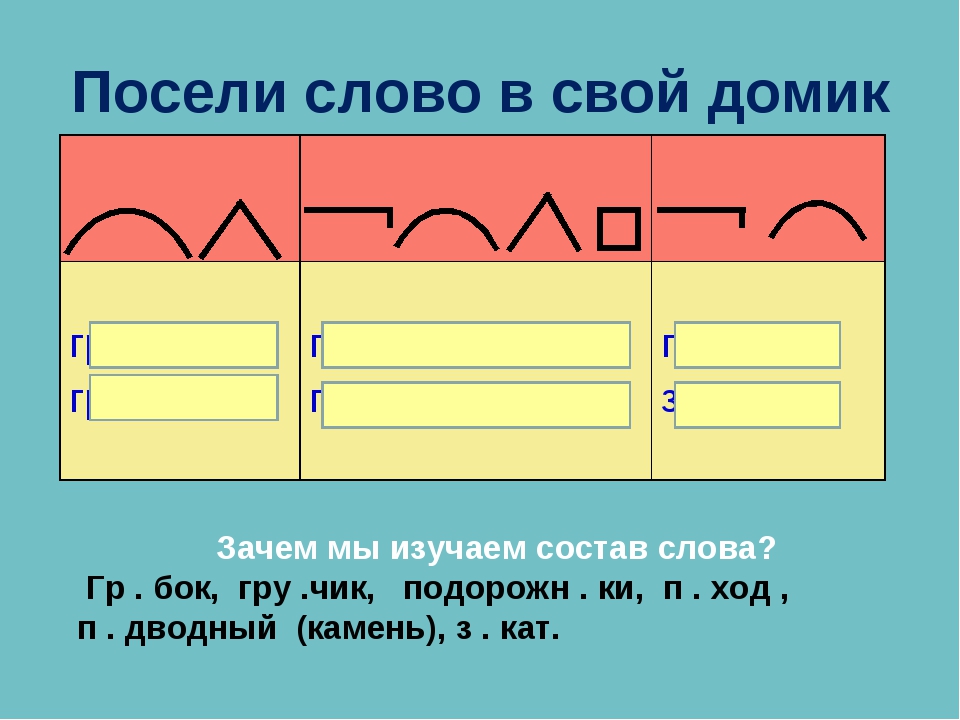 д. Выяснение того, как сделаны слова в русском языке и как они делаются, способствует возникновению мотивации, необходимой для успешного овладения речевой деятельностью, развивает в детях потребность в повышении своей языковой культуры, стремление наиболее точно выразить мысль в слове [7, C. 506]. Особенно, естественно, это заметно на начальном этапе, когда младшие школьники еще не знают всех изменений основных частей речи. Большие затруднения испытывают учащиеся при разборе слов по составу, если у них плохая фонематическая подготовка, а также если они не понимают особенностей русской графики. Так, если школьник не осознает, что в словах рука и земля одно и то же окончание [а], которое после твердого и мягкого согласного передается разными буквами, у него так и не возникает представления о существительных одного склонения как ос словах, имеющих один и тот же набор окончаний. И значит, он будет затрудняться при проверке безударных падежных окончаний по ударным. Источником ошибок довольно часто служит «замаскированная» морфема.
д. Выяснение того, как сделаны слова в русском языке и как они делаются, способствует возникновению мотивации, необходимой для успешного овладения речевой деятельностью, развивает в детях потребность в повышении своей языковой культуры, стремление наиболее точно выразить мысль в слове [7, C. 506]. Особенно, естественно, это заметно на начальном этапе, когда младшие школьники еще не знают всех изменений основных частей речи. Большие затруднения испытывают учащиеся при разборе слов по составу, если у них плохая фонематическая подготовка, а также если они не понимают особенностей русской графики. Так, если школьник не осознает, что в словах рука и земля одно и то же окончание [а], которое после твердого и мягкого согласного передается разными буквами, у него так и не возникает представления о существительных одного склонения как ос словах, имеющих один и тот же набор окончаний. И значит, он будет затрудняться при проверке безударных падежных окончаний по ударным. Источником ошибок довольно часто служит «замаскированная» морфема. Мы имеем в виду в первую очередь своеобразие передачи при письме звука [й]. если младший школьник не понимает, что буква ю в глаголе читаю обозначает не только окончание [у], но и звук [й], который не входит в окончание, то позже, в средних классах, ему уже не понять, как образуются глаголы повелительного наклонения и т.д. и т.п. Разбор слов по составу представляет определенные трудности не только для детей, но и для учителей. На морфемном уровне активнее, чем на других языковых ярусах (например, в морфологии), происходят различные изменения: состав слова упрощается, усложняется и т.п. То, что считалось бесспорным вчера, сегодня подвергается коррекции. Так, например, учителя старшего поколения с трудом склоняются признать, что в слове прекрасный всего две морфемы: корень и окончание (прекрасн-ый), а слова плот и плотник относятся к разнокоренным и т.п. Без систематического обращения к справочной литературе в работе по составу слова учителю не обойтись. Чтобы правильно вести работу по морфемике, учителю необходимо постоянно иметь в виду некоторые важные языковые закономерности.
Мы имеем в виду в первую очередь своеобразие передачи при письме звука [й]. если младший школьник не понимает, что буква ю в глаголе читаю обозначает не только окончание [у], но и звук [й], который не входит в окончание, то позже, в средних классах, ему уже не понять, как образуются глаголы повелительного наклонения и т.д. и т.п. Разбор слов по составу представляет определенные трудности не только для детей, но и для учителей. На морфемном уровне активнее, чем на других языковых ярусах (например, в морфологии), происходят различные изменения: состав слова упрощается, усложняется и т.п. То, что считалось бесспорным вчера, сегодня подвергается коррекции. Так, например, учителя старшего поколения с трудом склоняются признать, что в слове прекрасный всего две морфемы: корень и окончание (прекрасн-ый), а слова плот и плотник относятся к разнокоренным и т.п. Без систематического обращения к справочной литературе в работе по составу слова учителю не обойтись. Чтобы правильно вести работу по морфемике, учителю необходимо постоянно иметь в виду некоторые важные языковые закономерности. Морфема – это минимальная значимая часть слова, которая, как и всякая языковая единица, имеет две неразрывно связанные между собой стороны: внешнюю (звуковой состав) и внутреннюю (значение). Морфема выделяется в ряду слов, имеющих сходство по указанным двум признакам: общность в значении и фонемном составе. Например, слова волчонок, медвежонок, козленок имеют одинаковую часть – онок (-енок) и обозначают детенышей животных. Если же мы включим в тот же ряд слова кружок, сахарок, басок и т.п. на том основании, что в них исчезнет второй необходимый признак – общее в значении: о последних трех словах никак нельзя сказать, что они обозначают детенышей. Следовательно, часть –онок не делится на более мелкие отрезки и представляет собой один суффикс[10, С. 111]. Умение устанавливать тождество морфем необходимо для определения сильной позиции фонемы в конкретной морфеме, то есть является обязательным условием правильного решения орфографических задач. Однако установить, действительно ли данные слова (два или больше) имеют в своем составе одну и ту же морфему, далеко не всегда просто.
Морфема – это минимальная значимая часть слова, которая, как и всякая языковая единица, имеет две неразрывно связанные между собой стороны: внешнюю (звуковой состав) и внутреннюю (значение). Морфема выделяется в ряду слов, имеющих сходство по указанным двум признакам: общность в значении и фонемном составе. Например, слова волчонок, медвежонок, козленок имеют одинаковую часть – онок (-енок) и обозначают детенышей животных. Если же мы включим в тот же ряд слова кружок, сахарок, басок и т.п. на том основании, что в них исчезнет второй необходимый признак – общее в значении: о последних трех словах никак нельзя сказать, что они обозначают детенышей. Следовательно, часть –онок не делится на более мелкие отрезки и представляет собой один суффикс[10, С. 111]. Умение устанавливать тождество морфем необходимо для определения сильной позиции фонемы в конкретной морфеме, то есть является обязательным условием правильного решения орфографических задач. Однако установить, действительно ли данные слова (два или больше) имеют в своем составе одну и ту же морфему, далеко не всегда просто. Дело в том, что между морфемами существуют такие же многообразные связи, как и между целыми словами: синонимия, амонимия и т.д. Причем это относится не только к корню, но в равной степени и к аффиксам. Например, корни слов погас и потух – синонимы, то же можно сказать о суффиксах в словах, обозначающих, например, самок животных: -иц- (тигрица), -их- (слониха), -к- (голубка) и т.п. Омонимичными являются корни слов нос и носит, суффиксы в словах чайник и печник, окончания существительных первого склонения в именительном падеже и второго склонения в родительном: рука – стола, окончания –и в трех падежах существительных третьего склонения: тени, приставки в словах закричал – завернул и т.п. Необходимо четко разграничивать один и тот же корень (приставку, суффикс, окончание) и разные корни (приставки, суффиксы, окончания), которые совпали по звуковому (фонемному) составу. Или, напротив, при разном звучании имеют одно только значение. Таким образом, говорить о такой же морфеме можно при совпадении обоих ее признаков.
Дело в том, что между морфемами существуют такие же многообразные связи, как и между целыми словами: синонимия, амонимия и т.д. Причем это относится не только к корню, но в равной степени и к аффиксам. Например, корни слов погас и потух – синонимы, то же можно сказать о суффиксах в словах, обозначающих, например, самок животных: -иц- (тигрица), -их- (слониха), -к- (голубка) и т.п. Омонимичными являются корни слов нос и носит, суффиксы в словах чайник и печник, окончания существительных первого склонения в именительном падеже и второго склонения в родительном: рука – стола, окончания –и в трех падежах существительных третьего склонения: тени, приставки в словах закричал – завернул и т.п. Необходимо четко разграничивать один и тот же корень (приставку, суффикс, окончание) и разные корни (приставки, суффиксы, окончания), которые совпали по звуковому (фонемному) составу. Или, напротив, при разном звучании имеют одно только значение. Таким образом, говорить о такой же морфеме можно при совпадении обоих ее признаков. Постоянное внимание учителя к тому, что в нашем языке возможны морфемы – синонимы, амонимичные значимые части и т.п., создает у учащихся представление о неисчерпаемом багаже языка, его безграничных возможностях для выражения всех оттенков мысли. Однако нельзя забывать, что почти каждая морфема имеет свои разновидности, связанные с небольшими различиями в ее фонетическом составе. Конкретные варианты, которыми представлена морфема в речи, называют морфами. Морфы каждой морфемы чередуются в зависимости от грамматической позиции: ходить, но хожу; бродить, но брожу и т.п., то есть перед –ить корень кончается на д, а перед окончанием первого лица д заменяется на ж и т.д. «Чередуются морфы по приказанию следующей морфемы, грамматической единицы. Позиционно чередующиеся морфы, грамматической единицы. Позиционно чередующиеся морфы объединяются в одну морфему. Так, например, морфы ход- и хож- представляют одну и ту же морфему, один и тот же корень» [18, С. 178]. Программа младших классов не предусматривает знакомства учащихся с рассмотренными закономерностями.
Постоянное внимание учителя к тому, что в нашем языке возможны морфемы – синонимы, амонимичные значимые части и т.п., создает у учащихся представление о неисчерпаемом багаже языка, его безграничных возможностях для выражения всех оттенков мысли. Однако нельзя забывать, что почти каждая морфема имеет свои разновидности, связанные с небольшими различиями в ее фонетическом составе. Конкретные варианты, которыми представлена морфема в речи, называют морфами. Морфы каждой морфемы чередуются в зависимости от грамматической позиции: ходить, но хожу; бродить, но брожу и т.п., то есть перед –ить корень кончается на д, а перед окончанием первого лица д заменяется на ж и т.д. «Чередуются морфы по приказанию следующей морфемы, грамматической единицы. Позиционно чередующиеся морфы, грамматической единицы. Позиционно чередующиеся морфы объединяются в одну морфему. Так, например, морфы ход- и хож- представляют одну и ту же морфему, один и тот же корень» [18, С. 178]. Программа младших классов не предусматривает знакомства учащихся с рассмотренными закономерностями. Однако важно постоянно иметь их в виду. И если ученики составили группу однокоренных слов снег, снежок, снеговик, снежный, то учитель, уточняя ответы детей, должен сказать: «Эти слова имеют корень снег- (снеж-)». Обойти явление чередования фонем в морфемах даже на начальном этапе изучения состава слова невозможно, так как ему подвержено подавляющее число слов в русском языке. А от более сложных процессов, происходящих в морфемной структуре слов, желательно оградить младших школьников. Имеется в виду явление опрощения и связанные корни. Напомним, что в отличие от свободных корней, которые имеют ясно выраженное лексическое значение, в связанных корнях вещественное значение не поддается объяснению с точки зрения современного языка. Например, что обозначает корень –ня- в словах занять, перенять, отнять и т.п? А корень –ул- в словах улица, переулок, закоулок? Для младших школьников, которые стремятся мыслить конкретно, работа с такими словами затруднительна [11, С. 105]. конечной согласной корня в этих словах.
Однако важно постоянно иметь их в виду. И если ученики составили группу однокоренных слов снег, снежок, снеговик, снежный, то учитель, уточняя ответы детей, должен сказать: «Эти слова имеют корень снег- (снеж-)». Обойти явление чередования фонем в морфемах даже на начальном этапе изучения состава слова невозможно, так как ему подвержено подавляющее число слов в русском языке. А от более сложных процессов, происходящих в морфемной структуре слов, желательно оградить младших школьников. Имеется в виду явление опрощения и связанные корни. Напомним, что в отличие от свободных корней, которые имеют ясно выраженное лексическое значение, в связанных корнях вещественное значение не поддается объяснению с точки зрения современного языка. Например, что обозначает корень –ня- в словах занять, перенять, отнять и т.п? А корень –ул- в словах улица, переулок, закоулок? Для младших школьников, которые стремятся мыслить конкретно, работа с такими словами затруднительна [11, С. 105]. конечной согласной корня в этих словах. Обращается внимание учащихся и на озвончение согласных в середине или оглушение в конце таких слов, как «косьба», «кот» и т.п. [12, С. 143]. Морфемный анализ поддерживает работу над частями речи. Так, еще до изучения склонения имен существительных, прилагательных учащиеся усваивают характерные для этих частей речи окончания (-а, -я, -ая, — яя, -ую, — юю), отдельные суффиксы (-к- травка, канавка, -н- длинный и т.п.). правописание окончаний целесообразно связывать с синтаксическим разбором. Вот почему, планируя материал программы по грамматике, нельзя брать разделы программы последовательно один за другим: «Звуки и буквы», «Слово», «Предложение», «Связная речь». Материал по грамматике, правописанию и развитию речи в начальных классах планируется с таким расчетом, чтобы разные стороны языка выступали на каждом отдельном уроке во взаимосвязи. При этом очень важно учитывать различные стороны речевой культуры учащихся: правильное орфоэпическое произношение, правильное ударение, внимание, внимание к значению слова, умение выбрать нужное слово, правильно и точно отражающую мысль, правильное построение предложений и умение правильно пользоваться монологической речью.
Обращается внимание учащихся и на озвончение согласных в середине или оглушение в конце таких слов, как «косьба», «кот» и т.п. [12, С. 143]. Морфемный анализ поддерживает работу над частями речи. Так, еще до изучения склонения имен существительных, прилагательных учащиеся усваивают характерные для этих частей речи окончания (-а, -я, -ая, — яя, -ую, — юю), отдельные суффиксы (-к- травка, канавка, -н- длинный и т.п.). правописание окончаний целесообразно связывать с синтаксическим разбором. Вот почему, планируя материал программы по грамматике, нельзя брать разделы программы последовательно один за другим: «Звуки и буквы», «Слово», «Предложение», «Связная речь». Материал по грамматике, правописанию и развитию речи в начальных классах планируется с таким расчетом, чтобы разные стороны языка выступали на каждом отдельном уроке во взаимосвязи. При этом очень важно учитывать различные стороны речевой культуры учащихся: правильное орфоэпическое произношение, правильное ударение, внимание, внимание к значению слова, умение выбрать нужное слово, правильно и точно отражающую мысль, правильное построение предложений и умение правильно пользоваться монологической речью.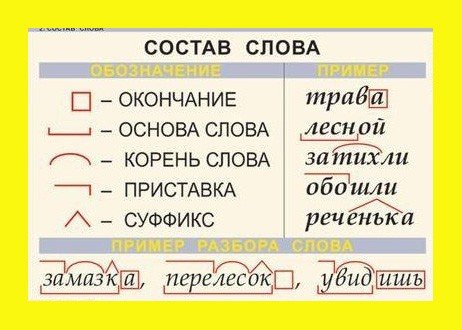 Чтобы обеспечить все перечисленные требования, учитель на каждом уроке русского языка занимается разными сторонами языка. Материал же программы распределяют по учебным четвертям так, чтобы обеспечить возможность разностороннего изучения языка, повторение и взаимосвязь грамматической теории и языковой практики. Таким образом, все сказанное об особенностях планирования по грамматике и правописанию не исключает необходимости выделять центральные, основные темы для работы над ними в определенный период учебного времени. Такие центральные, основные темы имеются в программе каждого их трех начальных классов. Так, например, центральным разделом программы первого класса является раздел «Звуки и буквы». Во втором классе таким центральным, основным разделом является раздел «Слово». В третьем классе главное внимание учащихся на уроках русского языка сосредотачивается на изменение слов в предложениях. Поэтому здесь центральным, основным разделов является изменение и связь слов. 3. Методы и приемы изучения состава слов.
