
Содержание
Как отличить совершенный вид от несовершенного
Вид – грамматическая категория, характеризующая глагол с точки зрения времени выполнения действия, его завершенности или незавершенности. В русском языке глаголы могут быть совершенного и несовершенного вида. Также различают двувидовые глаголы.
Главный способ определить вид глагола – задать к нему соответствующий вопрос. В неопределенной форме глагола (инфинитиве) это вопросы «что делать/что сделать?». Глагол, отвечающий на вопрос «что сделать?», будет показывать, что действие или уже завершено во времени, или еще не начиналось. В любом случае, оно не происходит в данный момент. Значит, это глагол совершенного вида. Если глагол отвечает на вопрос «что делать?», он показывает, что действие протекает во времени в данный момент, что оно еще не совершилось. Следовательно, перед вами глагол несовершенного вида.
Определение вида по вопросам – самый простой и надежный способ. Запомнить его легко: если в задаваемом вопросе есть приставка «С», то глагол совершенного вида. Если приставки нет – вид несовершенный. При этом формы вопросов могут меняться в зависимости от формы глагола: например, вопросы «что сделать», «что сделал», «что сделает» могут быть заданы только к глаголам совершенного вида (т.к. они имеют приставку «С»), при этом время глагола на его вид не влияет. Тот же самый процесс наблюдается и у глаголов несовершенного вида.
Если приставки нет – вид несовершенный. При этом формы вопросов могут меняться в зависимости от формы глагола: например, вопросы «что сделать», «что сделал», «что сделает» могут быть заданы только к глаголам совершенного вида (т.к. они имеют приставку «С»), при этом время глагола на его вид не влияет. Тот же самый процесс наблюдается и у глаголов несовершенного вида.
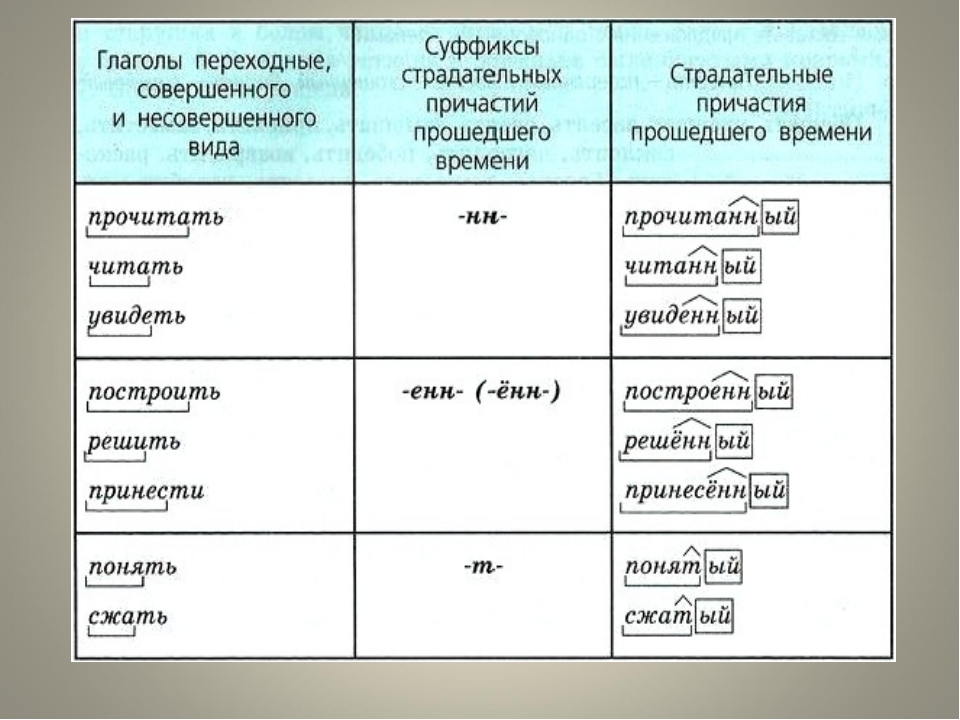
Различить совершенный и несовершенный виды глагола можно и по формальным признакам. Как правило, глаголы несовершенного вида образуются от глаголов совершенного вида суффиксальным способом.
— ива-, -ыва- : рассказать → рассказываю.
— ва — : накрыть →накрывать.
— а-, -я-: спасти → спасать. В данных видовых парах первый глагол (производящий) совершенного вида, а второй (производный) – несовершенного.
Глаголы несовершенного вида могут образовывать глаголы совершенного вида следующими способами:
Приставочный.
на-: учить → научить.
по- : строить → построить.
про-: говорить → проговорить.
Суффиксальный.
-ну- : привыкать → привыкнуть.
В данных парах первый глагол имеет несовершенный вид, а второй – совершенный. Обратите внимание, что в данном случае меняется не только формальный вид и форма глагола, но и его лексическое значение.
Двувидовые глаголы следует рассматривать только в контексте. В зависимости от речевой ситуации они могут быть глаголами совершенного или несовершенного вида. Рассмотрим пример из произведения Н.В. Гоголя.
«Не прикажете ли, я велю подать коврик?»Задаем вопрос к слову «велю». В данном контексте: я (что сделаю?) велю. Глагол совершенного вида.
Однако если глагол «велю» рассматривать в настоящем времени, то вопрос к нему будет «что делаю»: следовательно, вид будет несовершенный.
Виды глагола — презентация онлайн
1. Виды глагола
Дорогие ребята!
Сегодня на уроке мы познакомимся
с новой грамматической категорией —
вид глагола. Вы узнаете, что глаголы
могут быть совершенного и
несовершенного вида, и научитесь
определять вид глагола.
3. Как подписать картинки?
Бабушка вязала шарф.
Бабушка связала шарф.
Б
Из предложения Бабушка связала
шарф мы узнаём, что шарф готов.
Предложение Бабушка вязала шарф не
сообщает нам, закончила бабушка свою
работу или нет.
• Глаголы совершенного вида указывают
на то, что действие совершилось,
достигло (достигнет) своего предела:
связала.
• Глаголы несовершенного вида
обозначают действие в его течении:
вязала.
Учёные-лингвисты используют
специальный термин — предел
действия. Предел действия —
это любой момент, любая
точка, с которой действие
должно прекратиться.
Например: прилететь —
«закончить полёт», проснуться
— «перестать спать».
6. Как определить вид глагола?
Первый способ – вопрос.
• Глаголы несовершенного вида отвечают на
вопросы что делать? что делает? что
делали? и т. д.
Летать, рисует, выбирали
• Глаголы совершенного вида отвечают на
вопросы что сделать? что сделает? что
сделали? и т.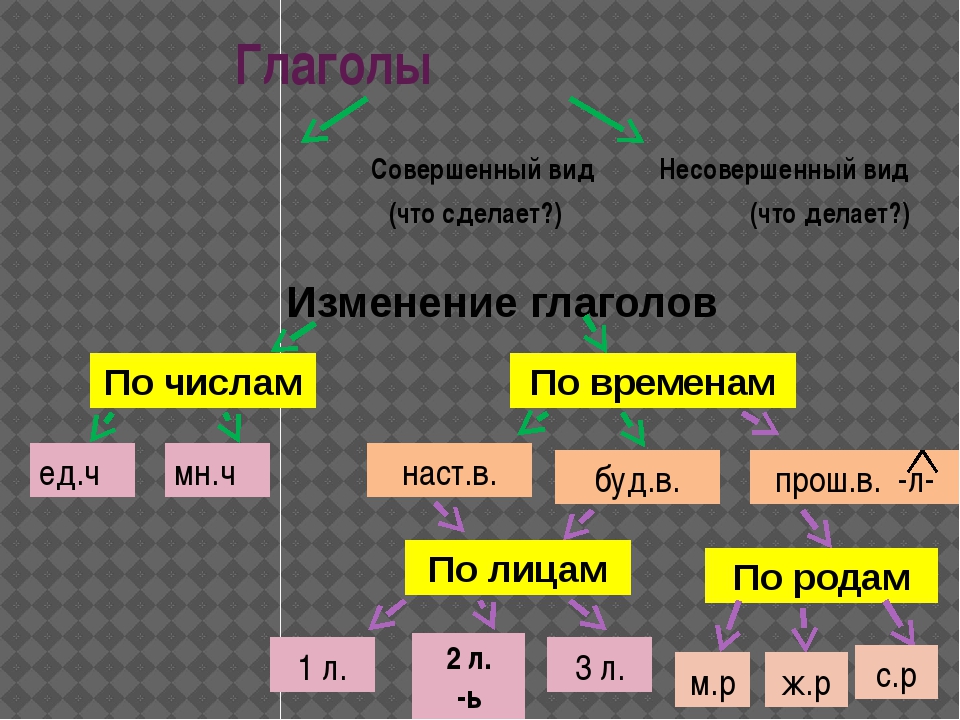 д.
д.
Вернуться, напишет, пришли
7. Как определить вид глагола?
Второй способ — слово «буду».
• К глаголам несовершенного вида
можно подставить слово буду,
например: петь — буду петь
(несовершенный вид).
• К глаголам совершенного вида слово
буду подставить нельзя, например:
спеть — нельзя сказать буду спеть
(совершенный вид).
8. Учимся играя. Вопрос с приставкой.
Легко запомнить: глаголы совершенного
вида отвечают только на те вопросы,
которые имеют приставку с-.
9. Клуб знатоков. Случайный выстрел.
Сравните два предложения и определите, в
каком из них выстрел получился случайно.
Мальчик натянул рогатку и выстрелил.
Мальчик натягивал рогатку и выстрелил.
10. Время и вид
Ребята, очень внимательно
рассмотрите таблицу, чтобы
понять, в каком времени могут
употребляться глаголы
совершенного и несовершенного
вида. У глаголов какого вида есть
только два времени — прошедшее
и будущее? Почему?
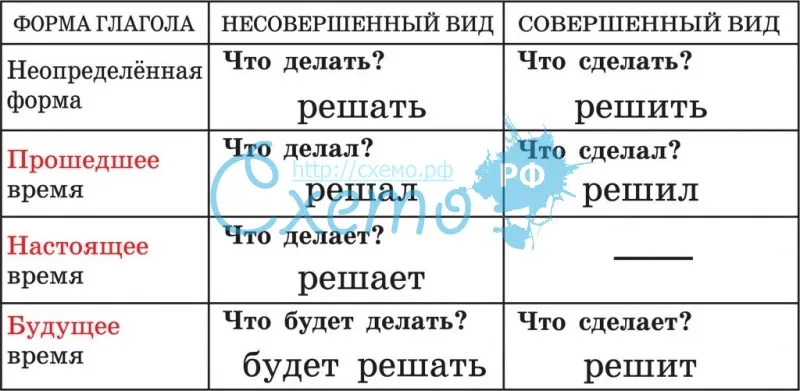
Виды глагола
Вопрос
Время
Посещал
занятия
Посетил
занятия
Прошедшее
Посещаю
занятия
—
Настоящее
Буду
посещать
занятия
Посещу
занятия
Будущее
Итак, глаголы совершенного вида могут
употребляться только в прошедшем и
будущем времени, они не имеют формы
настоящего времени. Это связано с тем, что
Это связано с тем, что
глаголы совершенного вида обозначают такое
действие, которое уже свершилось, достигло
результата (нарисовал, пришёл), или
обязательно свершится, т.е. будет иметь
результат, в будущем (нарисует, придёт).
Поставить такие глаголы в форму настоящего
времени невозможно, потому что в настоящем
времени глаголы обозначают действие,
происходящее в данный момент, которое ещё
не достигло результата (рисую, иду — несов.
вид).
• Время глагола не имеет значения для
определения его вида. Например, в
словосочетании учил вчера действие
закончилось, а глагол учил (что делал?)
несовершенного вида. Мы не знаем,
закончил ли он учить или всё ещё учит.
• В словосочетании выучу завтра
действия ещё нет, а глагол выучу (что
сделаю?) совершенного вида. Мы
знаем, что завтра действие точно
закончится.
14. Весёлая переменка. Вы никогда не пробовали играть словами?
Совсем недавно мы с подругой гуляли в парке. Стояли последние
Стояли последние
дни лета, но было по-осеннему прохладно. Подруга и говорит: «А ведь
осень уже наступила!» «Не знаю, как осень, а вот ты точно наступила
мне на ногу», — отвечаю я.
Попробуйте
поиграть словами
почитать, походил
и другими.
16. Клуб знатоков. Можно ли падать, но не упасть?
Глагол падать несовершенного вида, обозначает
«лететь сверху вниз под действием собственной
тяжести». Парным ему будет глагол упасть, то есть
«оказаться внизу». Глагол падать обозначает
действие, которое должно со временем
прекратиться: то, что падает, должно со временем
упасть.
• Оказывается, так бывает не всегда. Есть в Италии, в
городе Пизе, сооружение, которое «падает» уже
более семисот лет. Многим из вас известно его
название — Пизанская башня. Дело в том, что ещё в
1173 году, когда началось строительство, фундамент
башни положили неровно. И с тех пор башня
«падает», наклонившись к югу
17.
 Тренажёр. Виды глагола
Тренажёр. Виды глагола
Действие какого вида обозначают картинки?
Несовершенного
Совершенного
Несовершенного
Совершенного
19. Весёлая переменка. Блинчики.
Всюду Павлику почёт:
Павлик блинчики печёт.
Он провёл беседу в школе Говорил, открыв тетрадь,
Сколько соды, сколько соли,
Сколько масла нужно брать.
Доказал, что вместо масла
Можно брать и маргарин.
Решено единогласно:
Он прекрасно говорил.
Кто сказал такую речь,
Сможет блинчиков напечь!
Но, товарищи, спешите Нужно дом спасать скорей!
Где у вас огнетушитель?
Дым валит из-под дверей!
А соседи говорят:
— Это блинчики горят!
Ох, когда дошло до дела,
Осрамился наш герой Девять блинчиков сгорело,
А десятый был сырой!
Говорить нетрудно речь,
Трудно блинчиков напечь!
(А. Барто)
20. Проверь себя. Как определить вид глагола Впишите вопросы рядом с глаголами.
ползёт ( ?)
привёл ( ?)
вылетит ( ?)
строятся ( ?)
21.
 Домашнее задание. Перепишите слова, задайте вопрос, определите вид глаголов.
Домашнее задание. Перепишите слова, задайте вопрос, определите вид глаголов.
остановился
проспал
красила
расцветать
любит
исчезаю
придумали
стрижёт
заниматься
лягу
помогать
полюбили
куплю
22. Важный вывод.
Глаголы совершенного вида указывают на то,
что действие совершилось, достигло
(достигнет) своего предела: приехал,
выбросили.
• Глаголы несовершенного вида обозначают
действие в его течении: вязала, ходит и т. д.
• Глаголы несовершенного вида отвечают на
вопросы что делать? что делает? что делали? и
т. д. Бежать, смотрит, растили.
• Глаголы совершенного вида отвечают на
вопросы что сделать? что сделает? что
сделали? и т. д. Помыть, купит, выиграли.
Тест по русскому языку Совершенный и несовершенный вид глагола — пройти тест онлайн — игра — вопросы с ответами
Мой результат
Тест онлайн
Нашли ошибку? Выделите ошибку и нажмите Ctrl+Enter
Выбрав правильный на ваш взгляд вариант ответа, жмите на кнопку «Проверить». Если хотите сразу увидеть правильные ответы, ищите под вопросами ссылку «Посмотреть правильные ответы»
Если хотите сразу увидеть правильные ответы, ищите под вопросами ссылку «Посмотреть правильные ответы»
1.
Как определить вид глагола?
2.
На какой вопрос отвечают глаголы совершенного времени?
3.
На какой вопрос отвечают глаголы несовершенного времени?
4.
Какое действие обозначают глаголы несовершенного вида?
5.
Какое действие обозначают глаголы совершенного вида?
6.
Сколько форм прошедшего времени было в древнерусском языке?
7.
Какие глаголы составляют видовую пару?
8.
Перед какими суффиксами наблюдаются чередования звуков в корне?
9.
С помощью какой формулы И. Г. Милославский предложил определять вид глагола?
10.
Какие глаголы не образуют видовую пару?
Новое и Интересное на портале
Конспект урока для 6 класса «Глаголы совершенного и несовершенного вида»
Закрепление.
Задание 1.
Запишите глаголы в два столбика. В первый — те, которые обозначают, что действие происходит один раз, в один момент; во второй — те, которые обозначают длительность действия. На какие вопросы будут отвечать глаголы первого столбика? второго?
что сделать? | что делать?
1) Свистеть — свистнуть, крикнуть — кричать, махнуть — махать, стучать — стукнуть.
2) Писать — написать, жечь — сжечь, нести — унести.
Задание 2. Спишите, указывая вид глаголов.
Край неба алеет. В березах просыпаются, неловко перелетывают галки; воробьи чирикают около темных скирд. Светлеет воздух, видней дорога, яснеет небо, белеют тучки, зеленеют поля. В избах красным огнем горят лучины, за воротами слышны заспанные голоса. А между тем заря разгорается. Вот уже золотые полосы потянулись по небу, в оврагах клубятся пары. Жаворонки звонко поют, предрассветный ветер подул, и тихо всплывает багровое солнце. Свет так и хлынет потоком; сердце в вас встрепенется, как птица. Свежо, весело, любо!
Свежо, весело, любо!
И.С.Тургенев
Задание 3. Подберем к глаголам одного вида однокоренные глаголы другого вида. Образуем новые слова с помощью приставок.