Чтобы обеспечить все перечисленные требования, учитель на каждом уроке русского языка занимается разными сторонами языка. Материал же программы распределяют по учебным четвертям так, чтобы обеспечить возможность разностороннего изучения языка, повторение и взаимосвязь грамматической теории и языковой практики. Таким образом, все сказанное об особенностях планирования по грамматике и правописанию не исключает необходимости выделять центральные, основные темы для работы над ними в определенный период учебного времени. Такие центральные, основные темы имеются в программе каждого их трех начальных классов. Так, например, центральным разделом программы первого класса является раздел «Звуки и буквы». Во втором классе таким центральным, основным разделом является раздел «Слово». В третьем классе главное внимание учащихся на уроках русского языка сосредотачивается на изменение слов в предложениях. Поэтому здесь центральным, основным разделов является изменение и связь слов. 3. Методы и приемы изучения состава слов. Знакомство со значащими частями слова, с морфемным составом слова программа предполагает во втором классе. Дается слово лес, к нему подбираются слова: лесок, лесник, лесной. Вводится термин «корень» и «однокоренные слова»; в понятие «корень» будет входить признак: главная смысловая часть, общая для однокоренных слов; позже, когда дети познакомятся с другими смысловыми частями слова, сюда войдет еще один признак: часть слова, от которой с помощью приставок и суффиксов образуются новые слова. Чтобы у детей не получилось ложного представления о родственных словах как о таких, которые близки или сходны только по звучанию, учитель сопоставляет слова вроде нос и носить. Выясняется, что родственными или однокоренными словами являются только те, которые имеют и общую часть, и общее, близкое значение [20, С. 134]. По своему характеру упражнения по выяснению родственных слов и по выделению корня в них обычно бывают такие: 1) даются ряды однокоренных слов, требуется выделить в них корень; 2) даются предложения и небольшие связные тексты, в которых встречаются родственные слова; 3) проводится работа над осмыслением корней слов; 4) проводится работа по образованию от данного корня однокоренных слов. Так как слова по своему морфемному составу бывают различной степени сложности, и учащиеся знакомятся со всеми частями слова не сразу. Сначала даются слова, состоящие из корня и окончания. Потом дети разбирают слова, состоящие из корня и суффикса. Затем, когда дети познакомятся с приставками, идут слова, состоящие из корня и приставки. Наконец, разбираются смешанные случаи. Основной, наиболее ответственной темой, связанной с изучением состава слова, и в частности, корня, являются тема «Правописание безударных гласных корня». Если в первом классе усвоение правописания безударных гласных развивается на фонетической основе, то дальше формирование навыка писать безударные гласные должно идти иначе. Уже во втором классе совершается переход на морфемную основу. Если ученик верно выделил в слове корень, прочитал его отдельно, обратил внимание на его графический образ, то этим уже в значительной мере обеспечено правильное написание гласной корня. Для усвоения правила правописания безударных гласных большое значение имеют разнообразные упражнения. Все упражнения сопровождаются дополнительными работами: дети ставят ударения, подчеркивают безударные гласные, иногда выделяют целиком корень, дают устные объяснения. При изучении безударных гласных в корне пользуются разными приемами проверки их правописания в зависимости от характера слов. Такими являются: 1) замена единственного числа множественным: гора – горы; 2) замена множественного числа единственным: дома – дом; 3) образование слов ласкательного значения: трава – травка; 4) нахождение к множественному слову односложного слова: кормушка – корм; 5) замена существительного прилагательным: зима – зимний; 6) замена одной формы глагола другой: пилил – пилят. Не следует добиваться того, чтобы учащиеся запоминали и формулировали эти способы проверки в виде правил. Упражнения, подобные перечисленным, развивают грамматико-орфографическую гибкость, понимание смысловых связей между словами, дети практически усваивают единство написания родственных слов. Имеет некоторое значение и порядок, в котором изучаются безударные гласные; целесообразней всего давать для изучения слова с противопоставляемыми буквами о-а, е-и-я (читаются одинаково, а пишутся 2) окончание противопоставлено по своей роли корню: оно служит для связи слов; 3) окончание изменяется в зависимости от связи с другими словами. Синтаксический признак окончания очень важен для понимания склонения и спряжения, с которыми дети познакомятся несколько позже; кроме того, понимание синтаксической роли окончания вносит осмысленность в работу по установлению связи между словами при выделении пар слов, чем ученики второго класса должны серьезно заниматься [22, С. 203]. Чтобы учащиеся поняли синтаксическую роль окончаний, рекомендуется для наблюдений брать так называемые деформированные предложения; причем слова в этих предложениях берутся в начальной форме; требуется восстановить предложение, связав слова между собой; для чего, конечно, потребуется изменение окончаний. Работа над разделом «Состав слова» не может сводиться только к анализу слов, она предполагает и синтетические упражнения. Подбор однокоренных, или родственных слов – наиболее распространенный и полезный вид упражнений этого рода. Дается какое-либо слово (существительное, прилагательное, глагол), дети подбирают однокоренные слова. На первых порах ряд этих слов будет небольшим: 2-3 слова, но постепенно он расширяется, например, к слову корм подбираются слова кормушка, кормить, к слову боль – слова больной, болеть, больница, больно, к слову снег – снеговик, снегурочка и даже слово снежок, снежный, к слову лететь – летчик, полет, залететь и т.д. Такого рода упражнения очень важны для осмысленного усвоения правописания корней и приставок. Кроме того, они полезны и для развития представлений о смысловых связях слов друг с другом и для систематизации словаря. Очень удобными и полезными являются упражнения в анализе и подборе родственных слов при изучении частей речи, когда от слова, принадлежащего к одной части речи, образуются слова других грамматических разрядов. Вообще следует считать необходимым чуть ли не на каждом уроке проводить подбор однокоренных слов и анализ морфемного состава слов на каждом уроке грамматики и правописания во втором и третьем классах. ЗАКЛЮЧЕНИЕ Профессионализм, любовь к детям, ответственное отношение к их судьбе, к их будущему, постоянное самообразование, поиск, творчество помогут каждому учителю уже при обучении детей составу слов, заложить прочные основы последующих шагов ребенка в овладении богатствами родного языка в развитии и совершенствовании своей речи. Чтобы правильно вести работу по морфемике, учителю необходимо постоянно помнить некоторые важные языковые закономерности. Морфема – это минимальная значимая часть слова, которая, как и всякая другая языковая единица, имеет две неразрывно связанные между собою стороны: внешнюю и внутреннюю. Морфема выделяется в ряду слов, имеющих сходство по указанным двум признакам: общность в значении и фонемном составе. Постоянное внимание учителя к тому, что в нашем языке возможны морфемы-синонимы, омонимичные значимые части и т.п., создает у учащихся представление о неисчерпаемом богатстве языка, его безграничных возможностях для выражения всех оттенков мысли. При разборе слов по составу, так и при звуковом анализе, учитель должен очень внимательно относиться к подбору слов для работы и быть готовым дать правильное объяснение современной структуры слова и его происхождения. Морфемика позволяет получить сведения о строении слова, широко используемые в словообразовании и морфологии. Становление морфемики как особой лингвистической дисциплины стало возможным благодаря исследованиям основателя Казанской лингвистической школы И.А. Бодуэна де Куртенэ, который в 1881 ввел в научный оборот понятие морфемы. ПРИЛОЖЕНИЕ. Конспект урока. Тема урока: разбор слова по составу. Цели урока: 1. Продолжить формирование представлений о том, что значит разобрать слово по составу. 2. развивать навыки разбора слов по составу, орфографическую зоркость учащихся, память, речь,, мышление и воображение. 3. Воспитывать у учащихся любовь к предмету, аккуратность, умение выслушивать ответы детей. Ход урока. I. Организация внимания детей. II. Акутуализация ранее изученного. а) проверка домашнего задания. Словарная работа: прочтите выписанные словарные слова и образованные родственные. б) Минутка чистописания. Прописи, с. 18 — Какие элементы общие в написании данных букв? — На какие две группы можно распределить эти буквы? — По каким признакам? III. Изучение нового материала. — Запишите слова, записанные на доске, отделите в них основу от окончания. На доске и в тетрадях начертить схему этих слов. — Упр. 42. (с. 118) Чтение текста, объяснение значений выделенных слов. — Конструирование текста по последовательности выполняемых строительных работ. — Комментированная запись текста. — Разобрать по составу выделенные слова. — Чтение сведений о языке на стр. 129. IV. Физкультминутка. V. Продолжение работы по теме урока. — Вспомните, кто произносил такие слова. Глазки, глазки, что вы делали? Ушки, ушки, а вы что делали? Ножки, ножки, а вы что делали? А вы, хвостище, что делали? -Какие здесь использованы предложения по цели высказывания? — Можно ли определить, как герой сказки относился к своим глазам, ушам, ногам, хвосту? Какая часть слова вам в этом помогает? Запишите предложения, имена существительные разберите по составу. — Выпишите из каждого ряда слова с приставками. Разберите их по составу, для этого вспомните алгоритм разбора. Зал, заехал, заря. Долина, долетел, долго, доброта. Изрубить, изба, избить. Полоса, полено, полежал, поле. — Подпишите к словам однокоренные слова с противоположным значением. Используйте приставки от -, у-, вы-. VI. Итог урока. 1. Обобщение. — Из каких частей может состоять основа слова? — Какая часть должна обязательно входить в основу слова? — При помощи каких частей можно образовать родственные слова? — Что значит разобрать слова по составу? Как это сделать? — Молодцы, ребята. До свидания!
Знакомство со значащими частями слова, с морфемным составом слова программа предполагает во втором классе. Дается слово лес, к нему подбираются слова: лесок, лесник, лесной. Вводится термин «корень» и «однокоренные слова»; в понятие «корень» будет входить признак: главная смысловая часть, общая для однокоренных слов; позже, когда дети познакомятся с другими смысловыми частями слова, сюда войдет еще один признак: часть слова, от которой с помощью приставок и суффиксов образуются новые слова. Чтобы у детей не получилось ложного представления о родственных словах как о таких, которые близки или сходны только по звучанию, учитель сопоставляет слова вроде нос и носить. Выясняется, что родственными или однокоренными словами являются только те, которые имеют и общую часть, и общее, близкое значение [20, С. 134]. По своему характеру упражнения по выяснению родственных слов и по выделению корня в них обычно бывают такие: 1) даются ряды однокоренных слов, требуется выделить в них корень; 2) даются предложения и небольшие связные тексты, в которых встречаются родственные слова; 3) проводится работа над осмыслением корней слов; 4) проводится работа по образованию от данного корня однокоренных слов. Так как слова по своему морфемному составу бывают различной степени сложности, и учащиеся знакомятся со всеми частями слова не сразу. Сначала даются слова, состоящие из корня и окончания. Потом дети разбирают слова, состоящие из корня и суффикса. Затем, когда дети познакомятся с приставками, идут слова, состоящие из корня и приставки. Наконец, разбираются смешанные случаи. Основной, наиболее ответственной темой, связанной с изучением состава слова, и в частности, корня, являются тема «Правописание безударных гласных корня». Если в первом классе усвоение правописания безударных гласных развивается на фонетической основе, то дальше формирование навыка писать безударные гласные должно идти иначе. Уже во втором классе совершается переход на морфемную основу. Если ученик верно выделил в слове корень, прочитал его отдельно, обратил внимание на его графический образ, то этим уже в значительной мере обеспечено правильное написание гласной корня. Для усвоения правила правописания безударных гласных большое значение имеют разнообразные упражнения. Все упражнения сопровождаются дополнительными работами: дети ставят ударения, подчеркивают безударные гласные, иногда выделяют целиком корень, дают устные объяснения. При изучении безударных гласных в корне пользуются разными приемами проверки их правописания в зависимости от характера слов. Такими являются: 1) замена единственного числа множественным: гора – горы; 2) замена множественного числа единственным: дома – дом; 3) образование слов ласкательного значения: трава – травка; 4) нахождение к множественному слову односложного слова: кормушка – корм; 5) замена существительного прилагательным: зима – зимний; 6) замена одной формы глагола другой: пилил – пилят. Не следует добиваться того, чтобы учащиеся запоминали и формулировали эти способы проверки в виде правил. Упражнения, подобные перечисленным, развивают грамматико-орфографическую гибкость, понимание смысловых связей между словами, дети практически усваивают единство написания родственных слов. Имеет некоторое значение и порядок, в котором изучаются безударные гласные; целесообразней всего давать для изучения слова с противопоставляемыми буквами о-а, е-и-я (читаются одинаково, а пишутся 2) окончание противопоставлено по своей роли корню: оно служит для связи слов; 3) окончание изменяется в зависимости от связи с другими словами. Синтаксический признак окончания очень важен для понимания склонения и спряжения, с которыми дети познакомятся несколько позже; кроме того, понимание синтаксической роли окончания вносит осмысленность в работу по установлению связи между словами при выделении пар слов, чем ученики второго класса должны серьезно заниматься [22, С. 203]. Чтобы учащиеся поняли синтаксическую роль окончаний, рекомендуется для наблюдений брать так называемые деформированные предложения; причем слова в этих предложениях берутся в начальной форме; требуется восстановить предложение, связав слова между собой; для чего, конечно, потребуется изменение окончаний. Работа над разделом «Состав слова» не может сводиться только к анализу слов, она предполагает и синтетические упражнения. Подбор однокоренных, или родственных слов – наиболее распространенный и полезный вид упражнений этого рода. Дается какое-либо слово (существительное, прилагательное, глагол), дети подбирают однокоренные слова. На первых порах ряд этих слов будет небольшим: 2-3 слова, но постепенно он расширяется, например, к слову корм подбираются слова кормушка, кормить, к слову боль – слова больной, болеть, больница, больно, к слову снег – снеговик, снегурочка и даже слово снежок, снежный, к слову лететь – летчик, полет, залететь и т.д. Такого рода упражнения очень важны для осмысленного усвоения правописания корней и приставок. Кроме того, они полезны и для развития представлений о смысловых связях слов друг с другом и для систематизации словаря. Очень удобными и полезными являются упражнения в анализе и подборе родственных слов при изучении частей речи, когда от слова, принадлежащего к одной части речи, образуются слова других грамматических разрядов. Вообще следует считать необходимым чуть ли не на каждом уроке проводить подбор однокоренных слов и анализ морфемного состава слов на каждом уроке грамматики и правописания во втором и третьем классах. ЗАКЛЮЧЕНИЕ Профессионализм, любовь к детям, ответственное отношение к их судьбе, к их будущему, постоянное самообразование, поиск, творчество помогут каждому учителю уже при обучении детей составу слов, заложить прочные основы последующих шагов ребенка в овладении богатствами родного языка в развитии и совершенствовании своей речи. Чтобы правильно вести работу по морфемике, учителю необходимо постоянно помнить некоторые важные языковые закономерности. Морфема – это минимальная значимая часть слова, которая, как и всякая другая языковая единица, имеет две неразрывно связанные между собою стороны: внешнюю и внутреннюю. Морфема выделяется в ряду слов, имеющих сходство по указанным двум признакам: общность в значении и фонемном составе. Постоянное внимание учителя к тому, что в нашем языке возможны морфемы-синонимы, омонимичные значимые части и т.п., создает у учащихся представление о неисчерпаемом богатстве языка, его безграничных возможностях для выражения всех оттенков мысли. При разборе слов по составу, так и при звуковом анализе, учитель должен очень внимательно относиться к подбору слов для работы и быть готовым дать правильное объяснение современной структуры слова и его происхождения. Морфемика позволяет получить сведения о строении слова, широко используемые в словообразовании и морфологии. Становление морфемики как особой лингвистической дисциплины стало возможным благодаря исследованиям основателя Казанской лингвистической школы И.А. Бодуэна де Куртенэ, который в 1881 ввел в научный оборот понятие морфемы. ПРИЛОЖЕНИЕ. Конспект урока. Тема урока: разбор слова по составу. Цели урока: 1. Продолжить формирование представлений о том, что значит разобрать слово по составу. 2. развивать навыки разбора слов по составу, орфографическую зоркость учащихся, память, речь,, мышление и воображение. 3. Воспитывать у учащихся любовь к предмету, аккуратность, умение выслушивать ответы детей. Ход урока. I. Организация внимания детей. II. Акутуализация ранее изученного. а) проверка домашнего задания. Словарная работа: прочтите выписанные словарные слова и образованные родственные. б) Минутка чистописания. Прописи, с. 18 — Какие элементы общие в написании данных букв? — На какие две группы можно распределить эти буквы? — По каким признакам? III. Изучение нового материала. — Запишите слова, записанные на доске, отделите в них основу от окончания. На доске и в тетрадях начертить схему этих слов. — Упр. 42. (с. 118) Чтение текста, объяснение значений выделенных слов. — Конструирование текста по последовательности выполняемых строительных работ. — Комментированная запись текста. — Разобрать по составу выделенные слова. — Чтение сведений о языке на стр. 129. IV. Физкультминутка. V. Продолжение работы по теме урока. — Вспомните, кто произносил такие слова. Глазки, глазки, что вы делали? Ушки, ушки, а вы что делали? Ножки, ножки, а вы что делали? А вы, хвостище, что делали? -Какие здесь использованы предложения по цели высказывания? — Можно ли определить, как герой сказки относился к своим глазам, ушам, ногам, хвосту? Какая часть слова вам в этом помогает? Запишите предложения, имена существительные разберите по составу. — Выпишите из каждого ряда слова с приставками. Разберите их по составу, для этого вспомните алгоритм разбора. Зал, заехал, заря. Долина, долетел, долго, доброта. Изрубить, изба, избить. Полоса, полено, полежал, поле. — Подпишите к словам однокоренные слова с противоположным значением. Используйте приставки от -, у-, вы-. VI. Итог урока. 1. Обобщение. — Из каких частей может состоять основа слова? — Какая часть должна обязательно входить в основу слова? — При помощи каких частей можно образовать родственные слова? — Что значит разобрать слова по составу? Как это сделать? — Молодцы, ребята. До свидания!
разбор слова | Полезные советы интернета
Политика конфиденциальности
Политика конфиденциальности персональной информации (далее — Политика) действует в отношении всей информации, которую infodengy.ru, может получить о Пользователе во время использования им любого из сервисов, служб, форумов, продуктов или услуг infodengy.ru (далее Сервисов) и в ходе исполнения infodengy.ru любых соглашений и договоров с Пользователем.
Использование сервисов infodengy.ru означает безоговорочное согласие Пользователя с настоящей Политикой и указанными в ней условиями обработки его персональной информации; в случае несогласия с этими условиями Пользователь должен воздержаться от использования Сервисов.
1. Персональная информация Пользователей, которую обрабатывает infodengy.ru
В рамках настоящей Политики под «персональной информацией Пользователя» понимаются:
1.1 Персональная информация, которую Пользователь предоставляет о себе самостоятельно при регистрации (создании учётной записи) или в процессе использования Сервисов, включая персональные данные Пользователя. Обязательная для предоставления Сервисов информация помечена специальным образом. Иная информация предоставляется Пользователем на его усмотрение.
1.2 Информация, которая автоматически передается infodengy.ru в процессе его эксплуатации с помощью установленной на устройстве Пользователя программы, в том числе IP-адрес, данные файлов cookie, информация о браузере Пользователя (или иной программе, с помощью которой осуществляется доступ к сервисам).
Настоящая Политика применима только к информации, обрабатываемой в ходе работы с порталом infodengy.ru.
infodengy.ru не проверяет достоверность персональной информации, предоставляемой Пользователем, и не может оценивать его дееспособность. Однако infodengy.ru исходит из того, что пользователь предоставляет достоверную и достаточную персональную информацию и поддерживает эту информацию в актуальном состоянии.
2. Цели обработки персональной информации Пользователей
infodengy.ru собирает и хранит только ту персональную информацию, которая необходима для предоставления Сервисов или исполнения соглашений и договоров с Пользователем, за исключением случаев, когда законодательством предусмотрено обязательное хранение персональной информации в течение определенного законом срока.
Персональную информацию Пользователя infodengy.ru обрабатывает в следующих целях:
2.1 Идентификация стороны в рамках работы с infodengy.ru;
2.2 Предоставление Пользователю индивидуальных услуг;
2.3 Связь с Пользователем, в том числе направление уведомлений, запросов и информации, касающихся использования infodengy.ru, а также обработка запросов и заявок от Пользователя;
2.4 Улучшение качества Сервисов, удобства их использования, разработка новых Сервисов;
2.5 Проведение статистических и иных исследований на основе обезличенных данных.
3. Условия обработки персональной информации Пользователей и её передачи третьим лицам.
В отношении персональной информации Пользователя сохраняется ее конфиденциальность, кроме случаев добровольного предоставления Пользователем информации о себе для общего доступа неограниченному кругу лиц.
infodengy.ru имеет право передать персональную информацию Пользователя третьим лицам в следующих случаях:
3.1. Пользователь согласился на такие действия;
3.2. Передача предусмотрена российским или иным применимым законодательством в рамках установленной законодательством процедуры;
3.3. Такая передача происходит в рамках продажи или иной передачи бизнеса (полностью или в части), при этом к приобретателю переходят все обязательства по соблюдению условий настоящей Политики применительно к полученной им персональной информации;
При обработке персональных данных Пользователей infodengy.ru руководствуется Федеральным законом РФ «О персональных данных».
4. Изменение и удаление персональной информации. Обязательное хранение данных
4.1 Пользователь может в любой момент изменить (обновить, дополнить) предоставленную им персональную информацию или её часть, воспользовавшись функцией редактирования персональных данных в соответствующем разделе Сервиса либо, написав запрос в службу поддержки: [email protected]
4.2 Пользователь также может удалить предоставленную им в рамках определенной учетной записи персональную информацию, написав запрос в службу поддержки: [email protected]
4.3 Права, предусмотренные пп. 4.1. и 4.2. настоящей Политики могут быть ограничены в соответствии с требованиями законодательства. В частности, такие ограничения могут предусматривать обязанность infodengy.ru сохранить измененную или удаленную Пользователем информацию на срок, установленный законодательством, и передать такую информацию в соответствии с законодательно установленной процедурой государственному органу.
5. Меры, применяемые для защиты персональной информации Пользователя
5.1 infodengy.ru принимает необходимые и достаточные организационные и технические меры для защиты персональной информации Пользователя от неправомерного или случайного доступа, уничтожения, изменения, блокирования, копирования, распространения, а также от иных неправомерных действий с ней третьих лиц.
6. Обратная связь. Вопросы и предложения
Все предложения или вопросы по поводу настоящей Политики Пользователь вправе направлять в службу поддержки: [email protected]
Словарь по разбору. Морфемный разбор слова по составу онлайн примеры бесплатно, словообразовательный разбор на словонлайн. Краткий сленговый словарь современного подводника Словарь не претендует на объективность и полноту
Тихонов А.Н. Морфемно-орфографический словарь русского языка. Русская морфемика. — М.: Школа-Пресс, 1996. — 704 с.
Словарь совмещает параметры морфемного словаря (словаря морфемного состава слов) и орфографического словаря.
В словарь также включён теоретический материал по морфемике.
Образцы словарных статей
био… —
первая часть сложных слов, пишется всегда слитно
в/высь, нареч
. (взлете´ть ввысь), но сущ.
в высь (в высь поднебесную)
вы´/кач/а/нн/ый (от
вы´/кач/а/ть)
вы´/кач/енн/ый (от
вы´/кат/и/ть).
Кузнецова А.И., Ефремова Т.Ф. Словарь морфем русского языка. — М.: Русский язык, 1986. — 1136 с.
Словарь содержит около 52000 слов. Собственно словарь состоит из 3 частей: 1. Корневая часть; 2. Префиксальная часть; 3. Суффиксальная часть. В словаре также дана информация о принципах морфемного анализа и правилах построения морфемных словарей.
В Словарь включены следующие приложения: 1. Корни русского языка, сведённые в морфемы. 2. Наиболее продуктивные корни русского языка. 3. Омоморфемные корни. 4. Префиксы русского языка. 5. Суффиксы русского языка. 6. Наиболее активные суффиксы и префиксы русского языка. 7. Наиболее продуктивные модели русских слов. 8. Наиболее активные многоморфемные единства (морфемные блоки).
Образцы словарных статей
I. Корневая часть
ДЕ´Д
√дед- Ø
√де́
д-ин-а
√де́д
-к-а
√де́д
-ов-Ø
√де́д
-ов-ск-ий
√де́д
-ушк-а
пра´-√- Ø
пра-√де́д
-ов-ск-ий
пра-√де́д
-ушк-а
пра- пра´-√дед- Ø
II. Префиксальная часть
ВОЗО
ВОЗО-√-и´-ть
— мн
III. Суффиксальная часть
АТОР
I место
√-А´ТОР- Ø
— газ, экзамен√-А´ТОР-ск-ий
— экзаменII место
√-ифик-А´ТОР- Ø
— газ, класс
Тихонов А.Н. Словообразовательный словарь русского языка: В 2 т. — 2-е изд., стер. — М.: Русский язык, 1990.
Данное лексикографическое произведение является первым большим гнездовым словарём русского языка. Содержит информацию о словообразовательной структуре около 145000 производных слов.
В словарь также включены сведения об основных понятиях русского словообразования.
Образец словарной статьи
138. вероя´тн(ый)
| вероя´тн-о | |
| не -вероя´тно 1 | |
| вероя´тн-ость | |
| вероя´тност-н -ый не равн-о | |
| вероя´т-иj -е | |
| не -вероя´тие 1 | |
| не -вероя´тный | |
| невероя´тн-о 2 невероя´тн-ость невероя´т-иj | |
| мал-о -вероя´тн(ый) см. малый 1 | |
| маловероя´тн-ость | |
Баранов М.Т. Школьный словарь образования слов русского языка. — М.: Просвещение, 1997. — 350 с.
Словарь содержит информацию о строении слова, способе его образования.
Образцы словарных статей
бакале´й|н
|ый (прил.) ← бакале
´[й
а]
завхо´з (сущ., м
.) ← зав
е´дующий хоз
я´йством (сложение сокращ. основ; з’//з; в’//в
;
утрата всех удар.; приобретение нового удар.)
зага´доч|н
|ый (прил.) ← зага´дк
а (ноль зв.//о
; к
//ч
)
Алексеенко М.А., Белоусова Т.П., Литвинникова О.И. Словарь отфразеологической лексики современного русского языка. — М.: Азбуковник, 2003. — 400 с.
Словарь совмещает элементы толкового, словообразовательного и фразеологического словарей. Цель — «системно представить особый пласт лексики современного русского языка — слова, значения которых сформировались под влиянием фразеологических единиц».
Образцы словарных статей
АПОФЕГЕ´Й
и АПОФИГЕ´Й,
-ея, м. Жарг. Окказ. Шутл.-ирон.
Высшая степень равнодушия к окружающему; высокомерное отношение к социально-бытовым проблемам. Образовано на базе фразеологизма по
фиг
и сущ. апогей и апофеоз. Популярность получило благодаря символическому упо-треблению в повести Ю. Полякова «Апофегей». ♦ ПОЛНЫЙ АПОФЕГЕЙ (апофигей). Жарг.
1.То же, что апофегей.
2. О чем-л. очень хорошем, красивом, высшего качества, вы-зывающем восхищение. ПО ФИГ (фигу). Прост.
кому что. Безразлично. Всем все по фигу, вот и докатились…
Запись 1997 г.
БЕСПЯТИМИНУ´ТНЫЙ,
-ая, -ое. Окказ
. Почти состоявшийся (в профессии, общественном положении). Бес-пятиминутный инженер Лебедев.
Огонек, 1984, № 39. Беспя-тиминутный кандидат наук, — представил меня коллегам заведующий отделом, — защиту диссертации назначили на осень.
Запись 2001 г. Вот сидит паренек, без пяти минут он мастер.
Песня из к-ф. «Карнаваль-ная ночь».
Бес/пяти/минут-н(ый)
ДОПОТО´ПНЫЙ,
-ая, -ое. Разг. Шутл.-ирон.
Суще-ствовавший до потопа
. Устарелый, отживший. // Вышедший из употребления, старомодный. Слабо развита полиграфиче-ская база: здесь мы на полвека отстаем от зарубежных стран. Но даже и допотопного оборудования мало.
АиФ, 1989, № 46, 4. — Незачем распространять свои допотопные идеи и возвращать нас за сто лет назад! Это всё отжи-ло.
И. Гончаров, Литературный вечер. В одной из закрытых бухт стоял на зимовке небольшой, допотопной конструкции, па-лубный карбас.
Станюкович, Матроска. Когда это было, а ты все помнишь. Это же до всемирного потопа было, так что выкидывай из своей го-ловы, никто уж ничего не помнит, кто первый из братьев на отца родного пошел. Тебе за них ответ не держать.
Запись 1973 г.
До/потоп-н(ый)
Алексеев Д.И., Гозман И.Г., Сахаров Г.В. Словарь сокращений русского языка / Под ред. Д.И. Алексеева. — 4-е изд., стер. — М.: Русский язык, 1984. — 487 с.
Словарь содержит около 17 700 сокращений.
Образцы словарных статей
АДД
[а-дэ-дэ´] — а
втореферат д
иссертации на соискание учёной степени д
октора наук
вуз
, м
. — в
ысшее у
чебное з
аведение
геогр
. — география; географический
гр-ка
— гражданка
ла´зер,
м
., англ
. — l
ight a
mplification by s
timulated e
mission of r
adiation, laser
(квантовомеханический усилитель светового диапазона)
МАГАТЭ
[магатэ´] — М
еждународное аг
ентство по ат
омной э
нергии
тем
… — тематический (например: темпла´н)
т. о.
— таким образом.
Скляревская Г.Н. Словарь сокращений современного русского языка. — М.: Эксмо, 2004. — 448 с.
Словарь содержит более 6 000 сокращений.
Образцы словарных статей
агро
Аграрный.
БСО
[бэ-эс-о´] и (разг
.) [бэ-сэ-о´], нескл., м
. Большой симфонический оркестр. БСО отправился на гастроли. Конкурс в БСО.
в
. Век (после цифры).
военкома´т
, а, м
. Военный комиссариат.
к/ф
Кинофильм.
с.г.
Сего года.
ЮНЕП
[юне´п], нескл., ж.
(англ
. United Nations Environment Program — UNEP) Программа Организации Объединённых Наций по окружающей среде.
Тихонов А.Н., Бояринова Л.З., Рыжкова А.Г. Словарь русских личных имён. — М.: Школа-Пресс, 1995. — 736 с.
В словаре представлены уменьшительно-ласкательные производные от личных имён, а также даны этимологические справки.
Словарь содержит следующие приложения: 1. Склонение и правописание личных имён; 2. Образование, склонение, употребление отчеств; 3. Именинный календарь; 4. Список имён, которыми называли новорождённых детей в Смоленской области с 1989 по 1992 гг.; 5. Из инструкции о порядке регистрации актов гражданского состояния в РФ.
Образец словарной статьи
ИОЛА´НТ|А
, ы ж
[лат
. «фиалка»].
П р о и з в о д н ы е (7):
Иолант|а
Иол(ант|а)→Иол|а→Ё
л|а
1
Ё
л|а 2
(Ио)лан(т|а)→Лан|а
→Лан|к|а 1→Ланоч
|к|а 1
Лань|к|а 1→Ланеч
|к|а 1
Лан|ечк|а 2, Лан|очк|а 2
Лан|ечк|а 3, Лан|к|а 2, Лан|очк|а 3, Лань|к|а 2
Словарь названий жителей СССР / Под ред. А.М. Бабкина и Е.А. Левашова. — М.: Русский язык, 1975. — 616 с.
Словарь содержит около 10 000 названий.
В словарь включены следующие приложения: 1. Названия жителей городов зарубежных стран; 2. Названия жителей по рекам, озерам, островам и т.п. (зарубежные страны).
Образцы словарных статей
ВОРОНЕЖСКАЯ ОБЛАСТЬ
А´ННА пгт, А´ННИНСКИЙ р-н
а´ннинец
, -н ц а.
ВЕЛИКОБРИТАНИЯ
(Соединенное Королевство Великобритании и Северной Ирландии)
АБЕРДИ´Н г., графство АБЕРДИ´Н
аберди´нцы
, -ц е в
аберди´нец
, -н ц а.
Левашов Е.А. Словарь прилагательных от географических названий. — М.: Русский язык, 1986. — 550 с.
Словарь включает около 13 000 прилагательных.
В приложении дана информация о прилагательных, образованных со значительным изменением производящей основы.
Образцы словарных статей
БРЮССЕ´ЛЬ (БРЮ´ССЕЛЬ) г. (Бельгия)
брюссе´льский (брю´ссельский)
. На углу двух узких брюссельских улочек — знаменитый фонтан «Манекен-писс».
Л. Ленч, В автобусе по трем странам. «Каравелла», подпрыгнув, оторвалась от бетонной дорожки брюссельского аэродрома.
Неделя, 1976, 47.
ЛАВА´ЛЬ г. (Франция)
лава´льский
ЦАГА´Н АМА´Н пгт (РСФСР)
цага´н-ама´нский
Ефремова Т.Ф. Толковый словарь словообразовательных единиц русского языка: Ок. 1900 словообразов. единиц. — 2-е изд., испр. — М.: АСТ: Астрель, 2005. — 636, с.
Словарь представляет собой лексикографическое описание аффиксальных словообразовательных единиц русского языка и включает 1892 морфемы. Даёт сведения о семантике данных единиц, а также об их сочетаемостных свойствах.
В словарь включены следующие приложения: 1. Система словообразовательных единиц, описанных в словаре. 2. Словообразовательная система современного русского языка как объект изучения в нерусской аудитории.
Образцы словарных статей
(-АМИ/-ЯМИ)
Нерегулярная словообразовательная единица, выделяющаяся в наречиях с обстоятельственным значением времени, места или образа действия, которые названы соответствующими мотивирующими словами: верха´ми, времена´ми, года´ми, места´ми, па´чками, сажёнками, уры´вками.
При образовании используются беспредложные формы творительного падежа множественного числа мотивирующих имён существительных.
Словообразующий суффикс может быть как ударным (с ударением на гласной его первого слога), так и безударным.
Регулярная и продуктивная формообразовательная единица, образующая имена прилагательные со значением признака, который характеризуется высшей степенью проявления качества, названного мотивирующим словом (в роли последнего обычно выступают формы превосходной степени прилагательных), например: наибо´льший, наикрепча´йший, наилу´чший, наиумне´йший, наиху´дший
(ср., однако, наипосле´дний, наисего´дняшний
и некот. др.).
Присоединяется, как правило, к производной мотивирующей основе с суффиксами превосходной степени -айш-, ейш-, -ш-
, примыкая непосредственно к корню.
Формообразующий префикс безударен, а ударение падает на мотивирующую основу (на тот же слог, что и в мотивирующем имени прилагательном).
Рацибурская Л.В. Словарь уникальных морфем современного русского языка.
—
М. : Флинта: Наука, 2009. — 160 с.
Словарь является первым в отечественной лексикографии научно-справочным изданием, в котором отражён состав уникальных морфем современного русского языка. Словарь содержит более трёхсот уникальных единиц суффиксального, префиксального и корневого характера. Предисловие включает следующие разделы: «Вопрос об уникальных морфемах в современной лингвистике», «Уникальные морфемы и принципы их выделения» и «Типы уникальных морфем».
Образцы словарных статей
-ЯРУС-
(/’АРУС/-) (стекл-ярус)
— значение предмета, состоя-щего из /материала, названного мотивирующим существитель-ным (стекло)/.
Ср.: ват-ник, горчич-ник, морков-ник.
СТЕКЛЯ´РУС
— «род крупного бисера — разноцветные короткие трубочки из стекла, нанизываемые на нитку».
Варваре сшили коричневое платье с черными кружевами и со стеклярусом (Чехов. В овраге).
ВПО-
(впо-тьм-ах)
—
указывает на отнесенность признака /к то-му, что названо мотивирующим существительным (тьма)/.
Ср.: по-утр-у, по-низ-у; в сухомятк-у, в шутк-у; по-середине, по-невол-е.
ВПОТЬМА´Х
— «в темноте, в потемках».
Пробираясь ощупью темным коридором в свой номер, Арбузов все ждал, что он вот-вот наткнется впотьмах на какое-нибудь пре-пятствие (Куприн. В цирке).
-ВА-:
ва-банк,
мотивирующее — существительное банк
(в значе-нии «в некоторых карточных играх: определенная сумма де-нег, поставленная на кон»).
ВА-БА´НК
— «в некоторых карточных играх: на все деньги, на-ходящиеся в банке».
/Офицер/ все ставил ва-банк наличные деньги и выигрывал (Л. Толстой. Севастополь в августе 1855 г.).
См. также Белякова, Г. В. Суффиксальные nomina loci в современном русском языке: толково-словообразовательный словарь / Г. В. Белякова; науч. ред. д-р филол. наук, проф. Н. Ф. Алефиренко. — Астрахань: Издательский дом «Астраханский университет», 2008. — 259 с.
Баранова Л.А. Словарь аббревиатур иноязычного происхождения. — М.: АСТ-ПРЕСС КНИГА, 2009. — 320 с. — (Малые настольные словари русского языка).
Разобрать слово по составу или сделать его морфемный анализ означает указать, из каких морфем оно состоит. Под морфемой понимается минимально значимая часть слова.
В русском языке существуют следующие морфемы:
- корень — самая главная часть слова, несущая его значение. У однокоренных слов — общий корень. Например, слова «лист», «листочек» и «листва» имеют общий корень -«лист». Бывают слова, которые состоят только из корня — «гриб», «метро», «остров». Бывает, что корня два — «теплоход», «водопад». Бывает, что корней три — не стоит пугаться — «водогрязелечебница». Повтори правило, которое касается соединительных гласных, чтобы не делать ошибки при их написании;
- суффикс — значимая часть слова. Расположена обычно после корня. Используется для образования новых слов. Например, в слове «чайник» «чай» — это корень, «ник» — это суффикс. Суффиксов в слове может не быть. Иногда суффиксов бывает два — например, в слове «подберезовик»;
- приставка — еще одна значимая часть слова. Расположена перед корнем. Назначение такое же, как и у суффикса — с ее помощью образовываются новые слова. В слове «подходит» «ход» — это корень, «под» — это приставка;
- Окончание — изменяемая часть слова. Для чего она нужна? Чтобы связывать слова в предложении;
- Основа — часть слова без окончания.
Каждая часть слова имеет графическое обозначение. Посмотреть, как обозначаются части слова, можно в учебнике по русскому языку, в морфемном словаре или в Интернете.
Правила и исключения при разборе по составу
Разбор слова по составу онлайн несложен, если знать правила, по которым он делается. На начальном этапе можно пользоваться морфемно-орфографическим словарем — он поможет не делать ошибок.