нес. в. сов. в.
Коптить — за-коптить, под-коптить, на-коптить.
Манить — …
планируешь — …
расту — …
лепечет — …
стрекочу — …
рокочу — …
Задание 4. Подберем к глаголам одного вида однокоренные глаголы другого вида. Образуем новые слова с помощью суффиксов. Какие фонетические явления происходят в некоторых глаголах?
завер-я-ть — завер-и-ть
одол-ева-ть — …
увлажн-я-ть — …
Толк-а-ть- …
угощ-а-ть — (ст//щ)
укрощ-а-ть — (т//щ)
Сопоставим глаголы разного вида по значению и по составу слова.
Задание 5. Работа с текстом «Ветер и птичка».
Прочитайте текст. В чем состоит ошибка? Помогите сверстнику начать сочинение. Спишите исправленное начало текста.
Дополнительное задание. Выполните синтаксический разбор первого (отредактированного) предложения.
Выполните синтаксический разбор первого (отредактированного) предложения.
Пришла весна и дарит земле солнечные лучики. Подул теплый ветер и согревает все живое. Он летел по небу и запел весенние песни.
Вдруг он увидел маленькую птичку. Она потеряла сознание и падала вниз. Он подхватил ее, немного подержал в воздухе и тихонечко положил на землю.
Вскоре птичка пришла в себя. Ветер кружил над ней в воздухе.
— Что случилось? — спросил ветер у птички.
— Зима была очень холодная, я не могла найти корм. Я несколько дней ничего не ела, — объяснила птичка.
Потом они долго разговаривали и подружились и больше не расставались.
Задание 6. Творческая работа.
Глянем в окно. Опишем увиденную картину. Глаголы какого вида используем в своем сочинении? Варианты начала.
А) Сегодня (солнечный, пасмурный…) день.
Б) Близится вечер. За окном…
4. Контроль ЗУН (тест).
1. В каком ряду все глаголы совершенного вида?
А) поговорить, приезжать, знаю
Б) скажет, продолжить, дадут
В) сказали, сдают, покататься
Г) разыскал, кончаем, продадут
2. В каком ряду все глаголы несовершенного вида?
В каком ряду все глаголы несовершенного вида?
А) ухожу, даю, бросаю
Б) испугался, шел, прибежал
В) ждал, едем, мочь
Г) прилетел, рассказывает, жмурится.
3. Какая пара глаголов не является видовой парой?
А) сесть — садиться
Б) делить — разделить
В) класть — положить
Г) идти — ходить.
Использование причастия совершенного вида (Past Participle)
Причастие – это грамматический термин, о котором мы уже рассказывали в одном из наших постов, но подозреваем, что не всем предельно ясно что он означает, а также как и когда нужно причастие использовать. В английском языке два причастия: несовершенного вида (present participle) и совершенного вида (past participle), но поскольку причастие несовершенного вида легче усваивается студентами благодаря единому для всех глаголов окончанию –ing (working, doing, cooking) мы будем рассматривать причастие посложнее – совершенного вида.
Past Participle
Слово «participle» происходит от латинского participium. Определение латинского термина совпадает с английским причастием: неличная форма глагола, имеет характеристики как глагола, так и прилагательного.
Определение латинского термина совпадает с английским причастием: неличная форма глагола, имеет характеристики как глагола, так и прилагательного.
Причастие совершенного вида – одна из пяти основных форм глагола, называемых «principal parts of the verb», при помощи которых и образуются все английские времена.
- Infinitive (инфинитив/начальная форма глагола): to write
- Simple Present (настоящее простое или неопределенное время): write
- Simple Past (прошедшее простое или неопределенное время): wrote
- Past Participle (причастие совершенного вида): written
- Present Participle (причастие несовершенного вида): writing
Только две из указанных основных форм глагола можно использовать в предложении «как есть» — это настоящее простое и прошедшее простое время. Это полностью функциональные глаголы, потому что они показывают грамматическое время, а т.к. их формы сами по себе говорят о времени, они называются «личными» (finite verbs). Три другие формы, включая причастие прошедшего времени, не указывают на грамматическое время.
Три другие формы, включая причастие прошедшего времени, не указывают на грамматическое время.
Глагольные формы, которые не указывают на грамматическое время, называются «неличными» (non-finite verbs). Поскольку они не могут функционировать как полноценные глаголы самостоятельно, их называют verbals — отглагольными словами или опять же — неличными формами глагола.
Будучи неличной формой, причастие совершенного вида сохраняет некоторые функции глагола, хотя выступает в роли прилагательного. Причастие совершенного вида, образованное от правильного глагола, совпадает по форме с глаголом в прошедшем простом времени: оба оканчиваются на -ed:
- Инфинитив: to work
- Настоящее простое время: work
- Прошедшее простое время : worked
- Причастие совершенного вида : worked
- Причастие несовершенного вида: working
Формы причастия совершенного вида неправильных глаголов соответствуют словам, указанным в третьем столбце, и их нужно выучить наизусть, поскольку они принимают участие в образовании английских перфектных времен и страдательного (пассивного) залога: has studied, had built, has travelled, have forgiven, was done, is made, have been finished etc.
Причастие совершенного вида используется также отдельно вне грамматических времен, выполняя в предложении функцию определения: a written letter (написанное письмо), a translated text (переведенный текст), a received salary (полученная зарплата). Хотя причастия «написанное, переведенный, полученная» и отвечают на вопрос «какой? какая?» все же указывают на то, что действие завершено, т.е. зарплата получена, письмо написано и т.п. – отсюда и название причастия – совершенного вида.
Сравним два причастия:
совершенного вида | несовершенного вида |
упавший (fallen) | падающий (falling) |
написанный (written) | пишущий (writing) |
Если научиться правильно отличать причастия друг от друга, будет легче правильно перевести их на английский язык.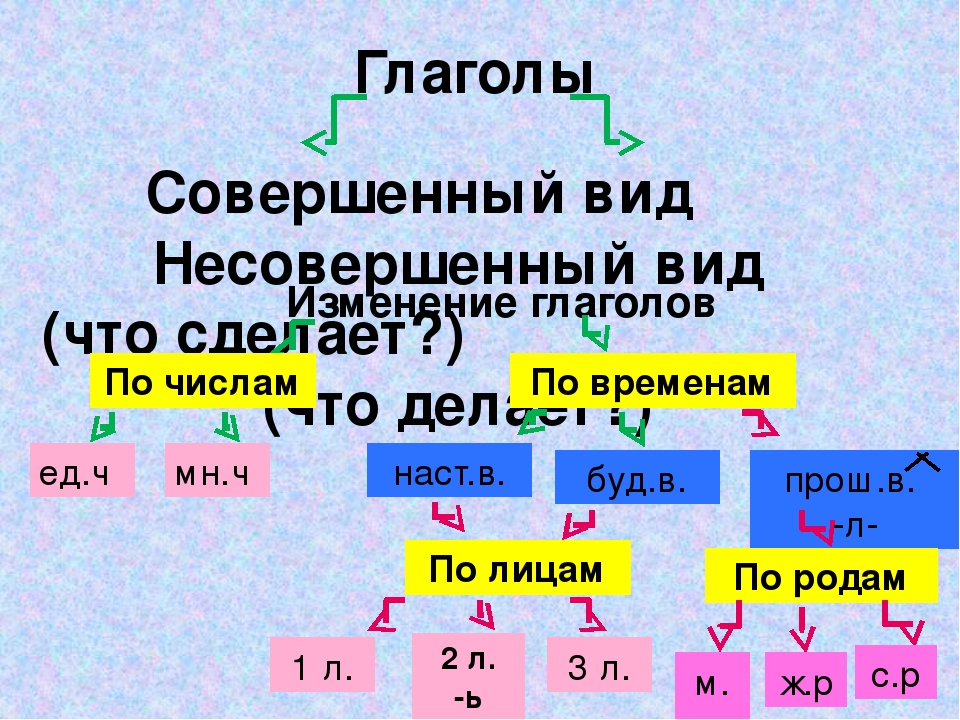
Предлагаем вам пройти небольшой тест.
О том, какую роль могут играть причастия в предложении читайте в посте «Еще немного о причастиях и причастных оборотах»
Глаголы несовершенного вида
Категория вида в современном русском языке представляет собой парное (бинарное) противопоставление глаголов совершенного вида и несовершенного.
Глаголы несовершенного вида обозначают действие, не ограниченное внутренним пределом.
Глаголы несовершенного вида могут иметь следующие частные значения:
1. Конкретно-процессное значение. Указывает на единичное действие в его процессном осуществлении субъектом.
- Спит или читает.
Конкретно-процессное значение имеет следующие оттенки:
а). подчёркнутой длительности (используются лексические показатели типа долго, всю ночь, целый месяц):
- — Вот мы от этой сопки, значит, поплывём, будем плыть весь день.
 ..
.. - (В. Я. Шишков)
- Ты слишком долго рассказываешь об этом.
б). попытка осуществления действия:
в). безуспешные попытки достичь желаемого результата:
- Убеждал, убеждал, но так и не убедил.
г). незавершённость действия:
- Здесь что-то строили.
2. Неограниченно-длительное значение.
- Земля вращается вокруг Солнца, Луна вращается вокруг Земли.
3. Потенциально-постоянное значение.
- Он говорит по-немецки.
Грамматические особенности глаголов несовершенного вида
1. В изъявительном наклонении имеют формы всех трёх времён (настоящего, прошедшего и будущего времени):
- писать — пишу, писал, буду писать
- читать — читаю, читал, буду читать
3. Образуют причастия настоящего времени (могут образовывать причастия прошедшего времени): читать — читающий (действительное, наст. вр.), читаемый (страдательное, наст. вр.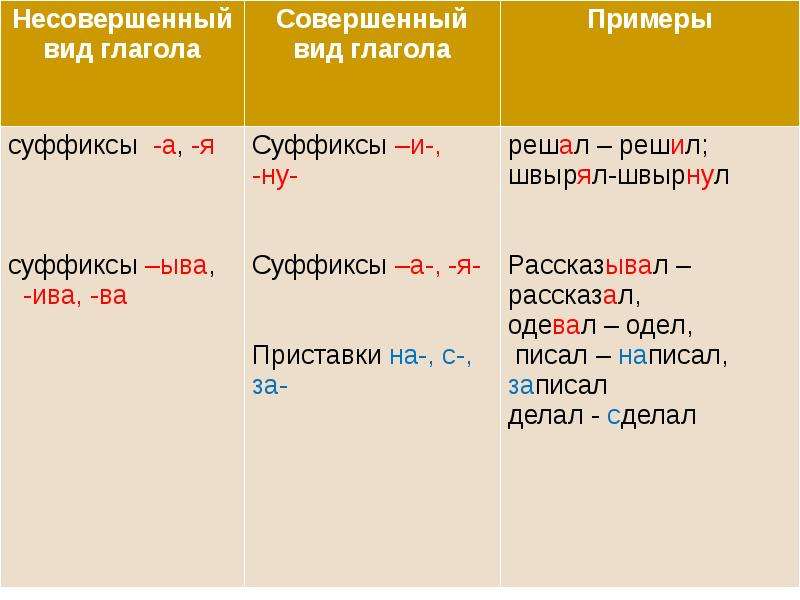 ), читавший (действительное, прош. вр.), читанный (страдательное, прош. вр.).
), читавший (действительное, прош. вр.), читанный (страдательное, прош. вр.).
4. Образуют деепричастия несовершенного вида: читать — читая, говорить — говоря, рассказывать — рассказывая, работать — работая, строиться — строясь, волноваться — волнуясь.
5. Глаголы несовершенного вида сочетаются с фазовыми глаголами (начал, продолжал, закончил): начал говорить, продолжал работать, закончил строить.
6. Сочетаются со словами, указывающими на длительность, повторяемость действия: без конца считал ворон, регулярно пропускал занятия, ежедневно занимался спортом.
Поделиться публикацией:
Причастие в английском языке ‹ engblog.ru
Еще одной неличной формой глагола в английском языке является причастие (Participle). Оно сочетает в себе признаки прилагательного, глагола и наречия. В английском языке нет такой части речи, как деепричастие. Поэтому английское причастие соответствует и причастию, и деепричастию в русском языке. Всего существует два причастия в английском языке: причастие настоящего времени (Participle I / Present Participle) и причастие прошедшего времени (Participle II / Past Participle). Поговорим о каждом из них отдельно.
В английском языке нет такой части речи, как деепричастие. Поэтому английское причастие соответствует и причастию, и деепричастию в русском языке. Всего существует два причастия в английском языке: причастие настоящего времени (Participle I / Present Participle) и причастие прошедшего времени (Participle II / Past Participle). Поговорим о каждом из них отдельно.
Причастие настоящего времени – Participle I
Чтобы образовать это причастие в английском языке, необходимо добавить к основе глагола без частицы to окончание —ing. Если требуется отрицание, то частица not ставится перед причастием.
- walking
- knowing
- smiling и т.д.
Это причастие в английском языке имеет следующие формы:
- Indefinite Active (неопределенное в действительном залоге): asking – спрашивающий, спрашивая (вообще)
- Indefinite Passive (неопределенное в страдательном залоге): being asked – спрашиваемый, будучи спрошен (вообще)
- Perfect Active (совершенное в действительном залоге): having asked – спросив (ши) (уже)
- Perfect Passive (совершенное в страдательном залоге): having been asked – (уже) был спрошен
У непереходных глаголов форм страдательного залога не существует. Это причастие в английском языке обозначает незаконченный процесс и в русском языке соответствует причастию настоящего времени и деепричастию несовершенного вида (речь идет о формах Indefinite). Если мы говорим о формах Perfect, то причастие английского языка будет соответствовать русскому деепричастию совершенного вида. Причастие группы Indefinite, как активного, так и пассивного залога, обозначает, что действие им выраженное происходит одновременно (в настоящем, прошедшем или будущем временах) с действием, выраженным смысловым глаголом-сказуемым. Причастие группы Perfect , как активного, так и пассивного залога, обозначает, что действие им выраженное предшествует действию, выраженным глаголом-сказуемым. Предшествование может относиться также к действию в настоящем, прошедшем или будущем временах.
Это причастие в английском языке обозначает незаконченный процесс и в русском языке соответствует причастию настоящего времени и деепричастию несовершенного вида (речь идет о формах Indefinite). Если мы говорим о формах Perfect, то причастие английского языка будет соответствовать русскому деепричастию совершенного вида. Причастие группы Indefinite, как активного, так и пассивного залога, обозначает, что действие им выраженное происходит одновременно (в настоящем, прошедшем или будущем временах) с действием, выраженным смысловым глаголом-сказуемым. Причастие группы Perfect , как активного, так и пассивного залога, обозначает, что действие им выраженное предшествует действию, выраженным глаголом-сказуемым. Предшествование может относиться также к действию в настоящем, прошедшем или будущем временах.
Причастие настоящего времени в английском языке может выполнять в предложении несколько функций и быть:
- Определением (как и русское причастие), которое стоит перед существительным или после него.
I saw her smiling face in the window. – Я увидел ее улыбающееся лицо в окне.
- Обстоятельством (образа действия, причины, времени).
Knowing English perfectly he was able to watch genuine foreign movies. – Зная английский в совершенстве, он мог смотреть оригинальные иностранные фильмы.
Travelling around the world, he visited as many countries as he could. – Путешествуя вокруг света, он посетил как можно больше стран.
Whistling he closed the door. – Насвистывая, он закрыл дверь.
Причастие прошедшего времени – Participle II
Чтобы образовать это причастие в английском языке от правильных глаголов, необходимо к инфинитиву глагола без частицы to прибавить окончание —ed. У неправильных глаголов форма причастия II особая. Она указана в таблице неправильных глаголов и находится в третьей колонке.
Faded – завявший (цветок), bought — купленный
Это причастие отражает законченный процесс, а на русский язык мы его переводим страдательным причастием совершенного или несовершенного вида. В основном в этом причастии в английском языке представлено действие, которое предшествует действию, выраженному глаголом-сказуемым.
В основном в этом причастии в английском языке представлено действие, которое предшествует действию, выраженному глаголом-сказуемым.
Причастие прошедшего времени в английском языке может выполнять в предложении следующие функции:
- Определения
Broken leg – сломанная нога
Lost time – потерянное время
- Обстоятельства (часто с предшествующими союзами when, if, unless)
When asked important questions, he frowned and answered silly things. – Когда ему задавали важные вопросы, он хмурился и говорил какую-то ерунду.
Из формулировки определения причастия в английском языке (и Participle I, и Participle II) следует, что оно совмещает в себе свойства прилагательного, наречия и глагола. Как и прилагательное, оно может быть в предложении определением к существительному (аналог – русское причастие). Примеры были указаны выше. Как наречие, оно может быть в предложении обстоятельством, как в представленных примерах (аналог – русское деепричастие). А как глагол, оно может иметь прямое дополнение и определяться наречием.
Как наречие, оно может быть в предложении обстоятельством, как в представленных примерах (аналог – русское деепричастие). А как глагол, оно может иметь прямое дополнение и определяться наречием.
Entering the hotel, he noticed the new receptionist. – Входя в гостиницу, он заметил нового администратора.