Обязательно в слове должен присутствовать только корень — один или несколько. Слов без корня не бывает. Не бывает слов и без основы. А вот слова без суффиксов, приставок или окончаний очень даже бывают. Этому не стоит удивляться.
Часто бывает, что все слово представляет собой основу. Так бывает, например, у наречий. Они относятся к неизменяемым частям речи. Слово «быстро» не имеет окончания («о» в слове — это суффикс), а потому все слово будет основой.
В проведении морфемного анализа ученику поможет словообразовательный словарь Тихонова. Этот учебник содержит информацию о составе 100 тыс. слов русского языка. Словарем удобно пользоваться, и в период обучения в начальной школе он должен стать твоей настольной книгой.
Тем же, кто обладает навыками работы в сети Интернет, будут полезными ресурсы, на которых можно сделать морфемный разбор слова онлайн. Тренируйся, если занятий в школе на уроках русского языка тебе недостаточно.
Краткая шпаргалка (план) по морфемному разбору слов
Морфемный разбор состоит из следующих этапов:
- Определяем к какой части речи относится слово. Для этого надо задать к нему вопрос. Возьмем для примера слово «поездка». Оно отвечает на вопрос «что?».
- Прежде всего надо найти в слове окончание. Для этого его нужно изменить несколько раз. Изменим его несколько раз — «перед поездкой», «в поездке». Видим, что изменяющаяся часть — «а». Это окончание.
- Разбор слова по составу продолжается определением корня. Подберем однокоренные слова — «поезд», «переезд». Сравним эти слова — не меняется часть «езд». Это и есть корень.
- Выясняем, какая в слове приставка. Для этого анализируем еще раз однокоренные слова — «поезд», «подъезд». Соответственно, в слове «поездка» приставка «по».
- Заключительный этап — это выяснение, где же в слове суффикс. Остается буква «к», которая стоит после корня и служит для образования слова. Это и есть суффикс.
- Обозначаем все части слова соответствующими символами.
Иногда услышав «эдакое» словечко мы заинтересовываемся, что оно подразумевает и откуда ростут его корни. Здесь полезно вспоминать, что структура любого слова разбирается с помощью двух анализов: морфемного и словообразовательного. И тут здорово может помочь разбор слова по составу онлайн бесплатно в интернете. Но какими бы возможностями не одаривала нас всемирная паутина, элементарное мы для себя всё же должны знать. Морфемный анализ – это выделение морфем, составляющих данное слово, то есть элементарные частички. При этом используя морфемный разбор слова онлайн, помните, что он же есть и разбор слова по составу онлайн. Совершаем его по пунктам:
Слово выписываем (не меняя формы его из контексте) и определяем часть речи, к которой оно принадлежит.
Отмечаемокончание. Просто склоняем слово и легко обнаруживаем его.
Находим основание.
Определить корень и перечислить однокоренные слова.
Обозначить префиксы, суффиксы, постфиксы и подбираем слова с подобными, но другим корнем.
Как видим, можно посидеть самому над словечком и разобрать по вышеуказанным пунктам или обратиться к опции «Морфемный разбор онлайн».
Словообразовательный разбор онлайн доступен тоже. На деле его также можно предоставить:
Найти исходник слова.
Обозначить есть ли это слово производным, указав на его основу.
Подобрать начальное слово (то есть то, от которого наше является производным).
Выделяем основу разбираемого нами слова и словообразующие суффиксы, постфиксы или префиксы.
Теперь можно определить способ, которым образовано данное слово.
Теперь, когда мы знаем, как разобрать слово по составу и как проанализировать словообразовательно укажем отличия двух этих способов и некоторые особенности, знание которых пригодится для их проведения:
1. При словообразовательном анализируем слово в начальном виде, а при морфемном – слово в той форме, в какой оно в тексте.
2. Сложные слова уже являются производными.
3. Чтобы узнать производное ли это слово достаточно указать его основу в начальной форме.
4. Когда мы видим в основе префикс или суффикс, это слово является сложным. (кроме случаев с бесприставочными глаголами).
5. Когда в основе начальной формы есть один корень, обычно оно определяется как непроизводное. Это не распространяется на следующие случаи: переход, из какой – либо части речи в другую; явлении нулевой суффиксации.
6. В слове мы всегда можем выделить его основу, а вот окончание – в части речи, которые изменяются.
Таким образом мы рассмотрели как можно изучить структуру слова и определить его происхождение.
Мы жители Украины, и после того, как у моей дочки появился в школе новый предмет- русский язык, возникли проблемы с морфемным разбором. Словари все отвезли еще лет 10 назад в деревню к бабушке- печь топить, поэтому и пришлось прибегнуть к интернету. В первом запросе мы искали слово . Теперь регулярно, даже ради любопытства, читаю словарь. Кто бы мог подумать, что есть сайты, где так удобно упорядочена информация, как у вас. Теперь без проблем справляемся с разбором слов по составу. Спасибо за ваш труд! Дарья Васильевна
Меня больше всего интересовали старо — русские слова, ли украинские, которые тоже имеют свою давнюю историю. Было для меня удивлением, что слово имеет давние корни, тем более, что его использовали не только в русском языке, но и в других языках тоже. Хочется отметить, что чем больше мы знаем историю слов, тем больше будем знать свою историю, а это очень интересно. Дети мои тоже этим интересуются и даже иногда советуют, что — то посмотреть новое и узнать. NikitaN
Всегда, когда слышу длинное и непонятное слово, пытаюсь самостоятельно разделить его на части, понять, как оно образовано. Если у самой не получается, приходится искать в специальной литературе, но часто там не могу найти искомое слово. Попыталась найти в интернете и мне очень помог данный словарь, здесь есть слова по составу онлайн. Очень быстро можно найти интересующее слово и увидеть полную информацию о нем. Очень приятно, что здесь размещены определения, которые пригодятся тем, кто не знает с чего начать разбор. Маргарита
С рождения мы являемся носителями языка и по мере расширения словарного запаса нам становится любопытно как произошли те или иные слова. Иногда не получается выделить основу слова самостоятельно и узнать словообразовательный или морфемный состав слова, тогда нам на помощь приходит детальный разбор слова по составу онлайн. Решение интересующих вопросов можно найти довольно просто. Здесь очень подробно описано как грамотно сделать разбор слова, пошаговая инструкция и правила разбора доступны даже для детей. Данный ресурс — находка для любознательных. Светлана
Анализ Морфем для разбора слова по составу не так прост, несмотря на четко предоставленные алгоритмы. Довольно непростые грамматические нюансы языка часто приводят к ошибочному или неоднозначному разбору современных частей слов. При выделении составных форм-морфем: «приставка-корень-суффикс-окончание» недостаточно их простой идентификации с частями слов, подобными заданным.Поэтому многие учащиеся бывают неуверенны, правилен ли их разбор слова по составу. Словарь онлайн бесплатно поможет устранить сомнения и усовершенствовать свои знания.Вот несколько причин первоначально неверного анализа:- разбор начинается с корня- неправильно определен разряд прилагательного, глагольная и отглагольная формы- не учтен лексическо-синтаксический контекст.- расхождение между буквенным и буквенно-звуковым составом словоформы.
София-Анна
У дочки отличная учительница русского. Она привила детям любовь к языку. И даже я участвую в процессе разбора слов в предложении. Для нас это увлекательный кроссворд и тренировка ума. После выполнения всех пунктов проверяем работу, воспользовавшись опцией морфемный разбор онлайн на сайте. Если дочка делает задание сама, без нас, то тоже пользуется этим сайтом для трудных слов. А их в нашем языке много. Например, в неизменяемых словах вообще нет окончания. А их можно определить, лишь четко разобравшись, какая именно часть речи нам дана. В основном, это наречия. Или другая категория неизменяемых слов. В ней трудности возникают с иностранными несклоняемыми существительными. Дети часто ошибаются, приписывая им несуществующие окончания или суффиксы. Валентина
Богатство и безграничность русского языка поражает. У русского языка очень богатый словарный запас и в нем много загадочности и необычности. Морфемный разбор очень интересно проводить, находить первоначальный источник слова, а также отделять приставки и суффиксы, окончания. В наше современное время на помощь может прийти онлайн словарь разбора слова по составу бесплатно. Онлайн словарь полезен тем что, произведя разбор и если сомневаемся в верности выполнения, есть возможность проверить себя вбив в строку поисковика «разбор слова по составу словарь онлайн бесплатно в интернете». Довольно сложно производить разбор слов,которые пришли к нам с другого языка или старославянские слова. Благодаря онлайн словарю все становится довольно легко и просто. Елена Helen
Век живи — век учись. Дочка ходит в старшие классы и периодически ставит своими вопросами по русскому языку нас с женой в тупик. Ну, на пример, определениями типа нуль-морфемная единица. Ладно, когда просто пытаешься вспомнить было у тебя это в твое время в школе либо не было и смотришь по ее учебнику, чему сейчас детей учат. Но хуже, когда она приносит домашнюю работу и просит проверить. Вот тут становится весело если одобрил, а оказалось неправильно, то за плохую оценку уже виновата не она, а родители. Более того авторитет страдает. Вот и приходится, на старости лет, лазить по бумажным словарям, в которых всяких морфемных разборов отродясь не было. Спасибо, slovoline, в интернете обнаружил. Теперь периодически пользуюсь в подобных щекотливых ситуациях. Дмитрий
Не зря, русский язык, признан одним из самых трудноизучаемых наравне с китайским. Но увы, школьные знания с возрастом забываются и с каждым прошедшим годом, правила все больше стираются из памяти. И когда тебе, внезапно, приходиться столкнуться с задачей по разбору слова или предложения, ты в ступоре смотришь на задачу и лихорадочно пытаешься систематизировать обрывки школьных знаний, но ничего не выходит и ты тайком, что-бы никто не увидел, пишешь в поисковике разобрать по составу слово онлайн.Интернет значительно упростил повседневную жизнь, но к величайшему сожалению, он убивает язык. Вам наверное доводилось не единожды с горечью замечать как общаются наши дети в сети: прив, ок, пок и т.д. И поэтому, огромная благодарность создателям подобных ресурсов за их старания. Антон80
Добрый день. Просьба разобрать слово по составу КОРЕШОЧЕК и если есть возможность выслать на емэйл fontan83mail.ru очень нужно задали в школе а никто помочь не может Сергей П
Богат и сложен великий русский язык.Особенно трогает глубина его морфемной структуры. Мы — взрослые русскоговорящие совсем не замечаем натуральных сложностей построения слов родной речи. А вот если только представить, как сложно бывает иностранцам… Хотя и нам приходилось когда-то учиться. Все были детьми.Очень интересный и полезный ресурс о правилах морфемного разбора слов русского языка. zinaya-sad
Невидимка.
Отмечаем окончание пишется раздельно,но сайт хороший.Сайт скучный поработайте над ним.Число букв в написании сообщения слишком много,сделаете поменьше вдруг кому-то это поможет.как я говорила сайт хороший,но много чего не хватает.Спасибо за внимание и понимание Невидимка.
Очень хороший и правильный сайт! Я просто восхищена и горжусь им! Так и надо держать! Очень полезный самое главное без ошибок! Советую вам и для ваших детей! Я не знаю его:(
блин, прикройте лучше вашу отстойную лавочку, я у вас так часто полный бред нахожу. Где вы, грамотеи, видели, чтоб «танцор» полностью попадал в корень??? от какого слова тогда он, интересно, произошел? йцукенг
Попробовала данный словарь на деле. Могу предложить доработать логику сервиса так, чтобы воспринимались и слова, полностью напечатанные в окне ввода. Сейчас для выполнения морфемного разбора слова после введения нескольких букв его необходимо выбрать из списка. Если же напечатать слово для разбора, несмотря на наличие в списке, оно не вылавливается в словаре и его разбор не показывается. Хотя это неудобство сполна перекрывается неоценимой услугой, которую каждый получает, используя сервис, предоставляющий разбор слова по составу. Словарь онлайн разработан с учетом практически всех языковых нюансов и поможет как ученикам оценки подтянуть по русскому, так и ассам свои знания проверить. Самоконтроль не помешает, ведь русский может преподнести сюрприз даже знатокам. Дарья Бильчик
Я работаю с наборами текстов и мне морфемный разбор онлайн, который я нашел на этом сайте очень помогает в работе. Насколько хорошо я знаю русский язык и то иногда приходится заглядывать в словарь, чтобы правильно составить тексты на русском языке. Очень просто и легко можно найти самые сложные словосочетания. Часто проверяю себя используя эти знания. Я считаю, что это онлайн словарь просто незаменим как профессионалам,так и просто ученикам школ для изучения русского языка. Рекомендую своим знакомым. Максим Говоров
Этот словарь хорошее вспомогательное пособие. Узнать слово по составу онлайн такая потребность появляется при наличии трудностей разбора или сомнений. Здесь представлены разные речевые морфемы, некоторые сложны из-за нетипичного словообразования. Никогда не вызывает вопросов только разбор междометий или служебных слов, ведь в их составе нет вспомогательных частей, только корень. Примеры: если, но, когда, алло, ах и т. д. Кузнецова Ирина
Olkezay
Столько познавательного я нашла на этом сайте. Очень помогает для детального изучения грамматики, очень просто работать. Русский язык очень сложный для изучения и много нового сейчас появилось в последнее время. Мне очень помогает звуко буквенный разбор слова, который я нашла на этом сайте для учебы. Я учусь на филологическом факультете.Теперь уже и мои сокурсники пользуются этим онлайн словарем. olga gukol
Предлагается «Словарь морфемных разборов» онлайн. Это словарь разборов слов по составу. Он содержит анализ морфемной структуры более 2300 слов, отобранных по поисковым запросам посетителей нашего сайта. Словарь постоянно пополняется Tekilka
Недавно у сына в школе проходили «Разбор слова по составу» по русскому языку, довелось вспомнить все свои знания и покопаться в интернете. Хорошую подсказку я получила именно на этом сайте, изучая морфемный разбор слова. Теперь и ребенок стал разбираться, где основа слова, где окончание, а где корень и приставка с суффиксом. Самое понятное, что слово надо разбирать в той форме, как оно написано в тексте, а уже далее распределить на части из которых оно состоит. СловарьОнлайн
Я учусь на филологическом факультете и для меня просто был находка этой онлайн словарь.Звуко-буквенный разбор слова применяется очень легко. Пользоваться таким словаре сможет даже школьник, а самое главное, что при применении такого словаря знания закрепляются в памяти отлично.Сейчас среди моих одногрупников очень стало популярным пользоваться этим словарем в самостоятельных заданиях и на курсовых. Ангелина
Правильное определение морфем слова — нелегкая наука для любого, но достоверность сервиса не абсолютна, так как автоматический анализ подвержен ошибкам. Так же, как морфологический разбор слова онлайн этого сервиса содержит неточности. Например, не уточняется особое свойство глаголов -дать- и -есть-, склоняющихся по отличающемуся от общего типу. Это нюансы, которые являются значимыми, это нужно учесть при пользовании данными словарями. Ирина Леонидовна
Морфемный разбор слова позволяет увидеть все составляющие элементы слова. На просторах интернета нашла этот сайт, на котором собрано большое количество словарей и интересных статей. В этой статье очень грамотно и популярно описан алгоритм морфемного разбора слова. Также предложен онлайн-сервис, который разберет слова на составные части без участия человека. Очень удобный сервис для ленивых учеников. Екатерина
Я живу в Украине и учусь в русской школе. Для грамотного написания текстов очень важно уметь делать морфемный разбор слова. Наша учительница по русскому языку подсказала на о существовании онлайн -словаря и пояснила как с ним работать.Теперь я делаю морфемный разбор слова онлайн бесплатно. Это мне помогает в моей учебе. Составлен он очень легко, пояснения легко воспринимаются. Большая помощь мне в процессе обучения. Ольга Василенко
В русском языке таких слов очень много. На мой взгляд морфемный разбор слова отличная возможно понять, откуда произошло то или иное слово. Узнать корень слова и так далее. К примеру, многие кулинарные слова произошли от французских слов, слышал об этом. Кроме того, когда есть возможность разобрать слово онлайн, это еще легче. На это не теряешь время, да и ошибок точно не сделаешь. Стараемся чаще пользоваться сервисом, и очень нравится. Александр
Морфемный анализ требует глубокого изучения происхождения слов. Они со временем видоизменяются, теряются родственные связи, как результат — множество расхождений у разных авторов словарей. По этой причине морфемный разбор слов онлайн не может даже теоретически претендовать на абсолютную точность, основываясь только на одном словообразующем словаре. А словообразование — определяющий фактор при выделении словообразующих морфем и основы. Ирина Леонидовна
Мы с другом с недавнего времени учимся на филологическом факультете нашего университета. Во время сдачи первой сессии, при подготовке курсовых работ возникла проблема с морфемикой. Благо друзья подсказали нам о существовании этого необыкновенного онлайн словаря! Теперь морфемный разбор слова по составу стал для нас необычайно легким заданием, а все курсовые были защищены на отлично! Теперь советуем данный сайт всем одногруппникам. Игорь Петров
Я сейчас преподаю русский язык в старших класса и к разбору приходится очень часто обращаться, чтобы научить школьников грамотно писать. Сейчас появились хорошие возможности использовать этот словарь, чтобы делать морфемный разбор слова онлайн. Мне и моим ученикам это очень удобно, потому что можно воспользоваться в нужной ситуации из-за его доступности. Теперь любой спорный вопрос можно разобрать при помощи словаря. Стефания.
Очень нам помогает онлайн версия. Особенно, когда садимся заниматься или играем, какую-то игру. Особенно нравится разбираться слова по составу, хотя иногда ошибаемся, но на ошибках учатся. Часто подглядываем сюда, чтобы точно знать, что делаем все правильно. Кроме того, в русском языке столько слов, что разбирать можно годами. Появились и новые слова, которые не знакомы, а разбирать их еще интересней. Евгений
Я сейчас использую в своей работе со своими учениками в школе словарь, который находится на этом сайте, для более грамотного написания разбора слов по составу онлайн- это очень удобно. Полученные знания легко запоминаются, много в таком словаре содержится информации. Потом мне очень удобно, что этот словарь очень доступен,в нашей школе есть интернет и дети им могут воспользоваться в любое время. Виктория Вячеславовна
В современном обиходе много слов, потерявших свои изначальные корни. Поэтому разбор слов по составу может не опираться на этимологию, что вызывает разногласия при выделении морфем. Это также объясняет присутствие неоднозначных мнений, тождественны ли понятия однокоренных слов и родственных. Например, -медведь- образовалось от объединения 2-х корней -мед- и -вед-. Но сейчас слова мед и ведать не относят к его однокоренным. Ирина Леонидовна
Морфемный разбор по составу онлайн поможет однозначно определиться с тем, к какой части речи относится выбранное слово. После него без особого труда есть возможность найти окончание и отделить его от основы для дальнейшего разбора. Этот шаг даст нам возможность путем подбора однокоренных слов выделить корень и в последующем найти уже служебные морфемы — приставки и суффиксы, причем быстро и удобно. СловарьОнлайн
Выделение морфем для учеников содержит значительные трудности. Хотя есть аффиксы, довольно распространенные. Разбор по составу легче для учащихся, имеющих четкое понимание о служебных словообразующих частях. Школьники должны знать морфемы, наиболее распространенные при формировании новых речевых частей от производящих, какая их лексическая функция — то значение, которое с их помощью придается полученным словам. Ирина Леонидовна
Я сейчас ознакомилась с этим сайтом. Преподаватели русского языка подсказали мне о нем. Для преподавания русского языка материал о разбор слова онлайн,расположенный здесь большая помощь в работе. Очень удобно со словарем работать, для грамотности написания он просто большой помощник.Теперь буду работать со своими учениками, используя этот онлайн словарь. Сейчас в школе WI-FI и таким словарем можно воспользоваться в работе. Александра
Я преподаю в русской школе на Украине. С этим сайтом я ознакомилась только сейчас. Мне понравилось как легко и просто можно воспользоваться разбором слова в этом онлайн справочнике. Тема очень сложная и важная в грамотности написания. Теперь буду обязательно рекомендовать моим ученикам, потому что сейчас есть интернет везде и в любое время при работе над текстами можно воспользоваться этим словарем. Юлия Иваниченко.
Русский язык постоянно совершенствуется и приходится постоянно повышать уровень знаний. Мне знакомые подсказали знакомые о словаре, где можно сделать разбор слова по составу онлайн бесплатно. Я работаю с документами и рассмотрев возможности этого словаря, а самое главное его еще и доступности в любое время, простоты в использовании словаря, я понял о целесообразности воспользоваться им в моей работе. Станислав
Грамотно излагать свои мысли в письменной или усной формах невозможно без знаний правил словообразования. На данном сайте выполнить разбор слова по составу онлай позволит быстро установить, какое будет, например, окончание в конкретном термине, как употребить слово во множественном числе, составить сложные слова и т.д. Сократить время на создание текстового сообщения и сберечь нервные клетки — это реальная помощь не только учащимся школ, но и студентам, преподавателям, специалистам-лингвистам и многим другим. СловарьОнлайн
Многие думают, что определить основу, делая морфемный разбор, просто. Нашел окончание осталась основа. Однако разобрать по составу любую часть речи нелегко из-за нюансов, каких много. Они вызывают частые ошибки. Например, формообразующие суффиксы -е-, -ее- и другие, участвующие в сравнительной степени прилагательных: выше, сильнее, смелее, тяжелее и т. д., — имеют особенность. Они не являются составляющими основы. Ирина Леонидовна
Я ознакомился с разбором слов по составу онлайн на этом сайте. Собрано много полезной информации, которая логично обобщена в этом словаре. Русский язык постоянно совершенствуется, поэтому пользование таким словарем онлайн необходим мне как для работающего с документами в моей работе. Работать с ним мне очень легко, все понятно, легко разобраться. Теперь буду обязательно применять в моей работе этот словарь. Олег Васильев
Работая в Украине, имею отношение к документации, безусловно напечатанной на украинском языке, но каждодневный язык — русский. И русский язык, и украинский активно развиваются. Велико разнообразие слов иностранного происхождения в современном языковом «арсенале». Когда встречаешь слово впервые, а его смысл понимаешь не сразу, появляется необходимость разобрать по составу слово. А благодаря обобщенной на данном сайте информации, крайне просто вспомнить принципы этого разбора. МарияМария
На сегодняшний день, мы проблем, чтобы разобрать слово по составу онлайн не наблюдаем, но грамматику нужно подтягивать. Очень трудно вспомнить школьную программу, которая была у нас много лет назад. Приходится искать онлайн-помощников, чтобы не было проблем с разбором слова и так далее. Особенно помогает морфемный разбор слова, об этом давно уже мы позабыли с женой. Продолжаем просвещаться на ресурсе. Валерий Чалов
В статье в начале сайта пишется не ростут, а растут!Стыдно…И почему сообщение должно быть из 150 символов!?.Сайт конечно хороший,вот только есть некоторые проблемы #Виктор
Корневая морфема несет на себе самую существенную функцию. Разбирая слово по составу, можно отметить, что корень, служащий общей для всех однокоренных морфемой, все-таки обладает свойством видоизменяться. Происходит это вследствие чередования, сложившегося исторически, среди типов которого особенно сложная замена гласного (согласного) комбинацией двух гласных (согласных): бить — бой (чередуются -и- с -ой-), ловить — ловлю (-в- с -вл-). Ирина Леонидовна
Мне приходится часто использовать в работе онлайн -словарь. О нем мне подсказали мои коллеги учителя. Мои ученики трудно усваивали тему морфемного разбора слова, но без этого знания вопроса трудно научить их грамотному написанию. Теперь я научил их пользоваться разбором на состав слова онлайн. Делать его на этом сайте легко, могут разобраться и младшие школьники, очень удобен в использовании. И усвоение темы стало продвигаться. Сергей Волков
Сколько не изучаешь русский язык, но иногда встречаются моменты, когда за правильностью написания стоит обращаться в словарь. В это онлайн словаре разбор слов по составу рассмотрен детально, здесь можно найти все ответы в вопросе правильного написания.Поэтому мне удобно и легко пользоваться онлайн- словарем, он всегда под рукой, составлен просто и информация, изложенная в нем в легкодоступной форме. Ваталий
Разобрать слова по составу онлайн, на первый взгляд все очень просто, на самом деле без помощи Вашего сайта нам не обойтись, главное найти корень слова, а дальше все намного сложнее, поэтому и обращаемся за помощью на сайт,домашнее задание теперь у нас только на одни пятерки,морфемный разбор слова по составу теперь для нас с сыном не проблема, домашние задание одно удовольствие делать теперь с ребенком. Наталья
Встречаются составляющие слов, отличающиеся от остальных, — интерфиксы, которые по своей роли не существенны и не относятся к классическим морфемам. Самый известный их вид это соединительные гласные между 2-х корней. Они встречаются, когда анализируешь сложные слова по составу онлайн, например, -самолет-. Здесь ни в одну морфему соединительная -о- не включается, при этом входит в основу, не прерывая ее. Кузнецова Ирина
Вы бы сначала выучите правила русского языка, а потом сайт создавали («ростут» во второй строчке). Правописание корней -раст- , -ращ- и -рос-: перед буквами и сочетаниями -ст- и -щ- пишется -а-, в противном случае пишется -о-. Ленапрлоплвыаоп
Требуются деньги на короткий срок? http://bit.ly/2GmqZAl — дать деньги в долг Выдача кредита онлайн на карту за 15 мин. Смотрите здесь: http://bit.ly/2DTmAX2 _z Craignes
я ебу собак, всегда готов сразу трахнуть несколько котовя ебу собак, всегда готов сразу трахнуть несколько котовя ебу собак, всегда готов сразу трахнуть несколько котовя ебу собак, всегда готов сразу трахнуть несколько котовя ебу собак, всегда готов сразу трахнуть несколько котовя ебу собак, всегда готов сразу трахнуть несколько котов я ебу собак, всегда готов сразу трахнуть несколько котов
Оставьте Ваше пожелание к сайту, или опишите найденную ошибку в статье о Разбор по составу (морфемный)
МОРФЕМНЫЙ
морфе
мный
Полный орфографический словарь русского языка.
2012
Смотрите еще толкования, синонимы, значения слова и что такое МОРФЕМНЫЙ в русском языке в словарях, энциклопедиях и справочниках:
- МОРФЕМНЫЙ в Полной акцентуированной парадигме по Зализняку:
морфе»мный, морфе»мная, морфе»мное, морфе»мные, морфе»много, морфе»мной, морфе»много, морфе»мных, морфе»мному, морфе»мной, морфе»мному, морфе»мным, морфе»мный, морфе»мную, морфе»мное, морфе»мные, морфе»много, морфе»мную, морфе»мное, морфе»мных, … - МОРФЕМНЫЙ в Новом толково-словообразовательном словаре русского языка Ефремовой:
прил. 1) Соотносящийся по знач. с сущ.: морфема, морф, связанный с ними. 2) Свойственный морфеме, морфу, характерный для них. 3) … - МОРФЕМНЫЙ в Словаре русского языка Лопатина.
- МОРФЕМНЫЙ в Орфографическом словаре.
- МОРФЕМНЫЙ в Толковом словаре Ефремовой:
морфемный прил. 1) Соотносящийся по знач. с сущ.: морфема, морф, связанный с ними. 2) Свойственный морфеме, морфу, характерный для них. … - МОРФЕМНЫЙ в Новом словаре русского языка Ефремовой:
прил. 1. соотн. с сущ. морфема, морф, связанный с ними 2. Свойственный морфеме, морфу, характерный для них. 3. Принадлежащий … - МОРФЕМНЫЙ в Большом современном толковом словаре русского языка:
прил. 1. соотн. с сущ. морфема, связанный с ним 2. Свойственный морфеме, характерный для нее. 3. Принадлежащий … - МОРФЕМНЫЙ АНАЛИЗ в Словаре лингвистических терминов:
Выделение в слове всех живых с точки зрения современного языка морфем. ср. : разбор словообразовательный (в статье разбор) и … - МОРФЕМА в Энциклопедическом словарике:
ы, ж., лингв. Наименьшая значащая часть слова (корень, аффикс). Морфемный — относящийся к морфеме, мор-фемам.||Ср. ФЛЕКСИЯ, ФОРМАНТ … - МОРФЕМА в Энциклопедическом словаре:
, -ы, ж. В языкознании: минимальная значимая часть слова (корень, приставка, суффикс, постфикс). II прил. морфемный, -ая, … - УРОВНИ ЯЗЫКА
—некоторые «части» языка; подсистемы общей системы языковой, каждая из к-рых характеризуется совокупностью относительно однородных единиц и набором правил, регулирующих их … - МОРФЕМИКА в Лингвистическом энциклопедическом словаре:
— морфемный строй языка, совокупность вычленяемых в словах морфем и их типы; раздел языкознания, изучающий типы и структуру морфем, их … - ЛЕКСИКОГРАФИЯ в Лингвистическом энциклопедическом словаре.
- ЕДИНИЦЫ ЯЗЫКА в Лингвистическом энциклопедическом словаре:
—элементы системы языка, имеющие разные функции и значения. Совокупности основных Е. я. в узком смысле этого термина образуют определ. «уровни» …
Разбор слова по составу.
Состав слова «онлайн»:
Морфемный разбор слова онлайн
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова онлайн делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова онлайн – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для онлайн (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы для онлайн путем подбора других слов, которые образованы таким же способом, что и онлайн.
Как вы видите, морфемный разбор онлайн
делается просто. Теперь давайте определимся с основными морфемами слова онлайн и сделаем его разбор.
См. также в других словарях:
Просклонять слово онлайн по падежам в единственном и множественном числе…. Склонение слова онлайн по падежам
Полный морфологический разбор слова «онлайн»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор онлайн
Ударение в слове онлайн: на какой слог падает ударение и как… Слово «онлайн» правильно пишется как… Ударение в слове онлайн
Синонимы «онлайн». Словарь синонимов онлайн: подобрать синонимы к слову «онлайн». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову онлайн
Как разобрать по составу слово «земляничный»?
Чтобы разобрать по составу слово «земляничный», установим, к какой части речи оно принадлежит.
Слово «земляничный» обозначает признак предмета и отвечает на вопрос: какой?
По этим грамматическим признакам, выясним, что это прилагательное, которое может менять свою форму:
- земляничн-ая поляна
- земляничн-ое место
- земляничн-ые опушки.
Сравнив эти формы, вычленим в составе рассматриваемого прилагательного словоизменительную морфему -ый, которая не включается в основу — земляничн-. Далее укажем суффикс -н-, с помощью которого было образовано это прилагательного от однокоренного существительного:
земляника — землянич-н-ый.
Эту душистую ягоду назвали в связи с тем, что она растет близко к земле:
земля — земл-ян-ой — землян-ик-а — землянич-н-ый.
Словообразовательная цепочка наглядно продемонстрировала все суффиксы, которые следует выделить в составе анализируемого прилагательного. Корнем является морфема земл-, которую можно заметить в составе родственных слов:
- землянка,
- землянин,
- заземлить,
- заземление,
- приземлиться.
Сделаем вывод
В результате разбора по составу слово «земляничный» можно представить в виде схемы:
земл—ян—ич-н—ый — корень/суффикс/суффикс/суффикс/окончание
Земляничный дождик
Выглянуло солнце. Под каждым деревом блестели новенькими шляпками грибы.
-Грибной дождь — это мой! — сказал Лисёнку Ёжик, накалывая на свои иголки гриб за грибом.
-А мой — Земляничный! — ответил Лисёнок.
-А мой — Сырррный! — каркнула с ветки Ворона. — Вот бы пошёл сырррный дождик.
-А для меня — Морковный, — появился в кустах Заяц. — Только где его возьмёшь?..
Фарбаржевич И.Д. «Сказки маленького Лисёнка»
Скачать статью: PDFЗначение
— как говорящий «разбирает» свои комментарии?
Трудно отклонить это как совпадение, учитывая, что Коэн — юрист и тщательно проанализировал его комментариев в этой ситуации. Он регулярно предлагал то, что казалось отрицанием, но не отрицал полностью деталей того, о чем писал журнал.
Адвокат Трампа только что замешал Трампа в выплате Сторми Дэниэлса?
Что здесь означает parse ?
Я видел подобное использование в журналистике, где:
- Это больше относится к выражению (или даже к продукту выражения), а не к анализу.
- Иногда имеет значение уклончиво , запутать или притвориться .
Для меня традиционное определение здесь не совсем подходит:
Коэн — юрист, и тщательно изучил / проанализировал (подробно) его комментариев в этой ситуации.
Но я тоже не могу придумать синоним авторского значения.
Другое применение
Самые ранние , которые он проанализировал в своих словах , которые я нашел, датируются 1998 годом:
Буш тщательно проанализировал свои слова , в отличие от рожденного свыше христианина.
Таких стало много с 2000 года (спасибо @GetzelR). Я слышу, что они почти идентичны . Он тщательно подбирал слова .
Но есть несколько похожих на мой оригинальный отрывок.
Re. Описание политической ссылки (2004):
Аристид очень ясно дал понять, что то, что произошло на Гаити, было современным похищением […] Он был зол и решителен, очень прямолинеен и никогда не разобрал своих слов ».
Re.Позиция Теда Круза по иммиграции (2015):
Как ловкий адвокат, Круз разбирал свои слова по вопросу об амнистии
[…] Как можно догадаться, правдивость заявления Круза во многом зависит от того, что он подразумевает под «легализацией».
Re. Запрет президента Трампа на поездки — это не запрет на поездки (2017 г.):
Спайсер появился перед СМИ после первого распоряжения и изо всех сил попытался проанализировать слов .[…] «Это не запрет. Это нужно для того, чтобы убедиться, что люди, которые приходят, проверены должным образом … запрет будет означать, что люди не могут войти ».
Re. Вступительные показания Джеймса Коми (2017):
Я думаю, что в этой формулировке есть что-то для всех. Там достаточно, чтобы республиканцы нападали на бывшего директора Коми и защищали президента, и там достаточно, чтобы демократы защищали бывшего директора Коми и нападали на президента.[…] Там много парсинга слов.
Постоянный округ против анализа зависимостей | Лукас Кохорст
Разбор предложений может быть полезен для понимания значения, структуры и синтаксических отношений в предложениях. Два распространенных типа — это анализ зависимостей и констант, который также известен как синтаксический анализ. Анализ зависимостей — это процесс определения грамматической структуры предложения путем перечисления каждого слова в качестве узла и отображения ссылок на его зависимые элементы.Дерево анализируемого округа отображает синтаксическую структуру предложения с использованием контекстно-свободной грамматики. В отличие от синтаксического анализа зависимостей, который опирается на грамматику зависимостей. Оба типа синтаксического анализа важны в компьютерной лингвистике, но есть много споров о том, какой из них лучше. Критики синтаксического анализа избирателей говорят, что он отображает постороннюю информацию, в то время как сторонники предпочитают визуализировать всю структуру предложения, а не только грамматические зависимости.
Я создал визуализатор дерева предложений зависимостей и постоянных клиентов, чтобы проанализировать две системы синтаксического анализа, опубликованные как пакет NPM, дерево реакции-предложений.Этот проект основывался на использовании React в качестве веб-фреймворка, Stanford CoreNLP в качестве сервера синтаксического анализа и response-d3-tree для визуализации проанализированных предложений. Используя эти технологии, я создал пакет Node.js с открытым исходным кодом, который другие разработчики могли использовать и расширять вместе с демонстрационным веб-приложением. С помощью этого пакета я протестировал различные предложения, такие как фрагменты предложений, непроективные и двусмысленные предложения, чтобы сравнить и сопоставить анализ констант и зависимостей.
Синтаксический анализ округа очень полезен для визуализации всей синтаксической структуры предложения.Эти деревья синтаксического анализа могут быть полезны в системах обработки текста для проверки грамматики. Например, очень сложно разобрать грамматически неправильное предложение. Это связано с тем, что, если предложение не может быть проанализировано, программа может сделать разумное предположение, что предложение содержит некоторые грамматические ошибки. Однако чаще всего синтаксический анализ аудитории используется как представление предложения и играет роль в извлечении информации. Например, определение предмета предложения.
Самая большая проблема, возникающая при синтаксическом анализе избирательных округов, — это структурная неоднозначность.Это происходит, когда есть несколько грамматических интерпретаций предложения. Предложение «Я застрелил слона в своей пижаме» — обычное предложение, которое лингвисты используют для демонстрации двусмысленности. Есть несколько способов понять предложение (хотя один явно смешон). Либо в слона застрелили, когда человек стоял в пижаме, очевидно правильная интерпретация. Или слона застрелили внутри пижамы человека. В этом примере есть структурная двусмысленность вокруг слова «выстрел», если «выстрел» разбирается как глагол само по себе, предложение передаст юмористический смысл.При правильном синтаксическом анализе слово «выстрел» должно быть проанализировано как глагол, вложенный в глагольную фразу с соответствующей именной фразой «слон».
Это пример структурной двусмысленности, поскольку «выстрел» может быть присоединен к предложению как глагол или содержаться как глагол внутри глагольной фразы. Другой распространенный тип двусмысленности связан с координацией. Когда фразы содержат союз, такой как «и» или «но», они могут быть предметом координационной двусмысленности. Например, фраза «Здесь все старики и бабы».Это предложение можно понять как все здесь старики или старухи, но его также можно разобрать, так как все здесь старики или женщины.