Seriously injured he continued running. – Серьезно раненый он продолжал бежать.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Распределение биомассы органов в идеальных и несовершенных цветках
Околоцветник M P , гинеций M G и андроеций M A сухая биомасса (в г) 39 видов совершенных цветов был измерен. Эти данные были объединены с опубликованными данными еще по 51 виду и использованы для определения вариаций в зависимости от размера в ( M G и M A ) с точки зрения гипотезы о том, что частное M G и M A превышает 1,0 для аутогамных (ксеногамных) видов и менее 1,0 для инбридинговых (автогамных) видов.![]() Обычная регрессия по методу наименьших квадратов объединенных данных ( n = 90) показала M G = 0 · 118 M 0 · 916 P ( r 2 = 0 884) и M A = 0,186 M 0,975 P ( r 2 = 0,865), что указывает на то, что биомасса гинеция пропорционально уменьшается по мере увеличения размера цветков. Показатели этих регрессий указывают на то, что соотношение гинекологической и андроидной биомассы уменьшалось с увеличением размера цветков, так что сравнительно маленькие цветки ( M P <0,0021 г) имели M G / M A > 1,0 (прогнозируется для аутсайдеров), тогда как у сравнительно более крупных цветков ( M P > 0,0021 г) M G / M A <1,0 ( предсказано для «заводчиков»).Таким образом, в среднем тип системы разведения зависел от размера.
Обычная регрессия по методу наименьших квадратов объединенных данных ( n = 90) показала M G = 0 · 118 M 0 · 916 P ( r 2 = 0 884) и M A = 0,186 M 0,975 P ( r 2 = 0,865), что указывает на то, что биомасса гинеция пропорционально уменьшается по мере увеличения размера цветков. Показатели этих регрессий указывают на то, что соотношение гинекологической и андроидной биомассы уменьшалось с увеличением размера цветков, так что сравнительно маленькие цветки ( M P <0,0021 г) имели M G / M A > 1,0 (прогнозируется для аутсайдеров), тогда как у сравнительно более крупных цветков ( M P > 0,0021 г) M G / M A <1,0 ( предсказано для «заводчиков»).Таким образом, в среднем тип системы разведения зависел от размера.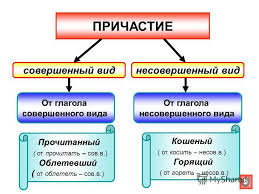
Чтобы проверить, является ли биомасса типа органа цветков допустимым индикатором полового репродуктивного усилия, была определена биомасса (в г) тычинок M m и пыльников M AS 39 видов. Метод наименьших квадратов регрессии этих данных показал M AS = 0 · 188 M 0 · 854 fil ( r 2 = 0,967), что указывает на то, что виды с более крупными волокнами тычинок, на в среднем, пыльники были пропорционально меньшего размера и, таким образом, предостерегали от некритического использования распределения биомассы по типам цветочных органов в качестве строгой меры вложений в гендерные функции.
Чтобы определить, приводит ли потеря одной гендерной функции к пропорциональному перераспределению биомассы к оставшейся гендерной функции, зависимость андроэциальной и гинекологической биомассы от размера была определена для 33 идеальных и несовершенных цветков Cucumis melo . Регрессия данных, полученных для идеальных цветов, дала M A = 0 · 402 M 1 · 47 P ( r 2 = 0 · 898) и M G = 4 · 63 M 1 · 36 P ( r 2 = 0,842).Начиная с M G / M A ∝ M 0 · 11 P , выделение биомассы гинецию по сравнению с андроцеем уменьшалось с увеличением размера цветков. Этот результат согласуется с широким межвидовым сравнением, основанным на 90 видах с идеальными цветками. Регрессия данных для несовершенных цветов дала M A = 0 · 151 M 1 · 02 P ( r 2 = 0,675) и M G = 4 · 68 M 1 · 47 P ( r 2 = 0 · 996), что указывает на близкую аллометрическую зависимость для андроция и сильную положительную анизометрию для гинеция.
Регрессия данных, полученных для идеальных цветов, дала M A = 0 · 402 M 1 · 47 P ( r 2 = 0 · 898) и M G = 4 · 63 M 1 · 36 P ( r 2 = 0,842).Начиная с M G / M A ∝ M 0 · 11 P , выделение биомассы гинецию по сравнению с андроцеем уменьшалось с увеличением размера цветков. Этот результат согласуется с широким межвидовым сравнением, основанным на 90 видах с идеальными цветками. Регрессия данных для несовершенных цветов дала M A = 0 · 151 M 1 · 02 P ( r 2 = 0,675) и M G = 4 · 68 M 1 · 47 P ( r 2 = 0 · 996), что указывает на близкую аллометрическую зависимость для андроция и сильную положительную анизометрию для гинеция. Таким образом, для цветов сопоставимого размера потеря женского пола снова становится от скромной до значительной в андроциальной биомассе, тогда как потеря мужского пола дает лишь небольшое увеличение гиноэциальной биомассы.
Таким образом, для цветов сопоставимого размера потеря женского пола снова становится от скромной до значительной в андроциальной биомассе, тогда как потеря мужского пола дает лишь небольшое увеличение гиноэциальной биомассы.
В совокупности результаты этих исследований показывают, что модели распределения биомассы являются феноменом, зависящим от размера, сложность которого в значительной степени игнорируется в литературе.
Несовершенное обнаружение — обзор
2.7 Динамика заболеваний
Распространение болезней и динамику болезней можно рассматривать как особые случаи географического ареала и совместной встречаемости видов (взаимодействия хозяин-патоген).Прививки, рекомендуемые для людей, путешествующих в различные части мира, основаны на картах распространения болезней. Динамика заболеваний часто представляет большой интерес для эпидемиологов, особенно в случае быстро распространяющихся болезней, таких как вирус Западного Нила (Marra et al., 2004). Эпидемиологические модели динамики заболевания были разработаны для прогнозирования распространения болезнетворных организмов по организмам-хозяевам и, в более общем плане, по космосу (например, Bailey, 1975; Anderson and May, 1991; Elliott et al. , 2001). Несмотря на важность таких моделей, их использование для анализа и лечения заболеваний в популяциях диких животных было ограничено, отчасти из-за несовершенного наблюдения за болезненным состоянием для данного индивидуума, популяции или пространственной единицы (McClintock et al. al., 2010c; Cooch et al., 2012), с которой также сталкиваются эпидемиологи-люди.
, 2001). Несмотря на важность таких моделей, их использование для анализа и лечения заболеваний в популяциях диких животных было ограничено, отчасти из-за несовершенного наблюдения за болезненным состоянием для данного индивидуума, популяции или пространственной единицы (McClintock et al. al., 2010c; Cooch et al., 2012), с которой также сталкиваются эпидемиологи-люди.
Экология болезней дикой природы привлекла значительное внимание из-за появления или повторного появления патогенов, способных переходить в дикие, домашние и / или человеческие популяции (Dobson and Foufopoulos, 2001; Hudson et al., 2002). В течение последнего столетия около 60% всех инфекционных заболеваний и 72% новых инфекционных заболеваний были вызваны патогенами дикого происхождения (Jones et al., 2008), и эти патогены представляют собой существенную угрозу для здоровья человека и глобального биоразнообразия (Daszak и др., 2000). Исследования болезней дикой природы, направленные на понимание воздействия болезни на дикие популяции или распространенность и динамику патогенов, часто делят единицы выборки (особи, популяции или участки среды обитания) на состояния (например,g. , восприимчивые, инфицированные, постинфицированные). Например, Senar and Conroy (2004) и Jennelle et al. (2007) рассматривали простую систему болезней с двумя состояниями, в которой люди классифицировались как «инфицированные» или «незараженные». Оценки распространенности, определяемые как доля инфицированных лиц в целевой популяции, и выводы о динамике заболевания могут быть сильно искажены, если игнорировать вероятности обнаружения для конкретных состояний (Senar and Conroy, 2004; Jennelle et al., 2007; Cooch и другие., 2012). Подходы отлова-повторного отлова использовались для оценки воздействия патогенов на демографические характеристики хозяина и оценки передачи заболевания в сценариях, включающих одну или несколько популяций, где особи могут быть помечены или распознаны (например, Senar and Conroy, 2004; Pilliod et al., 2010; Conn et al., 2012; Cooch et al., 2012). Аналогичным образом, Кендалл (2009) и МакКлинток и др. (2010c) описали использование моделирования занятости для вывода динамики заболевания в пространстве и времени.
, восприимчивые, инфицированные, постинфицированные). Например, Senar and Conroy (2004) и Jennelle et al. (2007) рассматривали простую систему болезней с двумя состояниями, в которой люди классифицировались как «инфицированные» или «незараженные». Оценки распространенности, определяемые как доля инфицированных лиц в целевой популяции, и выводы о динамике заболевания могут быть сильно искажены, если игнорировать вероятности обнаружения для конкретных состояний (Senar and Conroy, 2004; Jennelle et al., 2007; Cooch и другие., 2012). Подходы отлова-повторного отлова использовались для оценки воздействия патогенов на демографические характеристики хозяина и оценки передачи заболевания в сценариях, включающих одну или несколько популяций, где особи могут быть помечены или распознаны (например, Senar and Conroy, 2004; Pilliod et al., 2010; Conn et al., 2012; Cooch et al., 2012). Аналогичным образом, Кендалл (2009) и МакКлинток и др. (2010c) описали использование моделирования занятости для вывода динамики заболевания в пространстве и времени. Если каждый наблюдаемый индивидуум считается независимым участком, а занятость определяется как наличие болезни (или патогена), то оценки занятости аналогичны распространенности болезни / патогена, а оценки вероятностей колонизации и исчезновения аналогичны инфекции или повторной инфекции, и вероятности «восстановления».
Если каждый наблюдаемый индивидуум считается независимым участком, а занятость определяется как наличие болезни (или патогена), то оценки занятости аналогичны распространенности болезни / патогена, а оценки вероятностей колонизации и исчезновения аналогичны инфекции или повторной инфекции, и вероятности «восстановления».
Кроме того, подходы занятости могут применяться к различным иерархическим шкалам для изучения факторов, связанных с присутствием патогена в нескольких популяциях хозяев или в определенных пространственных единицах (Kendall, 2009; McClintock et al., 2010c). Понимание факторов, влияющих на распространение патогена, и определение условий, при которых он передается среди, казалось бы, изолированных популяций хозяев, является основной темой в экологии болезней и географической эпидемиологии. В этих случаях несовершенное обнаружение возможно как для хозяина, так и для видов патогена, что препятствует возможности непосредственного наблюдения за интересующими процессами. Это может привести к неправильной классификации популяции хозяев или единицы выборки как незанятых патогеном, когда патоген присутствует. Частично то, что делает надежные выводы о динамике болезни настолько сложными, — это разнообразие способов возникновения неопределенности в системе, от выбора единиц пробы до отбора проб хозяев и видов патогенов, обращения с собранными пробами и их диагностики ( Рис. 2.6, из McClintock et al., 2010c). На примере высокопатогенного азиатского штамма вируса птичьего гриппа H5N1 (HPAIV) в популяциях водоплавающих птиц, населяющих водно-болотные угодья, на рис.2.6 описывает многочисленные процессы отбора проб, каждый из которых потенциально может не обнаружиться, а некоторые процессы отбора проб могут давать ложноположительные результаты. Существует широкий спектр методов, используемых для определения наличия или воздействия патогена или заболевания, включая прямое наблюдение (например, Jennelle et al., 2007) и лабораторные анализы, в которых используются различные образцы материала (например, вода, сыворотка, кровь и т.
Это может привести к неправильной классификации популяции хозяев или единицы выборки как незанятых патогеном, когда патоген присутствует. Частично то, что делает надежные выводы о динамике болезни настолько сложными, — это разнообразие способов возникновения неопределенности в системе, от выбора единиц пробы до отбора проб хозяев и видов патогенов, обращения с собранными пробами и их диагностики ( Рис. 2.6, из McClintock et al., 2010c). На примере высокопатогенного азиатского штамма вируса птичьего гриппа H5N1 (HPAIV) в популяциях водоплавающих птиц, населяющих водно-болотные угодья, на рис.2.6 описывает многочисленные процессы отбора проб, каждый из которых потенциально может не обнаружиться, а некоторые процессы отбора проб могут давать ложноположительные результаты. Существует широкий спектр методов, используемых для определения наличия или воздействия патогена или заболевания, включая прямое наблюдение (например, Jennelle et al., 2007) и лабораторные анализы, в которых используются различные образцы материала (например, вода, сыворотка, кровь и т. Д.) . Эти методы могут приводить к ложноотрицательным и ложноположительным результатам. Количественная оценка ложноположительных и ложноотрицательных ошибок (специфичность и чувствительность) не является редкостью в литературе по заболеваниям (например,g., Carey et al., 2006), что привело к появлению множества статистических методов, которые пытаются скорректировать точность теста (см. обзор Enøe et al., 2000). Модели занятости, обсуждаемые в этой книге, напрямую связаны с обнаружением и ошибочной классификацией (или неопределенностью состояния; главы 6 и 10), чтобы обеспечить объективные оценки эффектов болезни, а также распространенности и динамики патогенов в пространстве и времени.
Д.) . Эти методы могут приводить к ложноотрицательным и ложноположительным результатам. Количественная оценка ложноположительных и ложноотрицательных ошибок (специфичность и чувствительность) не является редкостью в литературе по заболеваниям (например,g., Carey et al., 2006), что привело к появлению множества статистических методов, которые пытаются скорректировать точность теста (см. обзор Enøe et al., 2000). Модели занятости, обсуждаемые в этой книге, напрямую связаны с обнаружением и ошибочной классификацией (или неопределенностью состояния; главы 6 и 10), чтобы обеспечить объективные оценки эффектов болезни, а также распространенности и динамики патогенов в пространстве и времени.
Рисунок 2.6. Концептуализация бесчисленного множества способов возникновения неопределенности в экологии болезней диких животных (например,g., птичий грипп в популяциях водоплавающих птиц), от пространственно-временного распределения усилий по отбору проб в полевых условиях (A) до лабораторных методов (B). Красный цвет указывает на инфицированные образцы и единицы образцов. Независимо от того, инфицирован образец или нет, возможны ложноотрицательные или ложноположительные результаты теста.
Красный цвет указывает на инфицированные образцы и единицы образцов. Независимо от того, инфицирован образец или нет, возможны ложноотрицательные или ложноположительные результаты теста.
Источник: Источник: McClintock et al. (2010c).
Рисунок 2.7. Иерархическая формулировка неопределенности в экологии болезней диких животных в рамках четырех общих тем. В зависимости от болезненного состояния на верхних уровнях множество различных путей отбора проб могут привести к ложноотрицательному или ложноположительному результату при анализе на уровне 4.Пространственные субъединицы могут быть добавлены или удалены на уровне 2 иерархии.
Источник: Источник: McClintock et al. (2010c).
Подходы к моделированию занятости начали появляться в литературе о болезнях диких животных. Bailey et al. (2014) подчеркнули важность целей и дизайна исследования, а также соответствующих допущений модели при применении моделей занятости к системам болезней. Эти авторы иллюстрируют, как разные цели, связанные с заболеванием, приводят к кардинально различающимся планам исследований с применением моделей занятости к данным обнаружения-необнаружения, собранным на уровне отдельного человека, популяции или места.
Наиболее распространенное приложение для определения занятости включает оценку распространенности патогенных микроорганизмов с помощью односезонных моделей (глава 4) и исследование различий в обнаружении различных лабораторных методов или индивидуальных характеристик хозяина (например, возраста, пола). Этот подход использовался для оценки распространенности нескольких патогенов, включая паразитов у рыб (например, Thompson, 2007, вихревая болезнь) и птиц (например, Lachish et al., 2012, птичья малярия), грибковых патогенов земноводных (например, Miller et al. al., 2012b; Schmidt et al., 2013, хитридовый гриб) и бактерии в переносчиках болезней (например, Gómez-Díaz et al., 2010, болезнь Лайма). Аналогичным образом, Элмор и его коллеги использовали модели занятости за один сезон для оценки различий в обнаружении серологических анализов при оценке воздействия Toxoplasma gondii (т.е. распространенности антител) у песцов ( Vulpes lagapus ; Elmore et al., 2016) и мигрирующих гусей. (Элмор и др., 2014). Различия в обнаружении патогенов часто связаны с интенсивностью инфекции или патогенной нагрузкой (Gómez-Díaz et al., 2010; Miller et al., 2012b; Лачиш и др., 2012). Когда количественные измерения этих показателей недоступны, модели занятости, представленные в главе 7, можно использовать для учета вызванной интенсивностью неоднородности при обнаружении патогенов (например, Lachish et al., 2012). Два важных допущения этих приложений занятости заключаются в том, что захваченные лица являются случайным подмножеством интересующей совокупности и что нет ложноположительных обнаружений. Элмор и др. (2014) использовали многоуровневые модели (глава 5) для учета неоднозначных результатов тестирования, но модели из глав 6 и 10 также должны быть полезны, если есть подозрения на ложноположительные результаты теста.Когда особи не отлавливаются случайным образом из популяции (например, больные особи с большей или меньшей вероятностью будут отловлены, чем здоровые; Jennelle et al.
(Элмор и др., 2014). Различия в обнаружении патогенов часто связаны с интенсивностью инфекции или патогенной нагрузкой (Gómez-Díaz et al., 2010; Miller et al., 2012b; Лачиш и др., 2012). Когда количественные измерения этих показателей недоступны, модели занятости, представленные в главе 7, можно использовать для учета вызванной интенсивностью неоднородности при обнаружении патогенов (например, Lachish et al., 2012). Два важных допущения этих приложений занятости заключаются в том, что захваченные лица являются случайным подмножеством интересующей совокупности и что нет ложноположительных обнаружений. Элмор и др. (2014) использовали многоуровневые модели (глава 5) для учета неоднозначных результатов тестирования, но модели из глав 6 и 10 также должны быть полезны, если есть подозрения на ложноположительные результаты теста.Когда особи не отлавливаются случайным образом из популяции (например, больные особи с большей или меньшей вероятностью будут отловлены, чем здоровые; Jennelle et al. , 2007), могут применяться модели захвата – повторной поимки с несколькими штатами и модели занятости. можно объединить, чтобы сделать выводы на уровне популяции.