Синтаксический анализ постоянных групп может быть достигнут с помощью нескольких алгоритмов: алгоритм Кок-Касами-Янгера (CKY), вероятностный восходящий подход является популярным подходом наряду с алгоритмом вероятностных контекстно-свободных грамматик (PCFG).
Мой проект опирался на CoreNLP Стэнфорда, который использует алгоритм сокращения сдвига для синтаксического анализа, прежде всего потому, что он более эффективен, чем PCFG или CKY.Уменьшение сдвига — это стековый подход к синтаксическому анализу с использованием контекстно-свободной грамматики. Все токены в предложении помещаются в стек, затем два верхних токена извлекаются, сопоставляются с правилами грамматики и помещаются обратно в стек в уменьшенном виде.
У парсеров округа есть проблемы с двусмысленными предложениями, поэтому я решил проверить такие предложения, как «Я застрелил слона в своей пижаме» и «Я застрелил слона в пижаме». Есть две интерпретации этих предложений, как описано выше.Синтаксический анализатор избирательного округа правильно проанализировал оба предложения как не юмористический. Другие неоднозначные предложения, такие как «Я видел человека на холме в телескоп», также обрабатываются должным образом. Помимо двусмысленности, ошибки синтаксического анализа обычно могут возникать из непроективных предложений или предложений, в которых возникают дальние синтаксические ошибки.
Одна проблема, связанная с синтаксическим анализом избирательного округа, заключается в том, что для использования общих алгоритмов, таких как CKY, предложение должно быть в нормальной форме Хомского (CNF).Это недостаток, потому что часто бывает трудно преобразовать языки со свободным порядком слов, например многие славянские языки. Эту проблему можно решить, используя грамматику ролей и ссылок (RRG), а не контекстно-свободную грамматику, преобразованную в CNF. Главная особенность ролевой и справочной грамматики заключается в том, что в ней используется лексическая декомпенсация. Лексическая семантика — это слова, подслова и единицы слов. RRG разбивает предложение на лексические части и, используя анализ структуры предложения, формирует иерархию предложений.Ролевая и справочная грамматика менее популярна, чем анализ аудитории, но дает преимущество, заключающееся в возможности легко анализировать языки со свободным порядком слов.
Анализ зависимостей отличается от синтаксического анализа, поскольку он использует грамматику зависимостей и отображает только отношения между словами, а не структуру предложения и отношения. Деревья зависимостей часто более краткие, чем деревья округов, потому что они отображают только грамматику между губернатором и зависимыми. Подобно синтаксическому анализу аудитории, зависимость полезна в системах обработки текста и проверке грамматики.
Общие алгоритмы, используемые при синтаксическом анализе зависимостей, — это алгоритмы поиска в банке деревьев, такие как Arc-eager или поиск луча, подходы на основе графов, такие как на основе ребер, или с использованием нейронной сети, которую использует Stanford CoreNLP, и то, что я использовал в дереве предложений реакции .
Одно из ключевых преимуществ синтаксического анализа зависимостей по сравнению с постоянным составом состоит в том, что он имеет возможность анализировать относительно свободный порядок слов. Это позволяет анализировать такие языки, как латынь, в которой нет фиксированного порядка. Анализ зависимостей также лучше работает при анализе непроективных и фрагментированных предложений.Преимущество синтаксического анализа избирательных округов перед синтаксическим анализом избирательных округов заключается в его способности отображать всю структуру предложения, а не просто словесные ассоциации.
При разработке и тестировании своего приложения я столкнулся с несколькими ограничениями и ошибками. Первое ограничение заключается в том, что в настоящее время проект поддерживает только синтаксический анализ английского языка, однако у меня есть идеи о том, как расширить языки, доступные в будущем. Интересный аспект заключается в том, что если есть несколько интерпретаций предложения (т.е. если предложение неоднозначное) синтаксический анализатор отображает только одно из них и не информирует пользователя о других интерпретациях. Это можно увидеть на примере слона сверху. Распространенная интерпретация того, что мужчина в пижаме, — это нарисованное дерево. Я хотел бы проинформировать пользователя о количестве возможных синтаксических анализов и позволить им выбрать, какой синтаксический анализ они хотят визуализировать. Еще одна интересная ошибка в программе заключается в том, что последняя введенная буква не анализируется и не отображается в дереве.У меня такое ощущение, что это связано с тем, как в моем приложении обрабатывается состояние. Эта ошибка не влияет на то, как анализируется предложение, поскольку это последняя буква в предложении, но может ввести пользователя в заблуждение.
Анализ постоянных групп и зависимостей имеет много общих характеристик в том, как и что они могут анализировать. Многие из алгоритмов, таких как Shift-Reducer и использование нейронных сетей, обычно используются в обоих методах синтаксического анализа. Однако они различаются по тому, что они производят, и насколько они эффективны.Анализ зависимостей отображает только отношения между словами и их составными частями, в то время как анализ группы интересов отображает всю структуру предложения и взаимосвязи. Часто синтаксический анализ зависимостей хвалит за его краткость, но информативность, но синтаксический анализ аудитории часто легче читать и понимать. Работая над этим проектом, я узнал, что хотя у синтаксического анализа групп интересов и зависимостей есть свои различия и конкретные варианты использования. Они дают очень похожие результаты, и решение о том, какие использовать, в конечном итоге зависит от вас и ваших предпочтений.
Почему мы используем синтаксический анализ зависимостей
Для новичков анализ текста часто начинается с простого поиска по ключевым словам. Аналитики могут начать с поиска «отличный сервис». Затем они могут начать добавлять другие запросы, такие как «обслуживание было отличным» или «обслуживание настолько велико». Это, конечно, очень примитивный подход, при котором будет пропущено много релевантных комментариев, поэтому пользователи, которые хотят быстро получить больше результатов, будут переходить к поиску с близкого расстояния. Например, они могут искать «отличный» в трех словах «услуга».В то время как некоторые могут использовать списки слов («отличный», «хороший» или «отличный» сервис) или части речи (прилагательные рядом со словом «сервис») для улучшения результатов, большинство систем анализа текста останавливаются на этом.
Однако для расширенного поиска по тексту вам потребуется информация о соотношении слов. Например, «застрахованный водитель наехал на автобус» и «автобус наехал на застрахованного водителя» — это два очень разных события, которые могут помочь системе анализа текста определить, кто виноват в аварии. При базовом поиске можно попытаться найти первое событие, выполнив поиск «застрахованного водителя», «наезд» и «автобус» в указанном порядке, но что, если «застрахованного водителя сбил автобус»? Он совпадает, но это полная противоположность тому, что искал поисковик.
Конечно, есть способы восполнить недостаток знаний компьютера о соотношении слов. Например, мы могли бы изменить поиск, чтобы исключить любые предложения «попал». Но необходимо учитывать множество других факторов. Например, если мы не ограничиваем расстояние, мы правильно найдем, что «застрахованный водитель, который управлял красным Ford Focus 2008 года, попал в автобус». Однако мы также обнаружим, что «застрахованный водитель сообщил, что красный Ford Focus 2008 года врезался в автобус». Человеческий язык настолько богат и сложен, что практически невозможно точно объяснить все возможные выражения события, которое мы ищем, без некоторого более умного понимания структуры и отношений, связанных с соединением слов.
Синтаксический анализ зависимостей предоставляет эту информацию. Например, синтаксический анализ зависимостей может сказать вам, каковы субъекты и объекты глагола, а также какие слова модифицируют (описывают) подлежащее. Это может помочь вам найти точные ответы на конкретные вопросы, например:
Пилотировал ли истец на красный свет?
Информация о том, какая из сторон проехала на красный свет, может помочь нам определить, кто виноват в аварии. В этом случае «истец» является субъектом «пробега», который имеет объект «красный свет».Из этого мы можем сделать вывод, что «истец» является исполнителем действия «проезд на красный свет», и более вероятно, что истец виноват в том, что произошло дальше.
Какие активы скупают мои конкуренты?
Здесь мы видим, что в предложении, где Amazon является предметом, Whole Foods — это покупаемый объект. Синтаксический анализ зависимостей правильно идентифицирует это предложение, а также точно анализирует следующее:
В этом случае присутствует та же фраза («Amazon для покупки Whole Foods»), но объявляется другое приобретение.В данном случае покупается скорее конкурент Whole Foods, Trader Joe’s. Хотя эти крупные события (одно реальное, одно воображаемое) вряд ли останутся незамеченными, о многих небольших приобретениях конкурентов регулярно объявляется в непрочитанных публикациях и пресс-релизах.
Какое впечатление оставляют наши представители службы поддержки клиентов?
Для этого предложения синтаксический анализ зависимостей правильно определяет несколько частей информации об обслуживании клиентов — как о том, что обслуживание клиентов «выдающееся», так и о том, что обсуждаемое обслуживание клиентов относится конкретно к «техническому отделу».
Есть много способов использовать синтаксический анализ зависимостей для более точного запроса ваших текстовых данных. Конечно, есть много других тонкостей языка, но это темы для другого дня.
Анализ зависимостей — одна из функций PolyAnalyst, программного обеспечения для анализа текста Megaputer.
Постоянный округ против анализа зависимостей | Баелдунг по информатике
Мы открываем новую область компьютерных наук. Если у вас есть несколько лет опыта в области компьютерных наук или исследований, и вы заинтересованы в том, чтобы поделиться этим опытом с сообществом (и, конечно же, получать деньги за свою работу), загляните на страницу «Напишите для нас».Ура, Евгений
1. Введение
В этой статье мы поговорим о синтаксическом анализе групп интересов и зависимостей.
Чтобы проанализировать их различия, мы сначала посмотрим, как они работают, на простом примере. Затем мы поговорим о проблемах синтаксического анализа, а также о некоторых возможных вариантах использования.
2. Обзор
В компьютерной лингвистике термин синтаксический анализ относится к задаче создания дерева синтаксического анализа из данного предложения .
Дерево синтаксического анализа — это дерево, которое выделяет синтаксическую структуру предложения в соответствии с формальной грамматикой, например, раскрывая отношения между словами или вложенными фразами. В зависимости от того, какой тип грамматики мы используем, результирующее дерево будет иметь разные особенности.
Синтаксический анализ постоянных групп и зависимостей — это два метода, которые используют разные типы грамматик. . Поскольку они основаны на совершенно разных предположениях, результирующие деревья будут очень разными.Хотя в обоих случаях конечной целью является извлечение синтаксической информации.
Для начала давайте начнем с анализа дерева синтаксического анализа избирательного округа.
2.1. Анализ избирательного округа
Дерево синтаксического анализа избирательного округа основано на формализме контекстно-свободных грамматик. В этом типе дерева предложение делится на составные части, то есть на подфразы, принадлежащие к определенной категории грамматики.
В английском языке, например, фразы «собака», «компьютер на столе» и «красивый закат» — это все существительные, а «съесть пиццу» и «пойти на пляж» — это глагольные фразы.
Грамматика описывает, как строить правильные предложения, используя набор правил. Например, правило означает, что мы можем образовать глагольную фразу (VP), используя глагол (V), а затем именную фразу (NP).
Хотя мы можем использовать эти правила для генерации действительных предложений, мы также можем применять их и наоборот, чтобы извлечь синтаксическую структуру данного предложения в соответствии с грамматикой.
Давайте прямо рассмотрим пример дерева синтаксического анализа округа для простого предложения «Я видел лису»:
Дерево синтаксического анализа группы всегда содержит слова предложения в качестве конечных узлов. Обычно у каждого слова есть родительский узел, содержащий его тег части речи (существительное, прилагательное, глагол и т. Д.), Хотя это может быть опущено в других графических представлениях.
Все другие нетерминальные узлы представляют составные части предложения и обычно представляют собой глагольную фразу, именную фразу или предложную фразу (PP).
В этом примере на первом уровне ниже корня наше предложение разделено на существительную, состоящую из одного слова «I» и глагольной фразы «видел лисицу».Это означает, что грамматика содержит такое правило, как, означающее, что предложение может быть создано путем конкатенации именной и глагольной словосочетаний.
Точно так же глагольная фраза делится на глагол и другую именную фразу. Как мы можем себе представить, это также соответствует другому правилу грамматики.
Подводя итог, синтаксический анализ избирательного округа создает деревья, содержащие синтаксическое представление предложения в соответствии с контекстно-свободной грамматикой. Это представление очень иерархично и делит предложения на отдельные фразовые составляющие.
2.2. Анализ зависимостей
В отличие от синтаксического анализа группы интересов, анализ зависимостей не использует фразовые составляющие или подфразы . Вместо этого синтаксис предложения выражается в терминах зависимостей между словами, то есть направленных, типизированных ребер между словами в графе.
Более формально дерево синтаксического анализа зависимостей — это граф, в котором набор вершин содержит слова в предложении, а каждое ребро соединяет два слова. График должен удовлетворять трем условиям:
- Должен быть единственный корневой узел без входящих ребер.
- Для каждого узла должен быть путь от корня до.
- Каждый узел, кроме корня, должен иметь ровно 1 входящее ребро.
Кроме того, каждое ребро в имеет тип, который определяет грамматические отношения между двумя словами.
Давайте посмотрим, как будет выглядеть предыдущий пример, если мы выполним синтаксический анализ зависимостей:
Как видим, результат совсем другой. При таком подходе корнем дерева является глагол предложения, а ребра между словами описывают их отношения.
Например, слово «пила» имеет исходящую кромку типа nsubj по отношению к слову «я», что означает, что «я» является номинальным подлежащим глагола «пила». В этом случае мы говорим, что «I» зависит от «пилы».
3. Проблемы анализа естественного языка
При синтаксическом анализе естественного языка возникает несколько проблем, которые не возникают, например, при синтаксическом анализе языков программирования. Причина этого в том, что естественный язык часто неоднозначен, что означает, что для одного и того же предложения может быть несколько допустимых деревьев синтаксического анализа.
Давайте на минутку рассмотрим предложение: «Я застрелил слона в своей пижаме». У него есть два возможных толкования: в первом случае мужчина в пижаме стреляет в слона, а во втором — в пижаме мужчины.
Оба они допустимы с синтаксической точки зрения, но люди способны решать эти неоднозначности очень быстро — и часто бессознательно, — поскольку многие из возможных интерпретаций необоснованны с точки зрения их семантики или контекста, в котором встречается предложение.Однако для алгоритму синтаксического анализа не так просто выбрать наиболее вероятное дерево синтаксического анализа с большой точностью .
Для этого большинство современных синтаксических анализаторов используют модели машинного обучения с учителем, которые обучаются на вручную аннотированных данных. Поскольку данные аннотируются правильными деревьями синтаксического анализа, модель обнаружит предвзятость в сторону более вероятных интерпретаций.
4. Примеры использования
Итак, как мы решаем, что использовать между анализом группы интересов и анализом зависимости? Ответ на этот вопрос весьма ситуативен и зависит от того, как мы собираемся использовать информацию синтаксического анализа.
Анализ зависимостей может быть более полезным для нескольких последующих задач, таких как извлечение информации или ответы на вопросы .
Например, это упрощает извлечение троек субъект-глагол-объект, которые часто указывают на семантические отношения между предикатами. Хотя мы также могли бы извлечь эту информацию из дерева синтаксического анализа группы интересов, для этого потребуется дополнительная обработка, поскольку она сразу же доступна в дереве синтаксического анализа зависимостей.
Другая ситуация, когда использование анализатора зависимостей может оказаться полезным, — это работа с языками со свободным порядком слов. Как следует из названия, эти языки не устанавливают определенный порядок слов в предложении. Из-за природы лежащих в основе грамматик синтаксический анализ зависимостей в этом сценарии работает лучше, чем постоянная группа.
С другой стороны, , когда мы хотим извлечь из предложения подфразы, синтаксический анализатор округа может быть лучше .
Мы можем использовать оба типа деревьев синтаксического анализа для извлечения функций для модели контролируемого машинного обучения. Предоставляемая ими синтаксическая информация может быть очень полезна для таких задач, как разметка семантических ролей, ответы на вопросы и другие.В общем, мы должны проанализировать нашу ситуацию и оценить, какой тип синтаксического анализа лучше всего подходит для наших нужд.
5. Заключение
В этой статье мы увидели, как работает синтаксический анализ зависимостей и клиентов. Мы изучили их различия на простом примере и увидели, когда лучше всего использовать тот или иной.
Анализ текста с помощью PowerShell (1/3)
Это первая публикация из серии из трех частей.
- Часть 1 :
- Полезные методы класса String
- Введение в регулярные выражения
- Командлет Select-String
- Часть 2:
- Оператор -split
- Оператор матча
- Оператор переключения
- Класс Regex
- Часть 3:
- Реальный мир, полный и немного больший, пример синтаксического анализатора на основе переключателей
В моем рабочем процессе регулярно появляется задача синтаксического анализа текста.Это может быть получение токена из одной строки текста или преобразование вывода текста собственных инструментов в структурированные объекты, чтобы я мог использовать возможности PowerShell.
Я всегда стремлюсь создать структуру как можно раньше в конвейере, чтобы позже я мог рассуждать о содержимом как о свойствах объектов, а не как о тексте с некоторым смещением в строке. Это также помогает при сортировке, поскольку свойства могут иметь правильный тип, поэтому числа, даты и т. Д. Сортируются как таковые, а не как текст.
Пользователю PowerShell доступно несколько опций, и я дам обзор наиболее распространенных из них.
Это не текст о том, как создать высокопроизводительный синтаксический анализатор для языка со структурированной грамматикой EBNF. Для этого доступны лучшие инструменты, например ANTLR.
.Net методы в строке
класс
Любая обработка синтаксического анализа строк в PowerShell была бы неполной, если бы в ней не упоминались методы класса string .Есть несколько методов, которые я использую при синтаксическом анализе строк чаще других:
| Имя | Описание |
|---|---|
Подстрока (int startIndex) | Извлекает подстроку из этого экземпляра. Подстрока начинается с указанной позиции символа и продолжается до конца строки. |
Подстрока (int startIndex, int length) | Извлекает подстроку из этого экземпляра.Подстрока начинается с указанной позиции символа и имеет указанную длину. |
IndexOf (строковое значение) | Сообщает отсчитываемый от нуля индекс первого вхождения указанной строки в этом экземпляре. |
IndexOf (строковое значение, int startIndex) | Сообщает отсчитываемый от нуля индекс первого вхождения указанной строки в этом экземпляре. Поиск начинается с указанной позиции символа. |
LastIndexOf (строковое значение) | Сообщает отсчитываемый от нуля индекс последнего вхождения указанной строки в этом экземпляре.Часто используется вместе с Подстрокой . |
LastIndexOf (строковое значение, int startIndex) | Сообщает отсчитываемую от нуля позицию индекса последнего вхождения указанной строки в этом экземпляре. Поиск начинается с указанной позиции символа и продолжается в обратном направлении к началу строки. |
Это второстепенная часть доступных функций. Возможно, стоит потратить время на то, чтобы ознакомиться с классом строк, поскольку он является фундаментальным в PowerShell.Документы можно найти здесь.
В качестве примера это может быть полезно, когда у нас есть очень большие входные данные, разделенные запятыми, с 15 столбцами, и нас интересует только третий столбец с конца. Если бы мы использовали оператор -split ',' , мы бы создали 15 новых строк и массив для каждой строки. С другой стороны, использование LastIndexOf во входной строке несколько раз, а затем SubString для получения интересующего значения происходит быстрее и приводит только к одной новой строке.
function parseThirdFromEnd ([строка] $ line) {
$ i = $ line.LastIndexOf (",") # получить последний разделитель
$ i = $ line.LastIndexOf (",", $ i - 1) # получаем предпоследний разделитель, а также конец интересующего нас столбца
$ j = $ line.LastIndexOf (",", $ i - 1) # получаем разделитель перед нужным столбцом
$ j ++ # дальше вперед за разделитель
$ line.SubString ($ j, $ i- $ j) # получаем текст искомого столбца
} В этом примере я игнорирую, что IndexOf и LastIndexOf возвращает -1, если они не могут найти текст для поиска.По опыту я также знаю, что легко испортить арифметику индексов.
Таким образом, хотя использование этих методов может улучшить производительность, они также более подвержены ошибкам и намного больше требуют ввода. Я бы прибегал к этому, только когда знаю, что входные данные очень большие, а производительность является проблемой. Так что это не рекомендация и не отправная точка, а то, к чему нужно прибегать.
В редких случаях я пишу весь синтаксический анализатор на C #. Примером этого является модуль, оборачивающий систему управления версиями Perforce, где инструмент командной строки может выводить словари Python.Это двоичный формат, и вариант использования был достаточно сложным, поэтому мне было удобнее использовать язык реализации, проверенный компилятором.
Регулярные выражения
Почти все параметры синтаксического анализа в PowerShell используют регулярные выражения, поэтому я начну с краткого введения в некоторые концепции регулярных выражений, которые используются позже в этих сообщениях.
Регулярные выражения очень полезно знать при написании простых синтаксических анализаторов, поскольку они позволяют нам выражать интересующие шаблоны и захватывать текст, который соответствует этим шаблонам.
Это очень богатый язык, но вы можете пройти довольно долгий путь, изучив несколько ключевых частей. Я обнаружил, что regular-expressions.info является хорошим онлайн-ресурсом для получения дополнительной информации. Он не написан непосредственно для реализации регулярного выражения .net, но большая часть информации действительна для различных реализаций.
| Регулярное выражение | Описание | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
* | Ноль или более предшествующих символов. a * соответствует пустой строке, a , aa и т. Д., Но не b . | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
+ | Один или несколько предшествующих символов. a + соответствует a , aa и т. Д., Но не пустой строке или b . | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
. | Соответствует любому символу | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[ax1] | Любой из a , x , 1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
и др. | соответствует любому из a , b , c , d | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
\ w | Метасимвол \ w используется для поиска символа слова.Словесный символ — это символ от a до z, от A до Z, 0-9, включая символ _ (подчеркивание). Он также соответствует вариантам символов, например, ??? и ??? . | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
\ W | Инверсия \ w . Соответствует любому символу, не являющемуся словом | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
\ s | Метасимвол \ s используется для поиска пробелов | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
\ S | Инверсия \ s .Соответствует любому непробельному символу | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
\ d | Соответствует цифрам | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
\ D | Инверсия \ d . Соответствует нецифровому номеру | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
\ b | Соответствует границе слова, то есть позиции между словом и пробелом. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
\ B | Инверсия \ b . . er \ B соответствует er в глаголе , но не er в никогда .\ s + (? <число> \ d +), (? <текст>. +)Различные языки имеют решения для конкретных реализаций для доступа к значениям захваченных групп. Позже в этой серии мы увидим, как это делается в PowerShell. Командлет Select-String Команда Ключ к эффективности с Set-Content twitterData.-] +) - (\ d +) (@ \ w +) "|
Foreach-Object {
$ first, $ last, $ followers, $ handle = $ _. Соответствует [0] .Groups [1..4] .Value # это обычный способ получить группы вызова для строки выбора
[PSCustomObject] @ {
FirstName = $ first
LastName = $ last
Ручка = $ handle
TwitterFollowers = [int] $ подписчиков
}
} Поддержка нескольких шаблонов Как мы видим выше, только половина данных соответствует шаблону Разбивка на (? X) # это регулярное выражение игнорирует пробелы в шаблоне.-] +) # захватить один или несколько любых символов, кроме `--`, в группу с именем 'last' - # a '-' (? Второе регулярное выражение похоже, но с группами в другом порядке. Но поскольку мы получаем группы по имени, нам не нужно заботиться о позициях групп захвата, и множественное назначение работает нормально. Контекст вокруг совпадений Это может быть использовано для получения второй строки перед матчем: # используя свойство context
Get-ChildItem twitterData.txt |
Select-String -Pattern "Staffan" -Context 2,1 |
Foreach-Object {$ _. Context.PreContext [1], $ _. Context.PostContext [0]} Чтобы понять индексацию массивов Pre- и PostContext, рассмотрите следующее: Конвейерная поддержка Я хотел бы подчеркнуть, насколько полезнее становится Сводка Мы рассмотрели полезные методы строкового класса, особенно то, как использовать В следующий раз мы рассмотрим операторы Стаффан Густафссон, @StaffanGson, github Спасибо Джейсону Ширку, Матиасу Джессену и Стиву Ли за обзоры и отзывы. GitHub - Энгельберг / instaparseЧто, если бы контекстно-свободные грамматики были так же просты в использовании, как регулярные выражения? ХарактеристикиInstaparse - это самый простой способ создания парсеров на Clojure.
Краткое руководствоInstaparse требует Clojure v1.5.1 или новее или ClojureScript v1.7.28 или новее. Добавьте следующую строку в свои зависимости leiningen: Требовать instaparse в заголовке пространства имен: Создание вашего первого парсера Вот типичный пример контекстно-свободной грамматики, который можно увидеть в учебнике по автоматам и / или синтаксическому анализу. Во многих учебниках принято использовать заглавную букву Это ищет чередующиеся прогоны «a», за которыми следуют «b».Так, например, "aaaaabbaaabbb" удовлетворяет этой грамматике. С другой стороны, С помощью instaparse превратить эту грамматику в исполняемый синтаксический анализатор так же просто, как ввести грамматику в: На данный момент, если вы знаете нотацию EBNF для контекстно-свободных грамматик, вы, вероятно, знаете достаточно, чтобы погрузиться в нее и начать экспериментировать.Тем не менее, instaparse обладает множеством функций, поэтому, если вы хотите узнать все, что он может делать, читайте дальше ... УчебникОбозначение Instaparse поддерживает большинство распространенных обозначений для контекстно-свободных грамматик. Например, популярной альтернативой Итак, вот не менее действенный (но более беспорядочный) способ написать ту же самую грамматику, просто чтобы проиллюстрировать гибкость, которая у вас есть: Обратите внимание, что независимо от обозначения, которое вы используете в своей спецификации, когда вы оцениваете синтаксический анализатор в REPL, правила будут хорошо напечатаны: Вот краткое руководство по синтаксису для определения контекстно-свободных грамматик:
Как и обычно в нотации EBNF, конкатенация имеет более высокий приоритет, чем чередование, поэтому при отсутствии скобок, что-то вроде Ввод из файла ресурсовПарсеры также могут быть построены из спецификации, содержащейся в файле, локально или в Интернете. Например, я сохранил на github файл с простой грамматикой для анализа текста, содержащего одну букву «а», необязательно окруженную пробелами. Спецификация в файле выглядит так: Создать синтаксический анализатор из URI очень просто: Это удобный способ обмена спецификациями синтаксического анализатора через Интернет. Вы также можете использовать спецификацию, содержащуюся в локальном ресурсе в вашем пути к классам:
В ClojureScript вариант использования
Для решения этих проблем используется макрос ;; Clojure
(: require [instaparse.core: as insta: refer [defparser]])
;; ClojureScript
(: требуется [instaparse.core: as insta: refer-macros [defparser]])
=> (время (def p (insta / parser "S = A B; A = 'a' +; B = 'b' +")))
"Затраченное время: 4,368179 мсек"
# 'пользователь / p
=> (время (defparser p "S = A B; A = 'a' +; B = 'b' +")); суть работы происходит в макро-времени
«Прошедшее время: 0.0 Escape-символы Помещение вашей грамматики в отдельный файл ресурсов имеет дополнительное преимущество - это обеспечивает очень простой вид грамматики "то, что вы видите, то и получаете". Единственные необходимые escape-символы - это обычные escape-символы для строк и регулярных выражений (кроме того, instaparse также поддерживает Когда вы указываете грамматику непосредственно в коде Clojure в виде строки с двойными кавычками, в строках и регулярных выражениях вашей грамматики могут потребоваться дополнительные escape-символы:
Например, указанная выше грамматика может быть записана на Clojure как: К сожалению, этот дополнительный уровень побега необходим.Многие языки программирования предоставляют какие-то средства для создания «сырых строк», которые берутся дословно (например, строки Python в тройных кавычках). Я не понимаю, почему Clojure не поддерживает необработанные строки, но это не так. К счастью, для многих грамматик это не проблема, и если экранирование становится достаточно плохим, чтобы повлиять на удобочитаемость, всегда есть возможность сохранить грамматику в отдельном файле. Формат выводаПри создании синтаксических анализаторов вы можете указать выходной формат: hiccup или: enlive.: hiccup используется по умолчанию, но вот пример парсера выше с: enlive, установленным в качестве формата вывода: Я считаю формат hiccup приятным и компактным, особенно при работе с проанализированным выводом в REPL.Основное преимущество формата enlive заключается в том, что он позволяет использовать очень мощную библиотеку enlive для выбора и преобразования узлов в вашем дереве. Если вы хотите изменить выходной формат instaparse по умолчанию: Управление древовидной структуройПринципы выходных деревьев instaparse:
Чтобы лучше понять это, взгляните на эти два варианта одного и того же парсера, которые мы обсуждали: Скрытие содержимогоВ следующем примере давайте рассмотрим синтаксический анализатор, который ищет последовательность букв a или b, окруженных скобками. Очень часто в парсерах есть элементы, которые должны присутствовать на входе и анализироваться, но мы бы предпочли, чтобы они не появлялись на выходе. В приведенном выше примере парные скобки важны для грамматики, но дерево было бы намного легче читать и манипулировать, если бы мы могли скрыть эти скобки; как только строка проанализирована, сами скобки не несут дополнительной семантической ценности. В Instaparse вы можете использовать угловые скобки Вуаля! Знаки "(" и ")" скрыты. Угловые скобки - это мощный инструмент для скрытия пробелов и других разделителей из вывода. Скрытие теговПродолжая использовать тот же пример синтаксического анализатора, допустим, мы решили, что тег: seq-of-A-or-B также является лишним - мы бы предпочли, чтобы этот дополнительный уровень вложенности не отображался в выходном дереве. Мы уже видели, что один из вариантов - просто поднять правую часть правила seq-of-A-or-B в правило, заключенное в парные скобки, как показано ниже: Но иногда это некрасиво или непрактично.Было бы неплохо иметь способ выразить концепцию «повторяющейся последовательности a и b» как отдельное правило, не обязательно вводя дополнительный уровень вложенности. И снова на помощь приходят угловые скобки. Мы просто используем угловые скобки, чтобы скрыть имя правила. Поскольку каждое имя соответствует уровню вложенности, скрытие имени означает, что проанализированное содержимое этого правила появится в выходном дереве без тега и связанного с ним нового уровня вложенности. Вы можете задаться вопросом, что произойдет, если мы также скроем корневой тег. Давайте посмотрим: Без корневого тега синтаксический анализатор просто возвращает последовательность дочерних элементов.Итак, в приведенном выше примере, где всех тегов скрыты, вы просто получаете последовательность проанализированных элементов. Иногда это то, что вам нужно, но в целом я рекомендую вам не скрывать корневой тег, чтобы на выходе получилось хорошо сформированное дерево. Раскрытие скрытой информацииИногда после настройки синтаксического анализатора для скрытия содержимого и тегов вы временно хотите показать скрытую информацию, возможно, для целей отладки. Необязательный аргумент ключевого слова Необязательный аргумент ключевого слова Необязательный аргумент ключевого слова Никакой грамматики не осталосьОдна из вещей, которая действительно отличает instaparse от других генераторов синтаксического анализатора Clojure, заключается в том, что он может обрабатывать любую контекстно-свободную грамматику.Например, некоторые синтаксические анализаторы принимают только грамматики LL (1), другие принимают грамматики LALR. Многие библиотеки используют стратегию рекурсивного спуска, которая не работает для леворекурсивных грамматик. Если вы хотите изучить эзотерические ограничения, налагаемые библиотекой, обычно можно переделать вашу грамматику, чтобы она соответствовала этому шаблону. Но instaparse позволяет писать грамматику любым удобным для вас способом. Правая рекурсияНет проблем: Обратите внимание на использование Epsilon, распространенного имени для «пустого» синтаксического анализатора, который всегда успешно работает без использования каких-либо символов.Вы также можете просто использовать пустую строку, если хотите. Левая рекурсияНет проблем: Как видите, любой из этих рекурсивных синтаксических анализаторов сгенерирует дерево синтаксического анализа с глубокой вложенностью. Неоднозначные грамматики Эта грамматика интересна тем, что даже несмотря на то, что она определяет повторное выполнение «a», есть много возможных способов, которыми грамматика может ее «разрезать».Наш парсер добросовестно вернет один из возможных синтаксических анализов: Однако мы можем сделать лучше. Во-первых, я должен указать, что Вы можете спросить, чем это полезно? Две причины:
Обычно я тестирую свои синтаксические анализаторы с помощью функции Регулярные выражения: предупреждениеКак видно из приведенного выше примера, instaparse гибко интерпретирует * и +, пробуя все возможные числа повторений для создания дерева синтаксического анализа.Это легко испортить, а потом забыть, что регулярные выражения имеют разную семантику. Регулярные выражения Instaparse - это просто регулярные выражения Clojure / Java, которые ведут себя жадно. Чтобы лучше понять этот момент, сравните анализатор выше с этим: В этом синтаксическом анализаторе * - это внутри регулярного выражения , что означает, что оно следует жадной семантике регулярных выражений.Следовательно, первый А съедает все, что может, а второму А не остается. По этой причине разумно использовать регулярные выражения с умом, в основном для выражения шаблонов ваших токенов, и оставить общую задачу синтаксического анализа на усмотрение. Регулярные выражения часто можно замучить и использовать в качестве грубого синтаксического анализатора, но не делайте этого! Не нужно; Благодаря instaparse теперь у вас есть не менее удобный, но более выразительный инструмент, позволяющий решать проблемы синтаксического анализа. Вот пример, который, на мой взгляд, представляет собой изящное использование регулярных выражений для разделения предложения на пробелы, категоризации лексем как слов или чисел: Частичный синтаксический анализПо умолчанию instaparse предполагает, что вы ищете дерево синтаксического анализа, которое охватывает всю входную строку.Однако иногда может быть полезно просмотреть все частичные синтаксические разборы, удовлетворяющие грамматике, при использовании некоторой начальной части входной строки. Для этой цели и Конечно, использование Удлинители ПЭГPEG - популярная альтернатива контекстно-свободным грамматикам. На первый взгляд, PEG очень похожи на CFG, но различные операторы выбора предназначены для интерпретации строго жадным, упорядоченным способом, который устраняет любую двусмысленность из грамматики. Некоторые считают отсутствие двусмысленности преимуществом, но оно ограничивает выразительность PEG по сравнению с контекстно-свободными грамматиками.Кроме того, PEG обычно тесно связаны с определенной стратегией синтаксического анализа, которая запрещает левую рекурсию, что еще больше ограничивает их полезность. Для борьбы с этой утраченной выразительностью в PEGs было принято несколько операторов, которые фактически позволяют PEG делать некоторые вещи, которые CFG не могут выразить. Несмотря на то, что лежащая в основе парадигма отличается, я взял эти пикантные фрагменты из PEG и включил их в мгновение ока, придав мгновенным более выразительной мощности, чем традиционные PEG или традиционные CFG. Вот таблица операторов PEG, адаптированных для использования in instaparse; Я объясню их более подробно в ближайшее время.
Lookahead Символами для опережающего просмотра являются Это непросто, и абстрактно его сложно понять, поэтому давайте рассмотрим конкретный пример: Часть Если вы напишете что-то вроде Вот мой любимый пример просмотра вперед, синтаксического анализатора, который преуспевает только в строках с запуском a, за которым следует запуск b, за которым следует запуск c, где каждый из этих прогонов должен быть одинаковой длины. Если вы когда-либо проходили курс по автоматам, вы, возможно, помните, что существует очень элегантное доказательство того, что невозможно выразить этот набор ограничений с помощью чистой контекстно-свободной грамматики. Что ж, с опережением, это возможно : Этот пример успешен, потому что есть три символа a, за которыми следуют три b, за которыми следуют три c.Проверка того, что этот синтаксический анализатор не работает для неравных прогонов и других сочетаний букв, оставлена в качестве упражнения для читателя. Отрицательный прогноз Отрицательный просмотр вперед использует символ Таким образом, этот синтаксический анализатор меняет смысл предыдущего примера, принимая все строки из a и b, которые не , начинаются с Одна проблема с отрицательным взглядом вперед заключается в том, что он вводит возможность парадоксов. Считайте: Как этот парсер должен вести себя при вводе «а»? Если S успешен, он должен потерпеть неудачу, а если нет, он должен быть успешным. PEG просто не допускают такого рода грамматики, но весь дух instaparse заключается в гибком разрешении рекурсивных грамматик, поэтому мне нужно было найти способ справиться с этим.По сути, я предпринял шаги, чтобы убедиться, что парадоксальная грамматика не заставит instaparse зайти в бесконечный цикл. Он прекратится, но я не обещаю, каковы будут результаты. Если вы укажете парадоксальную грамматику, это ситуация типа «мусор в мусоре» (хотя для ясности, instaparse не вернет полный мусор; он сделает какое-то разумное суждение о том, как его интерпретировать). Если вам интересно, как ведет себя instaparse в приведенном выше парадоксальном примере, вот он: Отрицательный просмотр вперед при правильном использовании — чрезвычайно мощный инструмент для устранения двусмысленности из вашего синтаксического анализатора.Чтобы проиллюстрировать это, давайте рассмотрим очень распространенную задачу синтаксического анализа, которая включает разметку строки символов в комбинацию идентификаторов и зарезервированных ключевых слов. Наша первая попытка оказалась неоднозначной: Каждое из наших ключевых слов соответствует не только описанию ключевого слова, но и идентификатора, поэтому наш синтаксический анализатор не знает, каким образом анализировать эти слова.Instaparse не дает никаких гарантий относительно того, в каком порядке он обрабатывает альтернативы, и в этой ситуации мы видим, что на самом деле нужная нам комбинация была указана последней среди возможных синтаксических анализов. Отрицательный просмотр вперед позволяет легко устранить эту неоднозначность: Заказной выбор Как я упоминал ранее, интерпретация PEG чисел Хотя парадигма принудительного порядка PEG противоречит гибкой стратегии синтаксического анализа instaparse, я решил использовать нотацию Имея это в виду, давайте вернемся к примеру с неоднозначным токенизатором Мы уже видели один способ устранить двусмысленность с помощью отрицательного просмотра вперед.Но теперь у нас есть еще один инструмент в нашем наборе инструментов, Оператор упорядоченного выбора имеет свои применения, но не переусердствуйте.Есть две основные причины, по которым обычно лучше использовать обычный оператор неупорядоченного чередования.