, 2007), могут применяться модели захвата – повторной поимки с несколькими штатами и модели занятости. можно объединить, чтобы сделать выводы на уровне популяции.
Несколько недавних исследований были сосредоточены на распространенности или возникновении переносчиков болезней и их динамике во времени. Идс и др. (2013, 2015) изучали динамику заселения клещами у чернохвостых луговых собачек ( Cynomys ludovicianus ), чтобы лучше понять вспышки чумы, которые влияют как на луговые собачки, так и на популяцию черноногих хорьков ( Mustela nigripes ).В Неотропах Абад-Франч и его коллеги использовали модели занятости для оценки встречаемости кровососущих триатомовых клопов («целующихся клопов», наиболее важного переносчика болезни Шагаса) среди пальм (например, Abad-Franch et al., 2010, 2015) и лучше понять динамику переносимых комарами переносчиков, ответственных за передачу вируса денге (Padilla-Torres et al., 2013).
В большинстве приведенных выше примеров интересующей единицей выборки является отдельный организм (например, рыба, птица, млекопитающее или растение), но иногда исследователей интересует распределение патогена среди популяций хозяев. Этот подход был использован для исследования факторов, влияющих на распространение грибкового патогена Batrachochytrium dendrobatidis среди популяций амфибий на северо-западе Тихого океана (Adams et al., 2010), Аризоне (Schmidt et al., 2013) и в других местах в Соединенных Штатах. (Chestnut et al., 2014).
Этот подход был использован для исследования факторов, влияющих на распространение грибкового патогена Batrachochytrium dendrobatidis среди популяций амфибий на северо-западе Тихого океана (Adams et al., 2010), Аризоне (Schmidt et al., 2013) и в других местах в Соединенных Штатах. (Chestnut et al., 2014).
Хотя многие системы заболеваний имеют иерархическую природу (рис. 2.7, из McClintock et al., 2010c), немногие исследователи использовали многомасштабные модели занятости (но см. Schmidt et al., 2013; Элмор и др., 2014). Мы подозреваем, что модели занятости, представленные в главах 5 и 9, будут становиться все более популярными, поскольку данные обнаружения-необнаружения собираются на нескольких уровнях (например, на уровне хозяина и патогена). Поскольку для многих диагностических тестов возможны как ложноотрицательные, так и ложноположительные результаты, мы считаем, что модели, учитывающие оба типа ошибок (главы 6 и 10), будут важны в будущих исследованиях систем заболеваний. Наконец, динамика хозяина, несомненно, связана с динамикой патогена, где обнаружение патогена может зависеть от присутствия и / или обнаружения целевого вида хозяина.В этих случаях исследователи могут выбрать использование модели совместной встречаемости или многовидовой модели (главы 14 и 15) для одновременного исследования факторов, влияющих на динамику патоген-хозяин, или изучения многовидовых концепций, таких как эффект разбавления (например, Keesing et al. al., 2010) с учетом невыявления хозяев и патогенов.
Наконец, динамика хозяина, несомненно, связана с динамикой патогена, где обнаружение патогена может зависеть от присутствия и / или обнаружения целевого вида хозяина.В этих случаях исследователи могут выбрать использование модели совместной встречаемости или многовидовой модели (главы 14 и 15) для одновременного исследования факторов, влияющих на динамику патоген-хозяин, или изучения многовидовых концепций, таких как эффект разбавления (например, Keesing et al. al., 2010) с учетом невыявления хозяев и патогенов.
Идеальные и несовершенные цветочные расслоения
Целевой уровень / возрастной диапазон:
7 класс
Время:
Два 45-минутных урока
Цель:
Определить мужские и женские структуры цветка, распознать их функцию в воспроизводстве и различать идеальные и несовершенные цветы.
Материалы:
- Perfect Flowers (лилии — хороший вариант)
- Скальпели
- Микроскопы
- Предметное стекло для микроскопа
- Покровные стекла
- Глицерин
- Большие карточки для заметок
- Лента для упаковки кукурузы
- Сладкая кукуруза может быть лучшим вариантом.
 Чтобы вырасти до кисточки, потребуется около 50 дней. Если возможно, выращивайте в школьной теплице.
Чтобы вырасти до кисточки, потребуется около 50 дней. Если возможно, выращивайте в школьной теплице. - Изображения могут быть использованы для изменения упражнения 2, если использование настоящего растения кукурузы нецелесообразно.
кисточкой
Рекомендуемые сопутствующие ресурсы (книги и веб-сайты)
Словарь (с определениями)
- Perfect Flower : в одном цветке мужские и женские структуры
- Несовершенный цветок :
цветок, не имеющий одновременно мужских и женских структур - Тычинки : мужское строение
цветок - Пыльник : часть
тычинка, содержащая пыльцу - Нить : часть
тычинка, поддерживающая
пыльник - Пестик : охватывающая часть
цветок - Стигма : верхушка пестика, куда попадает пыльца
- Стиль : средняя часть
пестик, через который проходит пыльца - Яичник : основание пестика, содержащего яйца
- Яйцо : там, где пыльца встречается с яйцеклеткой в яичнике
- Пыльца : тонкое порошкообразное вещество, выделяющееся из пыльника, содержащего мужскую гамету, оплодотворяющую семяпочку.

- Опыление : процесс, посредством которого пыльца передается женским репродуктивным органам растения, тем самым обеспечивая возможность оплодотворения.
- Tassel : мужские структуры кукурузы (пыльник, нить)
- Silk : часть женских структур кукурузного растения (початок), включая клеймо и стиль
Предпосылки — Сельскохозяйственные связи (что нужно знать учителю, чтобы преподавать этот материал)
- Perfect vs.Несовершенные цветы
- Идеальные цветки содержат как мужские репродуктивные структуры (тычинки), так и женские репродуктивные структуры (пестик).
- Тычинка содержит пыльник, удерживающий пыльцу, и нить, поддерживающую пыльник.
- Пестик содержит рыльце, к которому прилипает пыльца; стиль, через который проходит пыльца; и яичник, где пыльца встречается с яйцеклеткой и происходит оплодотворение.
- Лилии — пример идеального цветка.

- Соевые бобы тоже имеют идеальные цветы, но эти цветы очень маленькие, и их, возможно, не лучше всего рассекать.
- Говоря о причинах удаления метелки с кукурузы, вспомните о соевых бобах и поговорите о том, как их маленькие идеальные цветки повлияют на производство гибридных семян этого вида.
- Несовершенные цветы содержат либо мужскую часть, либо женскую часть цветка, но не обе вместе.
- Кукуруза — пример растения с несовершенными цветками.
- Кукуруза состоит из двух цветов: кисточки и початка.
- Кисточка (мужской цветок) содержит пыльники и отвечает за производство пыльцы.
- Шелк на ухе (женский цветок) содержит клеймо и стиль. Каждое ядро - это отдельная яйцеклетка.
- Кукуруза — пример растения с несовершенными цветками.
- Идеальные цветки содержат как мужские репродуктивные структуры (тычинки), так и женские репродуктивные структуры (пестик).
- Полные и неполные цветы
- Готовые цветки состоят из четырех частей: лепестков, чашелистиков, тычинок и пестика.
- В неполных цветках отсутствует одна или несколько из этих четырех частей.

- Совершенный цветок может быть неполным, но несовершенный цветок не может быть полным.
- Detasseling
- Как это ни звучит, удаление метелок — это процесс удаления кисточки с растения кукурузы.
- Кукуруза снимается только тогда, когда поле будет использоваться для посевной кукурузы. Кукуруза, посаженная для других целей (корм, этанол или переработка в сиропы, волокна или другие продукты), будет опылять сама себя, и эти фермеры не будут очищать свои посевы от метеоритов.
- Семенную кукурузу снимают, чтобы растение не опыляло собственные початки. Когда это происходит, производители могут сажать «мужские ряды» и «женские ряды», которые вместе дают гибридное семя.
- «Мужские ряды» и «женские ряды» представляют собой растения кукурузы разных
разновидностей, или которые демонстрируют немного разные черты. Их объединение создаст гибрид. - Обычно на каждый мужской ряд приходится примерно 3-4 женских ряда.
 Женские ряды отделяют, а мужские ряды оставляют для их опыления. Кукуруза опыляется ветром.
Женские ряды отделяют, а мужские ряды оставляют для их опыления. Кукуруза опыляется ветром. - Гибридные растения
полезны, потому что они могут брать положительные черты двух разных сортов и комбинировать их для создания лучшего следующего поколения. Гибридные растения также демонстрируют «гибридную силу» или гетерозис, что означает, что потомство первого поколения будет работать лучше, чем любой родитель. Такая же польза наблюдается у животных, скрещенных между двумя
породы, и более подробно объясняется здесь:
http: // www.iowabeefcenter.org/bch/CrossbreedingGeneticsPrinciples.pdf
- «Мужские ряды» и «женские ряды» представляют собой растения кукурузы разных
Подход интереса или мотиватор
Спросите учащихся, для чего, по их мнению, нужны цветы. Что представляет собой цветок? Они просто красивые?
Процедуры
День первый :
- Дайте каждой группе студентов из 2 или 3 идеальный цветок, лист бумаги (чтобы разрезать цветок) и копию Учебного листа для студентов по цветам.

- Этот учебный лист содержит места для
заметки и справочные изображения. Это поможет в учебе позже. Сообщите учащимся, что он не будет оцениваться, но будет полезным ресурсом и хорошим местом для заметок.
- Этот учебный лист содержит места для
- Прежде чем раздавать скальпели, объясните студентам процесс урока. Сообщите им, что сначала они будут рисовать свои цветы и маркировать структуры в своих научных тетрадях. Затем они удаляют тычинку и пестик, маркируют эти структуры и прикрепляют их к карточкам.Попросите учащихся задавать вопросы, если они есть, потому что после того, как кусочки оторваны от цветка, их нельзя будет снова надеть.
- Попросите учащихся достать свои тетради, нарисовать и наклеить
цветок. Ответьте на вопросы, если они возникнут. А сейчас поговорите о других структурах, которые они могут увидеть на цветке. Как выглядят лепестки? Вы видите стебель? Есть ли на этом цветке чашелистики?- Объясните классу, что цветок с чашелистиками, лепестками, тычинками и пестиками называется цельным.
 Если в цветке отсутствует одна из этих частей, она называется неполной. Спросите студентов, может ли цветок быть совершенным и неполным. Ответ — да, может быть.
Если в цветке отсутствует одна из этих частей, она называется неполной. Спросите студентов, может ли цветок быть совершенным и неполным. Ответ — да, может быть.
- Объясните классу, что цветок с чашелистиками, лепестками, тычинками и пестиками называется цельным.
- Попросите учащихся удалить тычинки с цветка и поместить их на карточку. Затем пометьте карточку «тычинка» и пометьте пыльник и нить.
- Помогите студентам сделать предметные стекла микроскопа из пыльцы.
- Попросите группы нанести небольшую каплю глицерина на чистое предметное стекло, затем возьмите одну из оставшихся тычинок и постучите пыльником по предметному стеклу, поместите
покровное стекло на предметном стекле и просмотрите его под микроскопом. - Альтернативные способы монтажа:
- Попросите учащихся делать наблюдения, рисовать иллюстрации и делать записи в своей научной тетради.
- Попросите группы нанести небольшую каплю глицерина на чистое предметное стекло, затем возьмите одну из оставшихся тычинок и постучите пыльником по предметному стеклу, поместите
- Затем попросите группы удалить пестик из основания цветка.

- Скажите им, чтобы они использовали скальпель, чтобы разрезать яичник поперек, и ущипнуть яичник, пока одна или несколько семяпочек не выйдут наружу.
- Попросите учащихся наблюдать, делать наброски и делать записи в своих тетрадях.
- Попросите учащихся поместить пестик на вторую карточку и пометить клеймо, стиль, завязь и яйцеклетку.
- Помогите студентам наклеить полоску упаковочной ленты на цветочные конструкции, прикрепив их к карточке.
- Попросите учащихся написать имена всех членов группы на обратной стороне карточки и сдать карточки в конце урока.
День второй :
- Предложите учащимся понаблюдать за кукурузой.Задайте им такие вопросы, как:
- Где цветок на этом растении?
- Как узнать, что это за цветок?
- Какова цель
цветок кукурузы или любой другой цветок?
- Предложите учащимся манипулировать кисточкой растения и собирать пыльцу, чтобы посмотреть на нее под микроскопом.

- Помогите учащимся создавать слайды, как в предыдущем уроке, делать наблюдения и записывать результаты.
- Снимите початок кукурузы и очистите ее от шелухи.
Обсудите назначение шелка на конце уха. Разнесите кукурузный початок по комнате, чтобы студенты могли наблюдать и делать записи, как они это делали для семяпочки в прошлом уроке. - Объясните путь, который должна пройти пыльца для опыления и оплодотворения.
- Спросите студентов, почему важно удобрять кукурузу.
- Расскажите о факторах, которые могут повлиять на успех
при неудачном опылении.- Некоторые факторы могут быть
рост кистей, рост шелка,
расстояние между ними, количество ветра, питание растения, вредители растений и т. д.
- Некоторые факторы могут быть
- Попросите учащихся заглянуть в свои записные книжки. Посмотрите на сходства и различия между вчерашним цветком и сегодняшним кукурузным растением.
 Предложите им сравнить и сопоставить эти два предмета как класс.
Предложите им сравнить и сопоставить эти два предмета как класс.- Поговорите о том, какое растение имеет идеальные и несовершенные цветы. Которая есть полная и неполная. Это почему?
- Проведите обсуждение по поводу удаления меток и того, почему это практикуется.
- Представьте идею кроссбридинга и селективного разведения. Спросите студентов, почему люди могут захотеть использовать эти методы.
- Помогите студентам узнать, что не вся кукуруза засевается для потребления; некоторые должны быть посажены на семена в последующие годы.
- Следовательно, не все
очищены кукурузные поля; только те, что посеяны на посевной материал. - Эти поля будут иметь «мужские» ряды между каждыми тремя или четырьмя женскими рядами для их опыления. Это будет то, что создает гибридные семена.
- Следовательно, не все
- Завершите короткое обсуждение и попросите учащихся завершить заполнение своих учебных листов.

Основные файлы (карты, диаграммы, изображения или документы)
Знаете ли вы? (Ag Facts)
- В Айове выращивается больше кукурузы, чем в любом другом штате — больше кукурузы с полей, а не сладкой.
- Айова также является лидером страны по производству сои, яиц и свинины.
- Кукуруза используется во множестве продуктов, от упаковки арахиса до хлопьев, ковров и пластмасс!
Дополнительные задания (как учащиеся могут носить это вне класса)
- Попросите учащихся собрать пять разных типов цветов и определить, идеальные они или несовершенные.
- Попросите учащихся провести исследование общих сельскохозяйственных культур штата Айова и способов их опыления.
Источники / кредиты
Автор (ы) (ваше имя)
Организация (ваша организация)
- Общественные школы Су-Сити
Национальные результаты по повышению грамотности в сельском хозяйстве
- Наука, технологии, инженерия и математика:
- T4.
 6-8.b: Опишите, как биологические процессы влияют и используются в сельскохозяйственном производстве и переработке (например, фотосинтез, ферментация, деление клеток, наследственность / генетика, азотфиксация)
6-8.b: Опишите, как биологические процессы влияют и используются в сельскохозяйственном производстве и переработке (например, фотосинтез, ферментация, деление клеток, наследственность / генетика, азотфиксация)
- T4.
Основные стандарты штата Айова
- Наука:
- MS-LS1-4 Используйте аргументы, основанные на эмпирических данных и научных рассуждениях, в поддержку объяснения того, как характерное поведение животных и специализированные структуры растений влияют на вероятность успешного воспроизводства животных и растений соответственно.
- MS-LS1-5 Составьте научное объяснение, основанное на доказательствах того, как экологические и генетические факторы влияют на рост организмов.
Это произведение находится под лицензией
Международная лицензия Creative Commons Attribution 4.0.
Понимание идеальной и несовершенной конкуренции
Конкуренция между совершенным и несовершенным: обзор
Совершенная конкуренция — это концепция в микроэкономике, которая описывает структуру рынка, полностью контролируемую рыночными силами. Если и когда эти силы не встречаются, говорят, что на рынке несовершенная конкуренция.
Если и когда эти силы не встречаются, говорят, что на рынке несовершенная конкуренция.
Хотя ни один рынок не дал четкого определения совершенной конкуренции, все реальные рынки классифицируются как несовершенные. При этом идеальный рынок используется в качестве стандарта, с помощью которого можно измерить эффективность и действенность реальных рынков.
Идеальная конкуренция
Совершенная конкуренция — это абстрактное понятие, которое встречается в учебниках по экономике, но не в реальном мире.Это потому, что этого невозможно достичь в реальной жизни.
Теоретически ресурсы будут разделены между компаниями поровну и справедливо на рынке с совершенной конкуренцией, и никакой монополии не будет. У каждой компании будут одинаковые отраслевые знания, и все они будут продавать одни и те же продукты. На этом рынке будет много покупателей и продавцов, а спрос поможет установить цены равномерно по всем направлениям.
Чтобы на рынке существовала совершенная конкуренция, должны быть:
- Идентичные товары, продаваемые компаниями
- Среда, в которой цены определяются спросом и предложением, что означает, что компании не могут контролировать рыночные цены на свою продукцию
- Равная доля рынка между компаниями
- Полная информация о ценах и товарах доступна всем покупателям
- Отрасль с низкими барьерами для входа или выхода или без них
Вход и выход в условиях совершенной рыночной конкуренции не регулируются, что означает, что государство не контролирует игроков в какой-либо отрасли.
Когда дело доходит до чистой прибыли, компании обычно получают достаточно прибыли, чтобы оставаться в бизнесе. Ни один бизнес не может быть прибыльнее другого. Это потому, что динамика рынка заставляет их действовать на равных условиях, тем самым сводя на нет любое возможное преимущество, которое может иметь одно над другим.
Поскольку совершенная конкуренция — это чисто теоретическая концепция, трудно найти реальный пример. Но на рынке есть экземпляры, в которых может казаться совершенно конкурентная среда.Блошиный рынок или фермерский рынок — два примера. Рассмотрим рыночные прилавки с четырьмя ремесленниками или фермерами, которые продают одни и те же продукты. Эта рыночная среда характеризуется небольшим количеством покупателей и продавцов. Может быть мало различий между продуктами, которые продает каждый ремесленник или фермер, а также их цены, которые обычно устанавливаются между ними одинаково.
Несовершенная конкуренция
Несовершенная конкуренция возникает на рынке, когда одно из условий совершенно конкурентного рынка остается невыполненным. Этот тип рынка очень распространен. Фактически, в каждой отрасли существует несовершенная конкуренция. Это включает рынок с различными продуктами и услугами, цены, которые не устанавливаются спросом и предложением, конкуренцию за долю рынка, покупателей, которые могут не иметь полной информации о продуктах и ценах, а также высокие барьеры для входа и выхода.
Этот тип рынка очень распространен. Фактически, в каждой отрасли существует несовершенная конкуренция. Это включает рынок с различными продуктами и услугами, цены, которые не устанавливаются спросом и предложением, конкуренцию за долю рынка, покупателей, которые могут не иметь полной информации о продуктах и ценах, а также высокие барьеры для входа и выхода.
Несовершенную конкуренцию можно найти в следующих типах рыночных структур: монополии, олигополии, монополистическая конкуренция, монопсонии и олигопсонии.
В монополиях есть только один (доминирующий) продавец. Эта компания предлагает рынку продукт, которому нет замены. У монополий есть высокие барьеры для входа на рынок, а ценообразование определяет один продавец. Это означает, что фирма устанавливает цену, по которой ее продукт будет продаваться независимо от спроса или предложения. Наконец, фирма может изменить цену в любое время без уведомления потребителей.
В олигополии много покупателей, но мало продавцов. Нефтяные компании, продуктовые магазины, компании по производству мобильных телефонов и производители шин являются примерами олигополий.Поскольку рынок контролируют несколько игроков, они могут запретить другим входить в отрасль. Фирмы в этой рыночной структуре устанавливают цены на продукты и услуги коллективно или, в случае картеля, они могут это делать, если кто-то берет на себя инициативу.
Нефтяные компании, продуктовые магазины, компании по производству мобильных телефонов и производители шин являются примерами олигополий.Поскольку рынок контролируют несколько игроков, они могут запретить другим входить в отрасль. Фирмы в этой рыночной структуре устанавливают цены на продукты и услуги коллективно или, в случае картеля, они могут это делать, если кто-то берет на себя инициативу.
Монополистическая конкуренция возникает, когда есть много продавцов, предлагающих аналогичные продукты, которые не обязательно заменяются. Хотя барьеры для входа на рынок довольно низкие, а компании в этой структуре определяют цены, общие бизнес-решения одной компании не влияют на ее конкуренцию.Примеры включают рестораны быстрого питания, такие как McDonald’s и Burger King. Несмотря на то, что они находятся в прямой конкуренции, они предлагают аналогичные продукты, которые нельзя заменить — например, Биг Мак против Воппера.
Монопсонии и олигопсонии противостоят монополиям и олигополиям. Вместо того, чтобы состоять из множества покупателей и немногих продавцов, на этих уникальных рынках много продавцов, но мало покупателей. Многие фирмы создают продукты и услуги и пытаются продать их единственному покупателю — военным США, что представляет собой монопсонию.Примером олигопсонии является табачная промышленность. Почти весь табак, выращиваемый в мире, закупается менее чем пятью компаниями, которые используют его для производства сигарет и бездымных табачных изделий. В монопсонии или олигопсонии покупатель, а не продавец может манипулировать рыночными ценами, настраивая фирмы друг против друга.
Вместо того, чтобы состоять из множества покупателей и немногих продавцов, на этих уникальных рынках много продавцов, но мало покупателей. Многие фирмы создают продукты и услуги и пытаются продать их единственному покупателю — военным США, что представляет собой монопсонию.Примером олигопсонии является табачная промышленность. Почти весь табак, выращиваемый в мире, закупается менее чем пятью компаниями, которые используют его для производства сигарет и бездымных табачных изделий. В монопсонии или олигопсонии покупатель, а не продавец может манипулировать рыночными ценами, настраивая фирмы друг против друга.
Ключевые выводы
- Структура рынка полностью контролируется рыночными силами в условиях совершенной конкуренции.
- В условиях совершенной конкуренции идентичные продукты продаются, цены устанавливаются спросом и предложением, рыночная доля распределяется между всеми фирмами, покупатели имеют полную информацию о продуктах и ценах, а барьеры для входа или выхода низкие или отсутствуют.

- В реальном мире идеальной конкуренции нет, но рынки представлены несовершенной конкуренцией.
- Несовершенная конкуренция возникает, когда не выполняется хотя бы одно условие идеального рынка.
- Примеры несовершенной конкуренции включают, помимо прочего, монополии и олигополии.
Перейти к основному содержанию
Поиск
Поиск
- Где угодно
Быстрый поиск где угодно
Поиск Поиск
Расширенный поиск
Войти | регистр
Пропустить основную навигацию Закрыть меню ящика Открыть меню ящика Домой
- Подписка / продление
- Учреждения
- Индивидуальные подписки
- Индивидуальные продления
- Библиотекари
- полные платежи Чикагский пакет
- Полный охват и охват содержимого
- Файлы KBART и RSS-каналы
- Разрешения и перепечатки
- Инициатива развивающихся стран Чикаго
- Даты отправки и претензии
- Часто задаваемые вопросы библиотекарей
- Расценки, заказы
- и платежи
- О нас
- Публикуйте у нас
- Недавно приобретенные журналы
- tners
- Подпишитесь на уведомления eTOC
- Пресс-релизы
- СМИ
- Книги издательства Чикагского университета
- Распределительный центр в Чикаго
- Чикагский университет
- Положения и условия
- Заявление о публикационной этике
- Уведомление о конфиденциальности
- Доступность Chicago Journals
- Доступность университета
- Следуйте за нами на facebook
- Следуйте за нами в Twitter
- Свяжитесь с нами
- Медиа и рекламные запросы
- Открытый доступ в Чикаго
- Следуйте за нами на facebook
- Следуйте за нами в Twitter
Ответ на «Установка и интерпретация моделей размещения»
Abstract
В недавней статье Уэлш, Линденмайер и Доннелли (WLD) ставят под сомнение полезность моделей, которые оценивают заселенность видами при учете обнаруживаемости. Представители WLD утверждают, что эти модели трудно подогнать под эти модели, и утверждают, что игнорирование обнаруживаемости может быть лучше, чем попытки приспособиться к ней. Мы думаем, что этот вывод и последующие рекомендации не являются хорошо обоснованными и могут негативно повлиять на качество статистических выводов по экологии и связанных с ними управленческих решений. Здесь мы отвечаем на утверждения WLD, подробно оценивая их аргументы, используя моделирование и / или теорию для подтверждения наших позиций. В частности, WLD утверждают, что игнорирование и учет несовершенного обнаружения приводят к одинаковым характеристикам оценки независимо от размера выборки, когда обнаруживаемость является функцией численности.Мы показываем, что этот ключевой результат их статьи справедлив только для случаев крайней неоднородности, таких как единственный сценарий, который они рассмотрели. Наши результаты иллюстрируют опасность игнорирования несовершенного обнаружения. При игнорировании занятость и обнаружение смешиваются: одни и те же наивные оценки занятости могут быть получены для очень разных истинных уровней занятости, поэтому размер смещения неизвестен.
Представители WLD утверждают, что эти модели трудно подогнать под эти модели, и утверждают, что игнорирование обнаруживаемости может быть лучше, чем попытки приспособиться к ней. Мы думаем, что этот вывод и последующие рекомендации не являются хорошо обоснованными и могут негативно повлиять на качество статистических выводов по экологии и связанных с ними управленческих решений. Здесь мы отвечаем на утверждения WLD, подробно оценивая их аргументы, используя моделирование и / или теорию для подтверждения наших позиций. В частности, WLD утверждают, что игнорирование и учет несовершенного обнаружения приводят к одинаковым характеристикам оценки независимо от размера выборки, когда обнаруживаемость является функцией численности.Мы показываем, что этот ключевой результат их статьи справедлив только для случаев крайней неоднородности, таких как единственный сценарий, который они рассмотрели. Наши результаты иллюстрируют опасность игнорирования несовершенного обнаружения. При игнорировании занятость и обнаружение смешиваются: одни и те же наивные оценки занятости могут быть получены для очень разных истинных уровней занятости, поэтому размер смещения неизвестен. Иерархические модели занятости разделяют занятость и обнаружение, а неточные оценки просто указывают на то, что для надежного вывода о рассматриваемой системе требуется больше данных.Как и в случае любого статистического метода, при нарушении допущений, лежащих в основе простых иерархических моделей, их надежность снижается. Использование в тех случаях, когда иерархические модели занятости не работают хорошо, к наивной оценке занятости не обеспечивает удовлетворительного решения. Вместо этого цель должна заключаться в достижении лучшей оценки за счет сведения к минимуму влияния этих проблем во время проектирования, сбора и анализа данных, обеспечения сбора нужного количества данных и выполнения допущений модели с учетом расширений модели там, где это необходимо.
Иерархические модели занятости разделяют занятость и обнаружение, а неточные оценки просто указывают на то, что для надежного вывода о рассматриваемой системе требуется больше данных.Как и в случае любого статистического метода, при нарушении допущений, лежащих в основе простых иерархических моделей, их надежность снижается. Использование в тех случаях, когда иерархические модели занятости не работают хорошо, к наивной оценке занятости не обеспечивает удовлетворительного решения. Вместо этого цель должна заключаться в достижении лучшей оценки за счет сведения к минимуму влияния этих проблем во время проектирования, сбора и анализа данных, обеспечения сбора нужного количества данных и выполнения допущений модели с учетом расширений модели там, где это необходимо.
Образец цитирования: Guillera-Arroita G, Lahoz-Monfort JJ, MacKenzie D.I, Wintle BA, McCarthy MA (2014) Игнорирование несовершенного обнаружения в биологических исследованиях опасно: ответ на «подгонку и интерпретацию моделей занятости». PLoS ONE 9 (7):
PLoS ONE 9 (7):
e99571.
https://doi.org/10.1371/journal.pone.0099571
Редактор: Итан П. Уайт, Университет штата Юта, Соединенные Штаты Америки
Поступила: 25 октября 2013 г .; Одобрена: 15 мая 2014 г .; Опубликовано: 30 июля 2014 г.
Авторские права: © 2014 Guillera-Arroita et al.Это статья в открытом доступе, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника.
Финансирование: Эта работа была поддержана Центром передового опыта по экологическим решениям Австралийского исследовательского совета (ARC) (www.ceed.edu.au), Центром принятия решений Национальной программы исследований окружающей среды (NERP) (www.nerpdecisions.edu) .au), а также стипендии ARC Future Fellowships для MM и BW. Финансирующие организации не играли никакой роли в дизайне исследования, сборе и анализе данных, принятии решения о публикации или подготовке рукописи.
Финансирующие организации не играли никакой роли в дизайне исследования, сборе и анализе данных, принятии решения о публикации или подготовке рукописи.
Конкурирующие интересы: DM связан с Proteus Wildlife Research Consultants. Нет никаких патентов, продуктов в разработке или продаваемых продуктов, которые можно было бы декларировать. Это не влияет на соблюдение авторами всех политик PLOS ONE в отношении обмена данными и материалами.
Введение
Население видами — это переменная состояния, широко используемая в экологии.Его можно определить как долю участков, на которых присутствуют целевые виды (или с точки зрения лежащей в основе вероятности), и он имеет отношение к программам мониторинга и изучению распределения видов. Доступны модели, которые позволяют его оценивать и одновременно учитывать несовершенное обнаружение, и за последнее десятилетие они стали все чаще использоваться [1] — [4]. Ключом к этим моделям является описание данных как результата двух связанных процессов: процесса состояния (где вид встречается) и процесса обнаружения (как вид обнаруживается в местах, где он присутствует). Учитывая эту структуру, модели этого типа часто называют «моделями пространства состояний» или «иерархическими моделями» [5], терминология, которую мы здесь применяем. Несовершенное обнаружение — широко признанная проблема при экологических исследованиях [6], в том числе при обследовании сидячих видов [7], [8]. Если не учитывать, несовершенное обнаружение может повлиять на оценки занятости и взаимосвязи среды обитания [3], [9] — [11] и лежащих в основе процессов, определяющих динамику занятости [1], [12], [13].
Учитывая эту структуру, модели этого типа часто называют «моделями пространства состояний» или «иерархическими моделями» [5], терминология, которую мы здесь применяем. Несовершенное обнаружение — широко признанная проблема при экологических исследованиях [6], в том числе при обследовании сидячих видов [7], [8]. Если не учитывать, несовершенное обнаружение может повлиять на оценки занятости и взаимосвязи среды обитания [3], [9] — [11] и лежащих в основе процессов, определяющих динамику занятости [1], [12], [13].
В статье в этом журнале [14] Уэлш, Линденмайер и Доннелли (далее WLD) ставят под сомнение полезность иерархических моделей занятости после сообщения результатов моделирования и теоретических расчетов с использованием базовой модели в [2].Хотя оценка производительности таких моделей важна, мы считаем, что WLD не дает репрезентативной оценки ограничений и преимуществ иерархических моделей занятости, и мы отмечаем, что некоторые из их анализов, по-видимому, содержат ошибки, которые имеют значение для некоторых из их утверждений. относительно качества оценщика. В частности, мы считаем, что ключевой вывод WLD о том, что «игнорирование обнаружения может быть лучше, чем попытки приспособиться к нему», неверен и может способствовать плохой практике анализа экологических данных.Здесь мы представляем нашу точку зрения на проблемы, поднятые WLD, и повторно исследуем их результаты.
относительно качества оценщика. В частности, мы считаем, что ключевой вывод WLD о том, что «игнорирование обнаружения может быть лучше, чем попытки приспособиться к нему», неверен и может способствовать плохой практике анализа экологических данных.Здесь мы представляем нашу точку зрения на проблемы, поднятые WLD, и повторно исследуем их результаты.
WLD поддерживает свою критику иерархического моделирования занятости, заявляя, что эти модели приводят к оценкам границ, «множественным решениям» и неточным оценкам занятости и обнаруживаемости, если размер выборки невелик. Хотя мы согласны с тем, что качество оценки ухудшается с уменьшением размера выборки, что верно для любого типа статистической модели, это не оправдывает общих утверждений об отсутствии полезности иерархических моделей занятости.WLD выбрали несколько сценариев, чтобы оправдать свой аргумент о том, что игнорирование обнаруживаемости может быть лучшим подходом, чем ее явное моделирование. Используя более всесторонний анализ, включая дополнительные значения параметров и методы оценки эффективности двух подходов, мы продемонстрируем истинную ценность иерархических моделей занятости и то, как они превосходят оценщики, игнорирующие обнаруживаемость.
Несмотря на предложения WLD об обратном, эффективность одновидовых моделей заселенности за один сезон ранее оценивалась в литературе.Например, представляя модель, [2] оценил модели посредством моделирования; [15] — [20] учитывать точность оценок для решения плана обследования, как оптимально распределить усилия обследования и как определить размер выборки, необходимый для получения значимых результатов; [21] исследует проблемы идентифицируемости, когда обнаруживаемость неоднородна; [22] рассматривает ценность выборки с заменой в исследованиях, основанных на пространственном воспроизведении в пределах участков. Иерархические модели занятости могут привести к оценкам на границе пространства параметров (оценки занятости равны единице), когда размер выборки невелик.WLD находят эти оценки границ удивительными, однако такие оценки уже упоминались в [2], в то время как [17], которые оценивают производительность модели при небольшом размере выборки, выводят условия, выполняемые наборами данных, которые приводят к оценкам границ в рамках постоянной модели. Приведенные выше ссылки демонстрируют, что в литературе есть оценка эффективности этих методов, хотя мы признаем, что дальнейшая работа в этой области может быть полезной.
Приведенные выше ссылки демонстрируют, что в литературе есть оценка эффективности этих методов, хотя мы признаем, что дальнейшая работа в этой области может быть полезной.