Ошибки синтаксического анализа Общий режим синтаксического анализаИногда недостаточно знать точку сбоя, и вам нужно знать весь контекст дерева синтаксического анализа, когда оно не удалось. Чтобы помочь в подобных ситуациях, instaparse предлагает режим «полного анализа», вдохновленный синтаксическим анализатором петрушки Christophe Grand. Этот режим полного анализа гарантирует анализ всей строки; если синтаксический анализатор не работает, он все равно завершает синтаксический анализ, встраивая точку отказа как узел в дерево синтаксического анализа. Чтобы продемонстрировать, давайте вернемся к сверхпростому синтаксическому анализатору Обратите внимание, что такой общий результат синтаксического анализа по-прежнему считается «неудачей», и мы можем проверить это и получить объект сбоя, используя Я считаю, что режим полного синтаксического анализа является наиболее ценным диагностическим инструментом, когда причина ошибки находится далеко от точки, в которой синтаксический анализатор действительно дает сбой.Типичным примером может служить грамматика, в которой вы ищете фразы, разделенные кавычками, а в тексте не указывается закрывающая кавычка вокруг какой-либо фразы в середине текста. Анализатор не дает сбоев, пока не достигнет конца текста, не встретив закрывающую кавычку. В таком случае быстрый просмотр всего дерева синтаксического анализа покажет вам контекст сбоя, что позволит легко определить место, где началась повторная фраза. Разбор из другого правила запускаЕще один ценный инструмент для интерактивной отладки — это возможность тестировать отдельные правила.Чтобы продемонстрировать это, давайте вернемся к нашему самому первому парсеру: Как мы видели в этом руководстве, по умолчанию instaparse предполагает, что самое первое правило — это ваше «начало производства», правило, по которому изначально выполняется синтаксический анализ. Но мы можем легко установить другие правила для начала производства с аргументом ключевого слова Функция Обзор аргументов ключевого слова На этом этапе вы видели все аргументы ключевых слов, которые принимает синтаксический анализатор, сгенерированный instaparse: Вы также видели оба аргумента ключевого слова, которые можно использовать при построении синтаксического анализатора из спецификации: Преобразование дереваРабота парсера — превратить строку в некую древовидную структуру. Что с ним делать дальше — решать вам. В Clojure очень легко манипулировать деревьями. Доступны замечательные инструменты: enlive, zippers, match и tree-seq. Но даже без этих инструментов большинство манипуляций с деревом легко выполнить в Clojure с рекурсией. Поскольку преобразования дерева уже так легко выполнять в Clojure, нет особого смысла создавать сложную библиотеку преобразований для мгновенного анализа.Тем не менее, я включил одну функцию, Сделаем этот бетон на примере.До сих пор на протяжении всего руководства мы могли адекватно выражать токены наших языков с помощью строк или регулярных выражений. Но иногда регулярных выражений недостаточно, и мы хотим задействовать всю мощь контекстно-свободных грамматик для решения проблемы обработки отдельных токенов. Когда мы это делаем, мы получаем кучу отдельных символов, где нам действительно нужна строка или число. Чтобы проиллюстрировать это, давайте вернемся к примеру Нам бы очень хотелось упростить эти терминалы Или, если вы поклонник потоковых макросов, попробуйте эту версию: Функция С деревом такой формы его легко оценить: Понимание дереваКоличество символов Деревья, созданные с помощью instaparse, аннотируются метаданными, так что для каждого поддерева вы можете легко восстановить начальный и конечный индексы входного текста, проанализированного этим поддеревом.Удобная функция для извлечения этих метаданных — Как видите, Информация о строках и столбцах Иногда, когда входная строка содержит символы новой строки, полезно иметь метаданные диапазона в виде номеров строк и столбцов. По умолчанию instaparse этого не делает, потому что для генерации информации о строках и столбцах требуется второй проход по входной строке и дереву синтаксического анализа. Однако функция Дополнительная информация находится в метаданных, поэтому само дерево заметно не изменяется: Но теперь давайте проверим метаданные для всего дерева синтаксического анализа. И давайте взглянем на метаданные для слова «is» во второй строке текста. start-line и start-column указывают на тот же символ, что и start-index, а end-line и end-column указывают на тот же символ, что и end-index. Таким образом, как и обычные метаданные диапазона, начальная точка строки / столбца является включительной, а конечная точка является исключительной. Однако номера строк и столбцов отсчитываются от 1, а не от 0. Так, например, порядковый номер 0 строки соответствует строке 1, столбцу 1. Визуализация дерева Instaparse содержит функцию Функция визуализации по умолчанию открывает дерево в новом окне. Чтобы фактически сохранить изображение дерева как файл для этого руководства, я использовал оба необязательных аргумента ключевого слова, поддерживаемые В этом случае корневище — особенно быстро движущаяся цель. На момент написания этой статьи наиболее актуальной версией является rhizome 0.1.8, выпущенная всего через несколько недель после версии 0.1.6. Если бы я сделал instaparse зависимым от корневища 0.1.8, то через несколько недель, когда 0.1.9, будет сложнее использовать instaparse в проектах, которые полагаются на самую последнюю версию rhizome. По этой причине я сделал кое-что необычное: вместо того, чтобы напрямую включать корневище в зависимости instaparse, я настроил все так, что Если вы не хотите использовать Комбинаторы Я искренне верю, что обычная нотация EBNF — самый ясный и лаконичный способ выразить контекстно-свободную грамматику. Тем не менее, бывают случаи, когда полезно создавать синтаксические анализаторы с комбинаторами синтаксического анализатора. Если вы хотите использовать instaparse таким образом, вам нужно будет использовать пространство имен Каждая конструкция, которую вы видели из спецификации строки, имеет соответствующий комбинатор синтаксического анализатора. Большинство из них просты, но последние несколько строк таблицы потребуют дополнительных пояснений.
При использовании комбинаторов вместо построения строки ваша цель — построить карту грамматики . Итак, спецификация выглядит так: становится Также можно построить вектор: Основное отличие состоит в том, что если вы используете представление карты, вам в конечном итоге потребуется указать правило запуска, но если вы используете вектор, instaparse будет считать, что первое правило является правилом запуска. В любом случае, я буду ссылаться на приведенную выше структуру как на карту грамматики . Большинство комбинаторов, если вы обратитесь к приведенной выше таблице, довольно очевидны. Вот еще несколько вещей, о которых следует помнить, а затем последует конкретный пример:
Надеюсь, все это будет прояснено на примере. Вы помните парсер, который ищет равное количество букв a, за которыми следует b, за которым следует c? Ну вот и соответствующая карта грамматики: Создав карту грамматики, вы превращаете ее в исполняемый синтаксический анализатор, вызывая Результат — синтаксический анализатор, аналогичный синтаксическому анализатору, построенному на основе строковой спецификации. На мой взгляд, строка значительно более читабельна, но если вам нужен или вы хотите использовать комбинаторный подход, вы можете его использовать. Преобразование строки в комбинатор Вскоре после того, как я опубликовал первую версию instaparse, я получил вопрос: «Строковые спецификации можно комбинировать с закрытием дает такую же структуру, как если бы вы набрали комбинатор версии Вы также можете передать все правила на производит Это открывает возможность построения грамматики из комбинации комбинаторов и строк, преобразованных в комбинаторы.Вот надуманный пример: ABNFОсновной формат ввода Instaparse основан на синтаксисе EBNF, но доступен альтернативный формат ввода ABNF. Большинству пользователей не понадобится входной формат ABNF, но если вам нужно реализовать синтаксический анализатор, спецификация которого написана в синтаксисе ABNF, это очень просто сделать.Пожалуйста, прочтите документацию instaparse по ABNF для получения подробной информации. Чувствительность к регистру строкОдно заметное различие между нотациями EBNF и ABNF состоит в том, что в EBNF строковые терминалы чувствительны к регистру, тогда как в ABNF строковые терминалы традиционно чувствительны к регистру — на . Instaparse по умолчанию следует соответствующему поведению двух нотаций, но в обоих случаях чувствительность к регистру можно переопределить с помощью флага С другой стороны, если вы хотите смешивать и сопоставлять чувствительные к регистру и нечувствительные к регистру строки в грамматике, вы можете преобразовать строки в регулярные выражения, например Сериализация Вы можете сериализовать синтаксический анализатор instaparse с помощью Обычно удобнее хранить и / или передавать строковую спецификацию, используемую для генерации синтаксического анализатора. Строковая спецификация позволяет перестроить синтаксический анализатор с другим форматом вывода; Замечания по производительностиНекоторые из имеющихся библиотек синтаксического анализа были написаны в качестве обучающего упражнения — например, комбинаторы монадического синтаксического анализатора — отличный способ развить понимание монад. Нет ничего плохого в том, чтобы взять плоды учебного упражнения и сделать его общедоступным, но существует достаточно библиотек синтаксического анализатора Clojure, поэтому становится трудно отличить те, которые «готовы к работе в прайм-тайм», и те, которые это не так.Например, некоторые библиотеки сильно полагаются на вложенные продолжения, стратегия, которая почти наверняка вызовет переполнение стека при умеренно больших входных данных. Другие в значительной степени полагаются на мемоизацию, но никогда не заботятся об очистке кеша между входами, в конечном итоге исчерпывая всю доступную память, если вы повторно используете синтаксический анализатор. Я не собираюсь давать никаких точных гарантий производительности — гибкий, общий характер instaparse означает, что можно писать грамматики, которые плохо себя ведут.Тем не менее, я хочу сказать, что производительность — это то, к чему я относился серьезно. Я провел бесчисленные часы, анализируя поведение instaparse на странных грамматиках и больших входных данных, используя эти данные для повышения производительности. В качестве одного из примеров я обнаружил, что для большого класса грамматик самым большим узким местом была стратегия хеширования Clojure, поэтому я реализовал оболочку вокруг векторов Clojure, которая использует альтернативную стратегию хеширования, успешно сократив время работы многих синтаксических анализаторов с квадратичного до линейного.(Благодарность Кристофу Гранду, который дал мне ценные советы по этому конкретному усовершенствованию.) Я также работал над устранением «сюрпризов производительности». Например, и левая, и правая рекурсия имеют достаточно похожую производительность, поэтому вам действительно не нужно мучиться над тем, какой из них использовать — выберите тот стиль, который лучше всего подходит для данной проблемы. Если вы выражаете свою грамматику естественным образом, велики шансы, что производительность сгенерированного синтаксического анализатора будет удовлетворительной.Дополнительное повышение производительности в виде многопоточности запланировано в следующем выпуске. Одно предостережение относительно производительности: instaparse довольно требователен к памяти, полагаясь на обширное кэширование промежуточных результатов для сохранения разумных вычислительных затрат. В этом нет ничего необычного — кеширование — обычное дело во многих современных синтаксических анализаторах, в результате чего пространство используется в обмен на время, — но об этом стоит помнить. Парсеры Packrat / PEG и многие парсеры рекурсивного спуска используют аналогичную стратегию интенсивного использования памяти, но есть и другие альтернативы, если такое использование памяти неприемлемо.Как и следовало ожидать, синтаксические анализаторы Instaparse не удерживают кеш памяти после завершения синтаксического анализа; эта память доступна для сборки мусора. В документе с примечаниями к производительности содержится более глубокое обсуждение производительности и несколько полезных советов по достижению максимальной производительности вашего синтаксического анализатора. Номер ссылкиВсе функции, которые вы видели в этом руководстве, упакованы в API всего из 9 функций. Вот строки документа: Экспериментальные особенностиСм. Страницу «Экспериментальные функции» для обсуждения новых функций, находящихся в активной разработке, включая оптимизацию памяти и автоматическую обработку пробелов. СвязьЯ стараюсь быстро реагировать на проблемы, размещенные на странице проблем github. Но если у вас есть общий вопрос, вам нужна помощь в устранении проблем с грамматикой или у вас есть что-то интересное, что вы сделали в instaparse, чем вы хотели бы поделиться, подумайте о том, чтобы присоединиться к группе Instaparse Google и опубликовать там сообщение. Особая благодарностьМой интерес к этому проекту возник во время просмотра видео выступления Мэтта Майта « Parsing with Derivatives ». Это видео убедило меня в том, что мир стал бы лучше, если бы создание парсеров было таким же простым, как работа с регулярными выражениями, и что способность обрабатывать произвольные, возможно, неоднозначные грамматики была важна для этой цели. Мэтт Майт опубликовал статью о конкретном подходе к достижению этой цели, но мне было трудно заставить его метод Parsing with Derivatives работать эффективно. Я бы, наверное, отказался, но потом Дэнни Ю выпустил генератор парсера Ragg для языка Racket. Библиотека Ragg была огромным источником вдохновения — моделью того, чем я хотел сразу стать. Я спросил Дэнни, какую технику он использует, и он дал мне больше информации об используемом им алгоритме. Однако он сказал мне, что если бы он сделал это снова с нуля, он, вероятно, решил бы использовать алгоритм GLL Адриана Джонстона и Элизабет Скотт, и он указал мне на фантастическую статью об этом Вегарда Эйе, опубликованную на Github. с исходным кодом в Racket. В этой статье была ссылка на статью и код Scala Даниэля Спивака, что также было чрезвычайно полезно. Алекс Энгельберг закодировал первую версию instaparse, доказав возможности алгоритма GLL. Он посоветовал мне взять его код, построить и задокументировать удобный API. Он по-прежнему является основным участником проекта, в последнее время разработав интерфейс ABNF, доведя порт Clojurescript до функционального паритета с версией Clojure и прорабатывая детали слияния двух кодовых баз. Я изучил ряд других генераторов синтаксического анализатора Clojure, чтобы сформулировать свои представления о том, как должен выглядеть API. Я общался с Эриком Норманом (квадратный) и Кристофом Грандом (петрушка), оба из которых дали полезные советы и побудили меня следовать моему видению. YourKit любезно поддерживает проекты с открытым исходным кодом с помощью своего полнофункционального профилировщика Java. ЛицензияРаспространяется по лицензии Eclipse Public License, такой же, как Clojure. ресурсов // Текстовый анализ // Репозиторий программного обеспечения для бухгалтерского учета и финансов // University of Notre Dame
Эта страница содержит инструменты, полезные для текстового анализа в финансовых приложениях, и данные из некоторых связанных с текстами публикаций, которые я имею с Тимом Лафраном.Существенный метод текстового анализа имеет различные ярлыки в других дисциплинах, таких как контент-анализ, обработка естественного языка, поиск информации или компьютерная лингвистика. В растущей литературе обнаруживается значительная взаимосвязь между реакцией цен на акции и настроением выпускаемой информации, измеряемой классификациями слов, например приведенными ниже. Если вы хотите получать уведомления об обновлениях по электронной почте, пришлите мне электронное письмо, и я внесу вас в список рассылки обновлений.Сборники данных, представленные на этом веб-сайте, предназначены для использования отдельными исследователями. Для получения коммерческих лицензий свяжитесь с нами. Ресурсов:
Примечание. Мы благодарим Кэма Харви и других, которые предложили некоторые модификации, которые мы включили в эти списки.Списки слов описаны в:
Хотя мы предоставляем каждую категорию тональности в таблице ниже, все списки слов содержатся в Основном словаре. Для пользователей WordStat: WordStat.файлы cat и .NFO 2018 Главный словарь (формат xlsx, формат csv) Обновлено: март 2019 На основе версии 4.0 из 2of12inf. Расширен для включения слов, встречающихся в документах 10-K / Q, и звонков о доходах, которых нет в исходном списке слов 2of12inf. Помимо основного списка слов, словарь включает статистику частотности слов во всех 10-K / Q за 1994-2018 гг. (Включая варианты 10-X — см. Подробную документацию).Словарь сообщает о количестве, доле от общего количества, средней доле на документ, стандартном отклонении доли на документ, подсчете документов (т. Е. Количестве документов, содержащих хотя бы одно вхождение слова), восьми идентификаторах категорий тональности, идентификаторе Гарвардского списка слов, количестве слогов и источник каждого слова. Категории настроений являются: отрицательный, положительный, неопределенность, сутяжнический, модальный, сдерживая. Модальные слова помечаются как 1, 2 или 3, причем 1 = сильное модальное, 2 = умеренное модальное и 3 = слабое модальное.Остальные эмоциональные слова отмечены числом, указывающим год, в котором они были добавлены в список. Подробная документация представлена здесь. Как отмечалось выше, в Главном словаре также собраны все списки тональных слов. Каждая строка в электронной таблице главного словаря представляет собой слово. Списки тональных слов идентифицируются по столбцу, а элементы данного набора идентифицируются ненулевыми записями. Ненулевые записи представляют год, в котором слово было добавлено в данный список тональности. Скачать файл здесь (187MB) Используя проанализированные файлы Stage One (здесь), создается набор данных, содержащий сводные данные для каждой регистрации. Класс Python для этого модуля доступен здесь. Этот файл содержит запись заголовка с метками и разделен запятыми. Каждая запись сообщает:
1993-2018 гг., Документы SEC по типу / году: анализ основного индекса (нажмите, чтобы загрузить) Обновлено: январь 2019 г. Веб-сайт EDGAR Комиссии по ценным бумагам и биржам индексирует все электронные документы в квартальных мастер-файлах. В этой таблице перечислены все различные документы по годам. Стоп-слова — это, как правило, слова, которые не считаются добавляющими информацию к рассматриваемому вопросу.Таким образом, универсального списка стоп-слов не существует, поскольку то, что считается неинформативным, зависит от контекста вашего приложения. То, что я помечаю ниже как «общие» стоп-слова, — это такие слова, как «и», «то» или «из». Общий список стоп-слов, который я предоставляю, основан на списке стоп-слов, используемом Python Natural Language Toolkit (NLTK), измененном следующим образом:
Обратите внимание, что все списки написаны в верхнем регистре, поэтому вы должны помнить об этом при сравнении эквивалентности. |