Прежде чем перейти к более конкретным комментариям в следующем разделе, мы поясняем, что, вопреки утверждению WLD, [1], как правило, не рекомендуется изучать изменения занятости, а не численности.Они отмечают, что занятость и численность являются альтернативными переменными состояния, выбор которых зависит от обеспечения значимости результатов мониторинга и, следовательно, от целей программы (см. Также [6]). Заполняемость — это уменьшенная версия численности (т.е. вероятность заселения — это вероятность того, что численность больше нуля). Хотя наличие видов иногда может быть достаточно информативным [23], мы согласны с тем, что это не всегда так. Если кто-то действительно хочет оценок численности, то не следует использовать методы оценки занятости.Однако мы отмечаем, что вопросы обнаруживаемости и требование сбора подходящих данных не менее актуальны при оценке численности (например, см.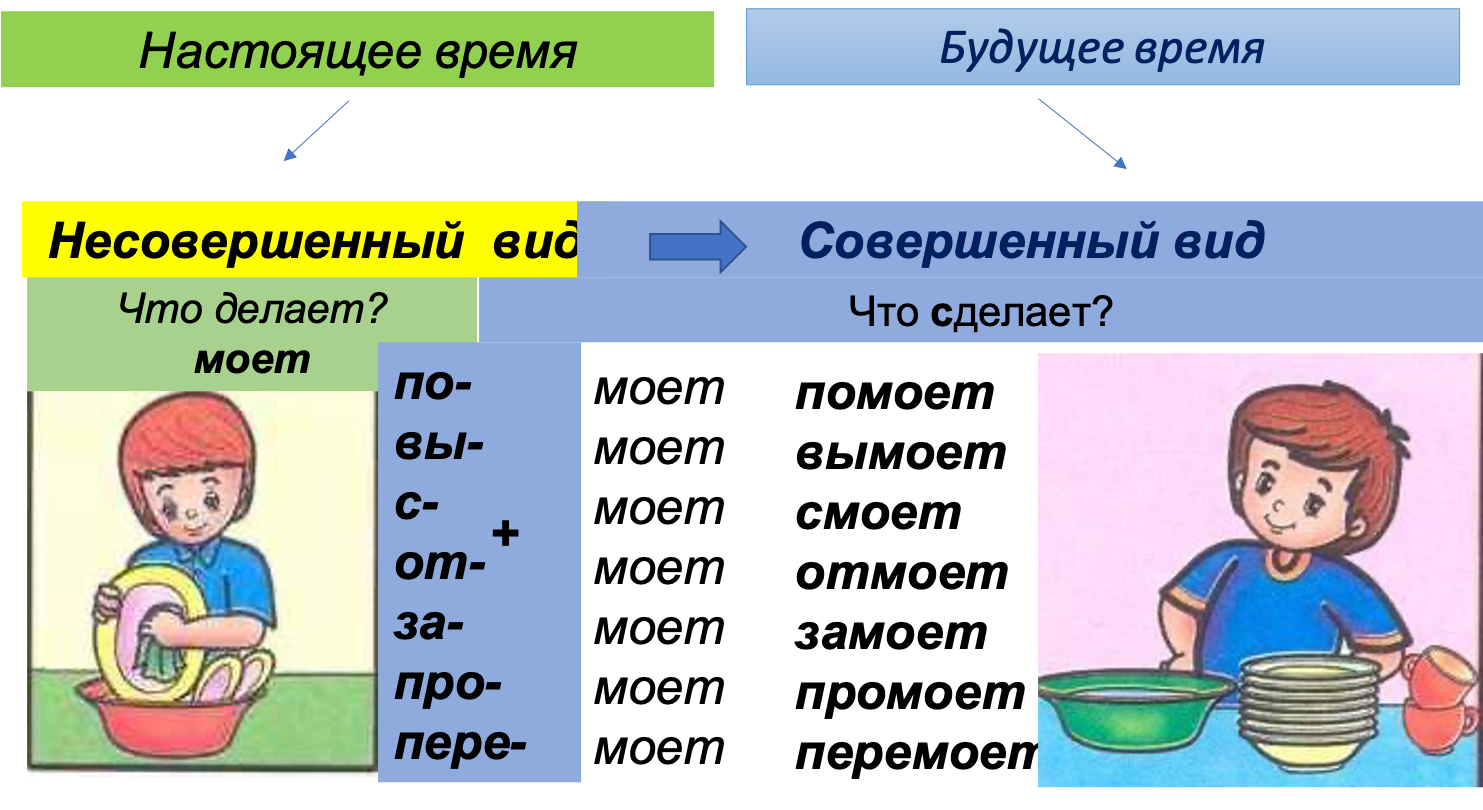 [24] — [26]). Здесь мы не будем вдаваться в обсуждение выбора переменных состояния, что, хотя и интересно, это отдельная тема. В этой статье мы сосредоточимся на рассмотрении критических замечаний по поводу «подбора и интерпретации моделей занятости», высказанных WLD. Следовательно, наша посылка состоит в том, что населенность видами является интересующей переменной состояния.
[24] — [26]). Здесь мы не будем вдаваться в обсуждение выбора переменных состояния, что, хотя и интересно, это отдельная тема. В этой статье мы сосредоточимся на рассмотрении критических замечаний по поводу «подбора и интерпретации моделей занятости», высказанных WLD. Следовательно, наша посылка состоит в том, что населенность видами является интересующей переменной состояния.
Методы
Мы выделяем пять основных моментов, которые подтверждаются результатами моделирования и математическими выводами. Следуя WLD, мы выполнили моделирование для сценария (далее Сценарий A1), где занятость была для всех участков, а вероятность обнаружения была с ковариатой, что соответствует вероятностям обнаружения в диапазоне 0,422–0,638 (в WLD ковариата представляет годы с момента посадки в окружающей среде обитания и целевые виды — лесные птицы). Мы предположили одинаковое количество сайтов для каждого значения ковариаты.Для сравнения мы добавили второй сценарий (далее Сценарий A2) с более высокой занятостью и более низкой обнаруживаемостью: и (т. е. в диапазоне 0,142–0,269). WLD также рассмотрел этот случай (с вероятностью обнаружения, как для A1), но повторный анализ этого сценария не меняет основных моментов, которые мы делаем впоследствии, поэтому мы не рассматриваем этот анализ далее; в этом случае с учетом редких наблюдений модели будут работать плохо, если размер выборки не будет относительно большим [17].
е. в диапазоне 0,142–0,269). WLD также рассмотрел этот случай (с вероятностью обнаружения, как для A1), но повторный анализ этого сценария не меняет основных моментов, которые мы делаем впоследствии, поэтому мы не рассматриваем этот анализ далее; в этом случае с учетом редких наблюдений модели будут работать плохо, если размер выборки не будет относительно большим [17].
Мы смоделировали 5000 наборов данных для каждого сценария и подобрали иерархические модели занятости с пакетом без пометки v0.9–9 [27] в R [28], который получает оценки максимального правдоподобия с помощью численной оптимизации. Unmarked отличается от пакета R VGAM, используемого WLD [29], тем, что он был специально разработан для подгонки иерархических моделей занятости (среди прочих), а не более общего семейства моделей. Следуя WLD, мы подогнали модель к ковариате как в компонентах занятости, так и в компонентах обнаружения, то есть, хотя в более общем плане мы предлагаем рассмотреть некоторую форму метода выбора модели, чтобы определить, какие ковариаты обеспечивают наилучшее описание имеющихся данных. Мы также применили стандартные модели логистической регрессии (т. Е. Модели занятости, предполагающие идеальное обнаружение, далее «модели наивной занятости»), используя функцию R glm . Мы снова допустили, что занятость является функцией ковариаты, т.е. Мы приспособили наивные модели к двум типам наборов данных: сначала учитываем только одно повторное обследование для каждого сайта, затем учитываем те же усилия по выборке, что и в соответствующей иерархической модели, но сворачиваем данные в одну запись об обнаружении / невыявлении для каждого сайта. (я.е. с учетом вида, обнаруженного на участке, если он был обнаружен в ходе любого из исследований). Что касается размера выборки, мы оценили все комбинации из S = 55, 110 или 165 сайтов и K = 2, 3, 4 или 5 повторных опросов на сайт. Обратите внимание, что, несмотря на упоминание четырех случаев размера выборки, WLD сообщает результаты только для самого маленького размера выборки, которую они оценили (например, S = 55 и K = 2).
Мы также применили стандартные модели логистической регрессии (т. Е. Модели занятости, предполагающие идеальное обнаружение, далее «модели наивной занятости»), используя функцию R glm . Мы снова допустили, что занятость является функцией ковариаты, т.е. Мы приспособили наивные модели к двум типам наборов данных: сначала учитываем только одно повторное обследование для каждого сайта, затем учитываем те же усилия по выборке, что и в соответствующей иерархической модели, но сворачиваем данные в одну запись об обнаружении / невыявлении для каждого сайта. (я.е. с учетом вида, обнаруженного на участке, если он был обнаружен в ходе любого из исследований). Что касается размера выборки, мы оценили все комбинации из S = 55, 110 или 165 сайтов и K = 2, 3, 4 или 5 повторных опросов на сайт. Обратите внимание, что, несмотря на упоминание четырех случаев размера выборки, WLD сообщает результаты только для самого маленького размера выборки, которую они оценили (например, S = 55 и K = 2). Следуя WLD, мы рассматривали подобранные значения больше 0,9999 как единицу, а значения меньше 0.0001 как ноль. Мы включаем дополнительный набор моделирования, который исследует все пространство параметров, предполагая постоянную занятость и обнаруживаемость (подробности в Приложении S2).
Следуя WLD, мы рассматривали подобранные значения больше 0,9999 как единицу, а значения меньше 0.0001 как ноль. Мы включаем дополнительный набор моделирования, который исследует все пространство параметров, предполагая постоянную занятость и обнаруживаемость (подробности в Приложении S2).
Следуя WLD, мы выполнили ряд имитаций, в которых обнаруживаемость на каждом участке в пределах ковариатной категории была случайной величиной, а не константой (но подобранная иерархическая модель по-прежнему предполагала, что обнаруживаемость была постоянной в каждой категории, после логистической регрессии, как указано выше, т.е.). WLD представляет это как сценарий, в котором обнаруживаемость является функцией численности, но в более общем плане его можно интерпретировать как любой сценарий, в котором обнаруживаемость неоднородна для разных участков.Мы выполнили этот набор симуляций «изобилия», используя как те же самые, так и разные параметры, что и WLD (подробности приведены в соответствующем разделе ниже; мы будем называть эти симуляции сценариями B1, B2 и B3). См. Таблицу 1 для обзора всех смоделированных сценариев. Чтобы подтвердить наше моделирование, мы дополнительно оценили эти три сценария, решив ожидаемые оценочные уравнения (как в «теоретических результатах» WLD; подробности в Приложении S3). Этот метод предоставляет информацию об асимптотическом смещении оценок, которое мы также подробно исследовали для широкого диапазона сценариев неоднородности (от нулевого до экстремального), предполагая для простоты одну ковариатную категорию.
См. Таблицу 1 для обзора всех смоделированных сценариев. Чтобы подтвердить наше моделирование, мы дополнительно оценили эти три сценария, решив ожидаемые оценочные уравнения (как в «теоретических результатах» WLD; подробности в Приложении S3). Этот метод предоставляет информацию об асимптотическом смещении оценок, которое мы также подробно исследовали для широкого диапазона сценариев неоднородности (от нулевого до экстремального), предполагая для простоты одну ковариатную категорию.
Сообщение 1: Граничные оценки и множественные решения не являются такой большой проблемой, как подразумевается WLD
WLD заявляет, что иерархические модели занятости часто приводят к граничным оценкам (то есть к оценкам, которые принимают значение 0 или 1) и страдают множеством решений. Граничные оценки представляют собой проблему только тогда, когда размер выборки невелик (относительно разреженности данных) и оценки занятости, равные 1, могут быть получены, даже если истинная основная занятость низкая [17]. Когда размер выборки большой, оценки заселенности, равные единице или близкие к ней, все же могут быть получены, но они, вероятно, будут точно соответствовать действительно высокому уровню заселенности видами.Хотя нет сомнений в том, что производительность оценщиков ухудшается по мере уменьшения размера выборки, мы считаем, что заявления WLD относительно граничных оценок и множественных решений завышены по следующим причинам:
Когда размер выборки большой, оценки заселенности, равные единице или близкие к ней, все же могут быть получены, но они, вероятно, будут точно соответствовать действительно высокому уровню заселенности видами.Хотя нет сомнений в том, что производительность оценщиков ухудшается по мере уменьшения размера выборки, мы считаем, что заявления WLD относительно граничных оценок и множественных решений завышены по следующим причинам:
1-1) Оценка загруженности «Все по одному» не является общей проблемой
WLD представляет систему уравнений, которой удовлетворяют оценки максимального правдоподобия (MLEs), и подтверждают их утверждение о том, что оценки границ часто являются проблемой в иерархических моделях занятости, наблюдая, что все занятые сайты (для всех сайтов) всегда являются решением для одно уравнений в системе (уравнение (4) в [14]).Однако важно отметить, что такое решение само по себе не представляет собой стационарную точку в функции правдоподобия (то есть точку, где все частные производные равны нулю, то есть где поверхность является локально плоской). Чтобы точка была стационарной, должны быть выполнены все уравнения в системе. Даже в этом случае решение не обязательно соответствует оценке максимального правдоподобия (и на самом деле может быть гораздо менее вероятным решением).
Чтобы точка была стационарной, должны быть выполнены все уравнения в системе. Даже в этом случае решение не обязательно соответствует оценке максимального правдоподобия (и на самом деле может быть гораздо менее вероятным решением).
Рассмотрим для простоты модель без ковариат.Пусть будет вероятность обнаружения вида хотя бы один раз на занятом участке, общее количество участков, где вид обнаружен, и общее количество обнаружений на всех участках. Система уравнений, которая получается путем дифференцирования логарифма правдоподобия по параметрам и приравнивания к нулю, действительно имеет решение при и. Однако можно показать, что это решение соответствует максимуму вероятности (и, следовательно, является MLE) только , когда выполняется следующее условие [17]: (1) Когда (1) не выполняется, приведенное выше решение имеет вид седловая точка в функции правдоподобия, а не максимум (рисунок 1).Алгоритм оптимизации, используемый для получения оценок, не должен иметь особых проблем с поиском истинного максимума функции, который находится в и, даже если есть другая стационарная точка (подробнее о работе с несколькими решениями в пункте 1-3 ниже).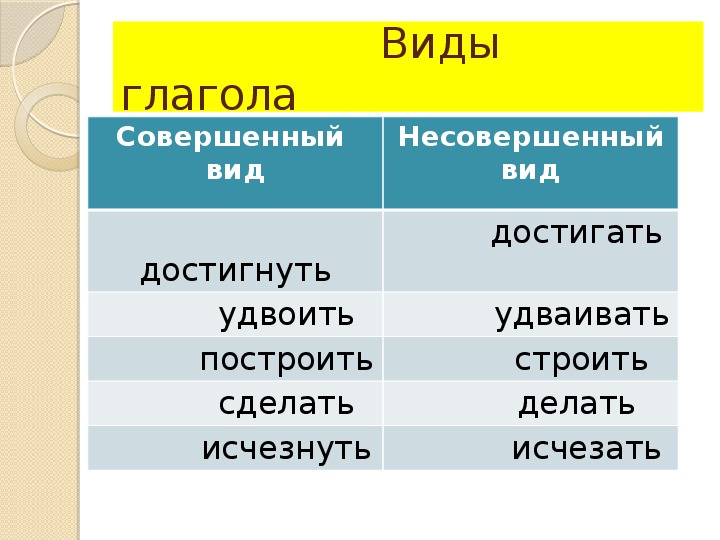 В нашем анализе ни одно из 5000 симуляций не привело к оценке занятости «все один» в сценарии A1, когда S = 55 и K = 2, или для больших размеров выборки (таблица 2b), в то время как WLD обнаружил только 12 случаев. для того же сценария (таблица 2а).
В нашем анализе ни одно из 5000 симуляций не привело к оценке занятости «все один» в сценарии A1, когда S = 55 и K = 2, или для больших размеров выборки (таблица 2b), в то время как WLD обнаружил только 12 случаев. для того же сценария (таблица 2а).
1-2) «Все нулевые» оценки занятости невозможны, если нет обнаружений
Результаты моделирования, представленные WLD для сценария A1, показывают оценки занятости (для всех участков и ) в наборах данных с обнаружениями (120 из 5000 моделирования; Таблица 2a). WLD заявляет, что этот « кажется странным ». Действительно, такие результаты не могут быть оценками максимального правдоподобия и должны быть ошибками. Это можно сразу увидеть, посмотрев на первое из оценочных уравнений (уравнение (4) в [14]), которое равно нулю только тогда, когда (для всех участков и ), если на каком-либо участке нет обнаружений (i .е. для всех сайтов и ). Как и ожидалось, мы не получили таких оценок (таблица 2b). Во всех наших моделях вид был обнаружен на ≥4 участках, и по крайней мере одна из оценок заселенности превышала 0,16; то есть всегда существовала по крайней мере одна оценка, которая была значительно выше нуля. Мы убедились, что очень похожие результаты получены с помощью программы PRESENCE [30]. Результаты, представленные WLD, которые противоречат теории, указывают на проблемы либо с их моделированием данных, либо с пакетом R, который они использовали для подгонки модели (VGAM).Мы считаем, что, скорее всего, это было последнее, учитывая трудности достижения сходимости, которые мы испытали при тестировании пакета VGAM в подмножестве наших симуляций с K = 2.
Во всех наших моделях вид был обнаружен на ≥4 участках, и по крайней мере одна из оценок заселенности превышала 0,16; то есть всегда существовала по крайней мере одна оценка, которая была значительно выше нуля. Мы убедились, что очень похожие результаты получены с помощью программы PRESENCE [30]. Результаты, представленные WLD, которые противоречат теории, указывают на проблемы либо с их моделированием данных, либо с пакетом R, который они использовали для подгонки модели (VGAM).Мы считаем, что, скорее всего, это было последнее, учитывая трудности достижения сходимости, которые мы испытали при тестировании пакета VGAM в подмножестве наших симуляций с K = 2.
1-3) Сложность работы с несколькими решениями преувеличена
WLD утверждают, что получение множественных решений для системы уравнений правдоподобия является проблемой в иерархических моделях занятости. Чтобы оценить степень, в которой несколько решений действительно являются проблемой для подгонки модели, мы повторно провели моделирование сценария 1 для меньшего размера выборки ( S = 55 и K = 2), подогнав каждый набор данных несколько раз (по 20 каждый). ) с разными случайно выбранными начальными значениями и изучили оценки, полученные с каждым из них.
В 98,5% симуляций без пометки были найдены оценки максимального правдоподобия с первой попытки с использованием значений по умолчанию. Обратите внимание, что WLD также признают, что их процедура подгонки обычно возвращала MLE с настройками по умолчанию. Это подтверждает, что трудности работы с несколькими решениями не так велики, как говорится в некоторых заявлениях, сделанных WLD.
Алгоритм оптимизации, используемый немаркированным, имел тенденцию последовательно находить MLE (98,7% попыток) до тех пор, пока исходные значения, указанные для коэффициентов регрессии, оставались в пределах разумных значений (например,грамм. выбирая значения в [−0,5,0,5]). Алгоритм оптимизации был более склонен останавливаться на оценке, которая была на границе (т. Е. По крайней мере с одним значением) и которая не была MLE (т. Е. Имела меньшую вероятность), только когда мы допускали большие начальные значения для коэффициентов регрессии (например, выбирая значения в [−3,3]). Следовательно, чтобы уменьшить вероятность завершения в точке, отличной от MLE, следует избегать использования экстремальных начальных значений, которые могут привести к запуску алгоритма оптимизации (и застреванию) на границе.В любом случае всегда рекомендуется подбирать модель с несколькими начальными значениями, чтобы обеспечить обнаружение MLE (а не локального максимума). Использование нескольких начальных значений является хорошей практикой, которая не является уникальной для иерархических моделей занятости, а должна регулярно рассматриваться при оценке параметров числовыми методами максимального правдоподобия.
Сообщение 2: игнорируя несовершенное обнаружение, оценивается другая метрика. Этот показатель может быть получен из иерархической модели
. Если не принимать во внимание несовершенное обнаружение, оцениваемый показатель больше не является присутствием видов ().Присутствие и обнаружение смешиваются, поэтому модель вместо оценивает продукт , где — вероятность обнаружения вида на участке, где он присутствует, с учетом общих усилий по съемке. Вместо того, чтобы оценивать, где вид с большей или меньшей вероятностью может встретиться, модель оценивает, где вид с большей или меньшей вероятностью будет обнаружен (с учетом применяемых методов и усилий). Это проблема идентифицируемости параметров, когда модель не может разделить процесс состояния и процесс наблюдения, а также может быть интерпретирована как ситуация, когда оценка присутствия видов смещена на неизвестную величину.Стоит отметить, что иерархическая модель занятости также может оценивать этот показатель () на основе оценок занятости и обнаружения с. На рисунках 2 и 3 показано, как оценки, полученные для этой величины с помощью иерархической модели занятости (третий столбец), по существу совпадают с оценками, полученными при подборе наивной модели (четвертый столбец).
Рис. 2. Результаты моделирования подгонки иерархических и простых моделей занятости к 5000 наборам данных из сценария A1 с 55 объектами.
Первые три столбца соответствуют иерархической модели: в столбце 1 оценки вероятности занятости («пси-шляпа»), в столбце 2 оценки условной вероятности обнаружения при однократном обследовании («п-шляпа») и в столбце 3. оценки безусловной вероятности обнаружения после K опросов (‘pdet-hat’). В столбце 4 представлены оценки наивной модели, предполагающей идеальное обнаружение. Строки представляют возрастающее количество повторных опросов на сайт, от K = 1 до K = 5.В тех случаях, когда наивная модель была приспособлена к данным, свёрнутые до одной записи для каждого участка (1, если вид был обнаружен хотя бы один раз, 0 в противном случае). В этом конкретном сценарии (также представленном в [14]) неточность иерархической модели велика по сравнению с систематической ошибкой в наивной модели. Истинная занятость составляла 0,4, а истинная вероятность обнаружения увеличивалась с увеличением значения переменной x. На каждом рисунке сплошная линия представляет истинные значения. Для справки, в столбцах 3 и 4 пунктирная линия представляет истинную вероятность занятости.
https://doi.org/10.1371/journal.pone.0099571.g002
Рис. 3. Результаты моделирования подгонки иерархических и простых моделей занятости к 5000 наборам данных из сценария A2 с 55 сайтами.
Подробные сведения о расположении рисунка см. На рисунке 2; здесь истинная заполняемость составила 0,8. В этом примере иерархическая модель явно превосходит наивную модель, которая сильно предвзята. Сравнение оценок для K = 2 с оценками на Рисунке 2 показывает, как наивная модель может давать одинаковые оценки для очень разных сценариев.
https://doi.org/10.1371/journal.pone.0099571.g003
Сообщение 3: Учет несовершенного обнаружения обеспечивает более надежную оценку занятости, которая честно отражает неопределенность
При интерпретации как оценка занятости видов наивная модель смещается, когда общее обнаружение несовершенно (т. Е. См. Столбец 4 на рисунках) 2 и 3, а также рисунки S1.1 – S1.6 в Приложении S1) [2], [3], [9], [10]. Вместо этого иерархическая модель занятости обеспечивает асимптотически несмещенную оценку занятости, когда выполняются предположения модели (столбец 1 на тех же рисунках).Однако его оценка менее точна. Это ожидается с учетом того, что существует дополнительный источник неопределенности, если допущено несовершенное обнаружение [1], [15]. Следовательно, для небольших размеров выборки и в зависимости от сценария иерархическая модель занятости может привести к оценке со среднеквадратичной ошибкой (MSE), которая больше, чем в простой оценке (см. Таблицу S2.1 в Приложении S2). Однако, как мы покажем ниже, по данным нельзя сказать, находится ли он в таком сценарии или в том, где игнорирование обнаруживаемости подразумевает большую систематическую ошибку (и, следовательно, MSE).
По мере увеличения количества участков съемки S производительность иерархической модели улучшается, поскольку ее оценка становится более точной. Наивная модель также становится более точной, но, поскольку она остается предвзятой, ее производительность существенно не улучшается, если только смещение не является небольшим. Наивная модель обеспечивает непоследовательную оценку, т. Е. Ее MSE не стремится к нулю при увеличении размера выборки S . Таким образом, превосходство иерархической модели с точки зрения MSE становится более очевидным по мере увеличения S (см. Таблицу S2.1 и отношения MSE в таблице 3). В наивной модели увеличение количества обследуемых участков на самом деле может быть вредным: доверительный интервал сужается вокруг неверной оценки (поскольку оценка смещена). Помимо небольшой MSE, желательным свойством оценщиков является предоставление доверительных интервалов с хорошим охватом, то есть доверительных интервалов, которые, как правило, содержат истинное значение параметра (например, 95% времени при работе с 95% доверительными интервалами). Из-за того, что наивная оценка смещена, ее охват может быть очень плохим (см. Таблицу S2.2 в Приложении S2). Следовательно, наивная модель может дать неверно точные оценки, далекие от истинного значения занятости.
WLD представляет Сценарий A1 ( S, = 55 и K = 2), в котором отсутствует необходимость в моделировании обнаруживаемости, поскольку смещение, вызванное предположением о совершенном обнаружении, относительно мало по сравнению с уменьшенной точностью в иерархической модели. В самом деле, этот конкретный сценарий — тот, где MSE для оценки наивной модели меньше (Таблица 3a).Однако крайне важно помнить, что наивная модель может предоставить оценки, идентичные оценкам, полученным в сценарии A1 для других сценариев занятости, которые подразумевают гораздо большую систематическую ошибку, когда иерархическая модель явно превосходит наивную модель. Например, оценки, полученные при подгонке наивной модели к сценарию A1, по существу такие же, как и оценки, полученные в сценарии A2, когда K = 2 (сравните соответствующие графики на рисунках 2 и 3; также рисунки S1.2 – S1.3 с рисунками S1.5–1,6 в Приложении S1 для большего размера выборки), но в последнем случае истинная вероятность занятости составляет 0,8, и, следовательно, наивная оценка существенно смещена и имеет гораздо большую MSE (Таблица 3b). Рассматривая только наивные оценки занятости, мы не можем сказать, насколько хороши или плохи эти оценки, поскольку процессы занятости и обнаружения смешаны (например, если наивная занятость составляет 0,24, это потому, что и или и?). Только тогда, когда мы разделим эти процессы, мы сможем понять, является ли несовершенное обнаружение проблемой или нет, и мы можем быть уверены, что надежно оцениваем заселенность видами.Наивная модель оценки имеет плохой охват, когда обнаружение несовершенно, то есть доверительные интервалы вокруг оценок вряд ли включают истинное значение занятости. Мы утверждаем, что лучше открыто выражать неуверенность, чем сообщать о результате, который может быть точным, но ошибочным. Следовательно, мы считаем, что иерархическая модель обеспечивает более подходящую оценку.
Сообщение 4: Учет несовершенного обнаружения не подразумевает необходимости увеличения усилий по отбору проб. Неидеальное обнаружение
Учет несовершенного обнаружения не обязательно требует дополнительных усилий по обследованию.Однако необходимо собирать данные обследования таким образом, чтобы можно было моделировать процесс обнаружения [10]. Это может быть сделано, например, путем записи наблюдений, собранных во время нескольких посещений (как здесь предполагается), обнаружений нескольких независимых наблюдателей [1] или времени обнаружения в течение одного посещения [7], [31]. Другое дело, что для данного уровня усилий по отбору проб на каждом участке требуется больше участков для отбора проб, чтобы получить хорошие оценки занятости, когда обнаруживаемость низкая. Проще говоря: плохая обнаруживаемость затрудняет распутывание процессов присутствия и обнаружения.С другой стороны, увеличение объема исследований на каждом участке (например, количества повторных посещений на каждый участок) снижает проблему несовершенного обнаружения, поскольку вероятность пропуска видов на занятых участках уменьшается. При заданном бюджете обследования существует компромисс между посещением большего количества сайтов и затратами большего количества усилий на обследование на каждый сайт [15] — [20], при этом оптимальное распределение усилий соответствует относительно высокому уровню общего обнаружения (около 0,85–0,95). .
WLD представляет трудность в необходимости «дополнительного сбора данных […] для корректировки на необнаружение».Однако непоследовательно, при подгонке наивной логистической модели в своих симуляциях, WLD использует данные, соответствующие полному усилию выборки (свертывая повторяющиеся записи, как это делаем мы). Если WLD решит связать дополнительные повторные исследования как осложнение, вызванное моделированием обнаруживаемости, то справедливое сравнение позволило бы подогнать наивную модель к данным из одного повторного исследования для каждого участка. Мы включаем эти результаты (обозначенные « K = 1») в качестве первой строки в таблице 3 и в результаты нашего моделирования (рисунки 2 и 3 и рисунки в приложении S1), чтобы проиллюстрировать увеличивающийся разрыв в производительности между наивными и иерархическими. модели, когда этот подход применяется к наивной модели.Если вместо этого модели сравниваются с данными, полученными в результате того же усилия по выборке (как это делает WLD), то объем усилий по выборке не следует использовать в качестве аргумента против использования иерархических моделей.
Сообщение 5: Иерархические модели менее предвзяты, чем наивные модели, даже если обнаружение является функцией численности
Заявленный ключевой результат WLD состоит в том, что «когда процесс обнаружения зависит от численности, систематическая ошибка в подобранных вероятностях может иметь такую же величину, что и предвзятость, когда процесс обнаружения игнорируется, и это очень трудно преодолеть ».Они также отмечают, что увеличение размера выборки ( S или K ) не решает проблему, а вместо этого ухудшает оценки. Доказательства для их вывода прибывают из рассмотрения единственного сценария с использованием моделирования и теоретических результатов. Однако, как мы видели выше, иерархическая модель занятости ведет себя лучше, чем наивная модель в сценариях, где обнаруживаемость варьируется, и это также можно интерпретировать как случаи, в которых обнаруживаемость зависит от численности.Итак, в чем причина этого несоответствия? И как мы можем объяснить противоречивый результат, заключающийся в том, что увеличение размера выборки ухудшает положение?
При внимательном рассмотрении сценария, смоделированного WLD (далее Сценарий B1), выявляется корень этого противоречия. Как и в предыдущем примере, заполняемость была установлена постоянной для всех участков (для всех участков и ), а обнаруживаемость варьировалась для каждой ковариатной категории, но здесь значения обнаруживаемости были сгенерированы как случайные переменные из разных распределений для каждой ковариатной категории, что привело к изменению вероятность обнаружения среди сайтов (что делает их разными).В качестве примера компания WLD выбрала следующие распределения. Эти распределения (рис. 4 a, b) представляют собой случай, когда обнаруживаемость относительно высока для двух последних ковариатных категорий (90% массы в [0,636–0,967]; среднее значение 0,833 для) и может принимать любое значение для ковариат трех других категорий, хотя с большей вероятностью оно будет ниже для ([0,002–0,902]; среднее значение 0,333), чем для ([0,050–0,950]; среднее значение 0,5). Важно отметить, что для большей части вероятности масса очень близка к нулю (> 22% «занятых» сайтов имеют вероятность обнаружения <0.05: Рисунок 4a), хотя есть также значительная вероятность того, что вероятность обнаружения высока (т.е. примерно 22% распределения> 0,61). Распределение вероятности по крайней мере одного обнаружения из двух съемок () имеет форму «ванны» с пиками около 0 и 1 (рис. 4c). Это довольно экстремальное распространение означает, что на некоторых населенных пунктах вид практически не виден для методов исследования, а на других его обнаружение почти гарантировано. При применении модели, не допускающей такой неоднородности, занятые участки с низкой вероятностью обнаружения с большей вероятностью будут рассматриваться как незанятые, если вид останется незамеченным, особенно при проведении только двух съемок и если другие участки имеют очень высокую вероятность обнаружения.Это вызывает отрицательное смещение, наблюдаемое WLD при оценке занятости для этих двух ковариатных категорий, и, следовательно, положительное смещение в оценке наклона регрессии занятости. Нельзя ожидать, что модель, не предполагающая неоднородности, обеспечит надежный вывод о виде перед лицом такой крайней неоднородности, даже если размер выборки велик. Это связано с тем, почему WLD ошибочно приходит к выводу, что увеличение размера выборки ( S или K ) не улучшает производительность иерархической модели.WLD отмечает, что для этого конкретного примера оценки наклона «немного ухудшаются», когда увеличивается K , и «намного хуже», когда увеличивается S , за счет соотнесения качества оценки с долей моделирования, которое приводит к не- положительный расчетный наклон. В самом деле, поскольку в этих симуляциях на производительность преобладает систематическая ошибка, вызванная чрезвычайно низкой обнаруживаемостью на некоторых участках, повышение точности из-за увеличения количества данных может привести к большей доле симуляций с положительными наклонами.Однако WLD упускает из виду, что само смещение также уменьшается (хотя и медленно), и, следовательно, качество оценки (измеряемое в единицах MSE) действительно улучшается (Таблица 4). Качество оценки улучшается с K , что интуитивно понятно, поскольку модель в конечном итоге несмещена, когда K достаточно велико, чтобы вид обнаруживался на всех участках, где они есть (если p не равно 0). Качество оценщика также улучшается с S , хотя некоторая погрешность сохраняется даже для больших S , учитывая, что мы подбираем другую структуру обнаружения, чем та, которая используется для генерации данных.Наши результаты также показывают, что даже в этом сценарии иерархическая модель превосходит наивную модель с точки зрения MSE (таблица 4). Улучшение невелико, поскольку в сценарии преобладает тот факт, что вид практически не обнаруживается в значительной части участков более низкой ковариатной категории. Как мы покажем ниже, неудивительно, что WLD обнаружила, что смещения были очень похожи как в иерархической, так и в наивной модели, учитывая крайние колебания обнаруживаемости в оцениваемом сценарии, что, по нашему мнению, представляет собой необычный случай.
Таблица 4. Среднеквадратичная ошибка (MSE) для оценки занятости в иерархических / наивных моделях и их соотношение, полученное в результате моделирования трех сценариев «изобилия»: (a) сценарий B1 из [14], (b) сценарий B2 и (c) Сценарий B3.
https://doi.org/10.1371/journal.pone.0099571.t004
Итак, что произойдет, если мы рассмотрим другой и правдоподобный сценарий? Давайте рассмотрим пример, в котором эти распределения имеют то же среднее значение для каждой ковариантной категории, что и в предыдущем сценарии (0.333, 0,5 и 0,833 соответственно) и, хотя и значительны, имеют менее экстремальные уровни неоднородности (рис. 4 b, d). Моделирование с этими распределениями обнаруживаемости и вероятностью занятости (сценарий B2) или (сценарий B3) показывает, что иерархическая модель явно превосходит простую модель в этих примерах (таблица 4), даже с учетом того, что линейная модель, подходящая для компонента обнаружения, неверно указана относительно что фактически использовалось для генерации данных. Хотя в иерархической модели присутствует некоторая остаточная систематическая ошибка (вызванная небольшим размером выборки и тем фактом, что модель асимптотически смещена из-за неправильного определения компонента обнаружения), систематическая ошибка заметно снижается (Рисунок 5; см. Другие рисунки в Приложении S1. ).Наивная модель по-прежнему существенно предвзята из-за незнания несовершенного обнаружения. Наши результаты моделирования подтверждаются нашей теоретической оценкой (Приложение S3). WLD ограничили свои теоретические результаты одним сценарием (сценарий B1), но наша расширенная оценка показывает, что асимптотическое смещение действительно может быть значительно больше в простой модели, чем в иерархической модели, даже когда обнаруживаемость неоднородна (таблица S3.1 и рисунок S3. .1).
Рис. 5. Результаты моделирования подгонки иерархических и простых моделей занятости к 5000 наборам данных из сценария B2 со 165 объектами.
Подробную информацию о расположении рисунков см. На рисунке 2. Этот пример показывает, что даже если обнаруживаемость неоднородна, иерархическая модель имеет меньшее смещение и что это смещение уменьшается с увеличением размера выборки.
https://doi.org/10.1371/journal.pone.0099571.g005
Те же выводы можно сделать из нашего детального исследования широкого диапазона сценариев неоднородности (от нулевого до крайнего), предполагая одну ковариатную категорию (рисунок 6). Мы вывели соответствующие аналитические выражения для относительной асимптотической погрешности оценки занятости в наивной и иерархической моделях, которые (2) со шляпками (∧) обозначают оценки.Мы наблюдаем, что при крайней неоднородности (т.е. переключение обнаруживаемости только между значениями 0 или 1) асимптотическое смещение для обеих моделей составляет. По мере уменьшения неоднородности смещение наивной модели уменьшается, но остается неизменным в отсутствие неоднородности. Смещение иерархической модели уменьшается быстрее, достигая нуля для случая без неоднородности и может быть значительно ниже, чем смещение в наивной модели для реалистичных сценариев неоднородности. Выражение смещения в (2) показывает, что, как и ожидалось, величина смещения в иерархической модели зависит от того, насколько хорошо воспринимаемая обнаруживаемость отражает фактическую вероятность обнаружения / пропуска видов на занятых участках.
Рис. 6. Асимптотическое смещение наивных и иерархических оценок занятости как функция неоднородности обнаруживаемости.
В модели генерации данных занятость постоянна, и обнаруживаемость на каждом сайте определяется из одного распределения. В подобранной модели и занятость, и обнаруживаемость предполагаются постоянными на разных участках (т.е. неоднородность не моделируется). Неоднородность выражена по оси абсцисс как коэффициент вариации распределения (CV). Черные толстые линии представляют иерархическую модель, а красные тонкие линии — наивную модель (сплошные линии для K = 2 и пунктирные линии для K = 5; горизонтальные серые линии соответствуют наивной модели, где K = 1).В условиях крайней неоднородности (высокое значение CV, при котором обнаруживаемость переключается между 0 и 1) обе модели приводят к одинаковому смещению. Для более реалистичных сценариев, где неоднородность все еще значительна, иерархическая модель имеет меньшее асимптотическое смещение. Иерархическая модель асимптотически несмещена при отсутствии неоднородности (т. Е. CV = 0). Графики в нижнем ряду (A – C) иллюстрируют неоднородность выявляемости, представленную тремя разными CV, когда средняя выявляемость составляет 0,33. Обратите внимание, что относительное асимптотическое смещение не зависит от вероятности занятости.
https://doi.org/10.1371/journal.pone.0099571.g006
Таким образом, основываясь на наших моделированиях и теоретических результатах, мы можем сделать вывод, что иерархическая модель также менее смещена, чем наивная модель, когда обнаруживаемость варьируется в зависимости от сайтов. , например, в результате изменения численности. Отметим также, что существуют расширения иерархической модели занятости, которые явно допускают неоднородные вероятности обнаружения [21], [32]. Это следует учитывать, когда моделирование вариации вероятности обнаружения как функции переменных окружающей среды невозможно, и вероятно, что одно из предположений базовой модели было нарушено.
Обсуждение
WLD представляют чрезмерно негативную картину работы иерархических моделей занятости, ставя под сомнение их ценность до такой степени, что предполагают, что в целом «игнорирование необнаружения может быть лучше, чем попытки приспособиться к нему». Игнорирование обнаруживаемости подразумевает моделирование «где вид обнаружен» , а не «где встречается вид » , количество, которое также может быть получено из оценок иерархической модели. WLD неявно предлагает прибегнуть к этой альтернативной метрике, но мы ожидаем, что сосредоточение внимания на метрике, которая представляет собой сочетание биологических процессов и процессов отбора проб, не будет удовлетворительным для большинства приложений.Например, [10] иллюстрируют, как игнорирование несовершенного обнаружения может существенно повлиять на определение оптимальной среды обитания для вида и, следовательно, привести к неправильной расстановке пространственных приоритетов на основе этих результатов. Когда целью является оценка вероятностей занятости, игнорирование обнаруживаемости является проблемой, даже если она постоянна. Игнорирование несовершенного обнаружения становится еще более проблематичным, когда обнаруживаемость является функцией ковариат, поскольку тогда тенденции занятости (пространственные или временные) также могут быть смещенными. Если вы хотите достоверно сделать вывод, где вид соответствует (вместо того, где, вероятно, будет наблюдаться ), тогда во время разработки, сбора и анализа данных должны быть предприняты необходимые шаги для минимизации воздействия процесса отбора проб (e .g., обнаруживаемость).
WLD заявляют, что «дополнительные усилия по сбору данных и моделированию с целью корректировки на отсутствие обнаружения просто не имеют смысла». Однако моделирование обнаруживаемости не так сложно, как думают читатели WLD. Необязательно требуется больше усилий по отбору проб; вместо этого данные нужно просто собирать и записывать таким образом, чтобы они были информативными о процессе обнаружения [10]. Кроме того, анализу способствует ряд свободно доступных программных инструментов, разработанных для подбора, сравнения и прогнозирования иерархической модели занятости [27], [30], [33], [34].Как и в WLD, мы использовали максимальную вероятность для вывода, но обратите внимание, что иерархические модели занятости также могут быть легко приспособлены к байесовской структуре с использованием бесплатных инструментов, таких как WinBUGs / OpenBUGS [35] или JAGS [36]; примеры кода см. в [37]. Учитывая WLD и наши трудности с получением надежных оценок параметров с помощью VGAM, мы предварительно предостерегаем от его использования для этих приложений, особенно при небольшом количестве повторных опросов.
WLD частично поддерживает их аргумент, указывая на то, что иерархические модели занятости могут давать оценки, которые неточны или находятся на границе пространства параметров, и что у них могут быть проблемы с несколькими решениями, когда размер выборки невелик.Мы показали, почему мы считаем, что WLD переоценили серьезность этих проблем. Бесспорно, что, как и в случае с любым типом статистической модели, эффективность оценщика будет ухудшаться по мере уменьшения размера выборки, но само по себе это не оправдывает отказ от метода (это предполагает отказ от всех статистических выводов). Размеры выборки могут быть слишком малы, чтобы сделать точный вывод о заселенности видами, но игнорирование обнаруживаемости не решает эту ситуацию.
Мы считаем, что учет возможности обнаружения важен, поскольку в противном случае невозможно узнать, точны ли оценки «занятости» (даже если они точны).В наивной модели процессы присутствия и обнаружения смешаны. Можно найти примеры, в которых игнорирование обнаруживаемости приводит к оценкам с лучшими свойствами (с точки зрения MSE), но, поскольку одни и те же данные могут быть получены с помощью очень разных сценариев обнаружения занятости, как показано в нашем моделировании, мы никогда не можем быть уверены, что наивные оценки отражают истинную занятость, если не известно, что обнаружение является идеальным.
Напротив, иерархическая модель занятости разделяет процессы присутствия и обнаружения.Если общее обнаружение почти идеальное (то есть на занятых участках вероятность хотя бы одного обнаружения для повторных съемок K ,, практически равна 1), это разделение не является вредным: мы просто получим те же оценки, что и в простой модели. . Преимущество приходит, когда общее обнаружение несовершенно; тогда оценки заполняемости и наивной занятости различаются. WLD обеспокоены тем фактом, что оценки занятости могут быть неточными. Однако эту неточность не следует интерпретировать как сбой модели, а скорее как проблему недостатка данных; он честно представляет неопределенность.Модель показывает, что существуют альтернативные способы объяснения наблюдаемых обнаружений, которые связаны с очень разными вероятностями занятости. Это говорит нам все, что можно достоверно сказать о заселенности видов по имеющимся данным. Принципиально важно реалистично оценивать неопределенность оценок, особенно в тех случаях, когда оценки должны использоваться в любой форме принятия решений. Если оценки слишком неопределенны, можно сделать вывод о том, что может потребоваться больше данных, чтобы сделать надежный вывод о рассматриваемой системе, а не обращаться к (наивным) оценкам, которые могут быть произвольно предвзятыми.
Ключевой результат
WLD заключается в том, что иерархические модели занятости не работают лучше, чем наивные модели, когда обнаруживаемость зависит от численности, независимо от количества данных обследования, и что это «подрывает обоснование для моделирования занятости». Мы показали, что их результат является результатом конкретного выбора и ограниченной интерпретации конкретного сценария, который включает занятые участки, в которых вид практически не обнаруживается, в то время как обнаруживаемость относительно велика для других участков.Мы продемонстрировали, как иерархическая модель явно превосходит наивную модель в других сценариях, где неоднородность все еще существенна. Мы также показываем, как эта разница в производительности становится более очевидной при увеличении количества сайтов, даже если сохраняется некоторая предвзятость при большом количестве сайтов. Как уже указывалось в [21], базовая иерархическая модель асимптотически смещена, когда имеется неучтенная неоднородность в обнаружении. Однако тот факт, что нарушение модельного предположения (отсутствие неоднородности в p ) может вызвать систематическую ошибку, не оправдывает нарушения дополнительного предположения (точное обнаружение).Вместо этого целью должно быть достижение лучшей оценки, минимизация влияния этих проблем во время проектирования, сбора и анализа данных, например, путем рассмотрения расширений модели, которые явно учитывают гетерогенные вероятности обнаружения [21], [32]. Этот вопрос связан с проблемой идентифицируемости в смешанных моделях для неоднородной обнаруживаемости, поднятой [38] в контексте методов оценки численности улова / повторной поимки, и которая [21] пересматривается для моделей занятости. Альтернативные структуры обнаружения могут одинаково хорошо соответствовать данным, обеспечивая при этом разные оценки численности или занятости.Однако эта проблема значительно уменьшается, когда масса распределения, описывающая обнаруживаемость, удалена от нуля [21]. Это говорит о том, что для надежного вывода наши методы выборки должны обеспечивать немалые шансы обнаружения при наличии вида [1], [39].
В заключение, хотя мы полностью согласны с WLD в отношении необходимости быть честными в отношении ограничений статистических процедур, мы не разделяем их мнение о том, что учет обнаруживаемости «очень сложен» в целом и что лучше не принимать во внимание тот факт, что обнаружение может быть и обычно будет несовершенным.Сложность не столько в моделировании обнаруживаемости, сколько в самом несовершенном обнаружении. Мы не утверждаем, что этап моделирования простой. Действительно, создание полезных моделей для реальных данных может быть очень сложной задачей. Бывают случаи, когда значимые оценки параметров не могут быть получены с доступными данными независимо от статистических навыков. К сожалению, как бы этого ни хотелось, наивные оценки не решают эту проблему.
Благодарности
Авторы благодарят Байрона Моргана, Мартина Риду и Марка Кери за полезные комментарии.
Вклад авторов
Задумал и спроектировал эксперименты: GGA JJLM DM. Проанализированы данные: GGA JJLM. Написал статью: GGA JJLM DM BW MM. Интерпретированные результаты: GGA JJLM DM BW MM.
Список литературы
- 1.
Маккензи Д.И., Николс Д.Д., Ройл Дж.А., Поллок К.Х., Бейли Л.Л. и др. (2006) Оценка и моделирование заселенности: определение закономерностей и динамики встречаемости видов. Нью-Йорк: Academic Press. - 2.
Маккензи Д.И., Николс Д.Д., Лахман Г.Б., Дроеж С., Ройл Дж. А. и др.(2002) Оценка степени занятости сайта, когда вероятность обнаружения меньше единицы. Экология 83: 2248–2255. - 3.
Tire AJ, Tenhumberg B, Field SA, Niejalke D, Parris K и др. (2003) Повышение точности и снижение систематической ошибки в биологических исследованиях: оценка количества ложноотрицательных ошибок. Ecol Appl 13: 1790–1801. - 4.
Бейли Л.Л., Маккензи Д.И., Николс Д.Д. (в печати) Достижения и применения моделей занятости. Методы Ecol Evol doi: 10.1111 / 2041-210X.12100. - 5.
Ройл Дж. А., Дорацио Р. М. (2008) Иерархическое моделирование и вывод в экологии. Амстердам: Academic Press. - 6.
Йоккос Н.Г., Николс Дж. Д., Булинье Т. (2001) Мониторинг биологического разнообразия в пространстве и времени. Тенденции Ecol Evol 16: 446–453. - 7.
Garrard GE, Bekessy SA, McCarthy MA, Wintle BA (2008) Когда мы достаточно внимательно присмотрелись? Новый метод установки протоколов минимальных усилий для обследований флоры. Austral Ecol 33: 986–998. - 8.
Чен Г., Кери М., Платтнер М., Ма К., Гарднер Б. (2013) Несовершенство обнаружения — это скорее правило, чем исключение в исследованиях распространения растений. J Ecol 101: 183–191. - 9.
Gu W, Swihart RH (2004) Отсутствуют или необнаружены? Влияние необнаружения встречаемости видов на модели диких животных и местообитаний. Биол Консерв 116: 195–203. - 10.
Lahoz-Monfort JJ, Guillera-Arroita G, Wintle BA (2014) Несовершенное обнаружение влияет на эффективность моделей распределения видов.Глоб Экол Биогеогр 23: 504–515. - 11.
Кери М. (2011) К моделированию истинного распределения видов. Журнал Биогеогр 38: 617–618. - 12.
Kéry M, Guillera-Arroita G, Lahoz-Monfort JJ (2013) Анализ и картирование динамики ареала видов с использованием моделей занятости. Журнал Биогеогр 40: 1463–1474. - 13.
Мойланен А. (2002) Влияние качества эмпирических данных на оценку и применение параметров модели метапопуляции. Ойкос 96: 516–530. - 14.Валлийский А.Х., Линденмайер Д.Б., Доннелли К.Ф. (2013) Подгонка и интерпретация моделей занятости. PLoS ONE 8: e52015.
- 15.
Маккензи Д.И., Ройл Дж. А. (2005) Разработка исследований занятости: общие рекомендации и распределение усилий по обследованию. J Appl Ecol 42: 1105–1114. - 16.
Бейли Л.Л., Хайнс Дж. Э., Николс Дж. Д., Маккензи Д. И. (2007) Компромиссы проектирования выборки в исследованиях занятости с несовершенным обнаружением: примеры и программное обеспечение. Ecol Appl 17: 281–290. - 17.Guillera-Arroita G, Ridout MS, Morgan BJT (2010) Дизайн исследований занятости с несовершенным обнаружением. Методы Ecol Evol 1: 131–139.
- 18.
Guillera-Arroita G, Lahoz-Monfort JJ (2012) Разработка исследований для выявления различий в обитаемости видов: анализ мощности при несовершенном обнаружении. Методы Ecol Evol 3: 860–869. - 19.
Винтл Б.А., Маккарти М.А., Пэррис К.М., Бургман М.А. (2004) Точность и систематическая ошибка методов оценки вероятностей обнаружения точечной съемки.Ecol Appl 14: 703–712. - 20.
Guillera-Arroita G, Ridout MS, Morgan BJT (2014) Двухэтапный байесовский план исследования для оценки занятости видов. J Agric Biol Envir Stat 19: 278–291. - 21.
Ройл Дж. А. (2006) Модели занятости площадок с неоднородными вероятностями обнаружения. Биометрия 62: 97–102. - 22.
Guillera-Arroita G (2011) Влияние выборки с заменой в исследованиях занятости с пространственным воспроизведением. Методы Ecol Evol 2: 401–406. - 23.
Маккензи Д.И., Николс Д.Д., Саттон Н., Каваниши К., Бейли Б.Л. (2005) Улучшение выводов при популяционных исследованиях редких видов, которые обнаружены неидеально. Экология, 86 (5), 2005, с. 1101–1113. - 24.
Уильямс Б.К., Николс Д.Д., Конрой М.Дж. (2002) Анализ и управление популяциями животных. Сан-Диего: Academic Press. - 25.
Борчерс Д.Л., Бакленд С.Т., Цуккини В. (2003) Оценка численности животных: закрытые популяции. Нью-Йорк: Спрингер. - 26.
Бакленд С.Т., Андерсон Д.Р., Бернем К.П., Лааке Дж.Л., Борчерс Д.Л. и др. (2001) Введение в дистанционную выборку. Оксфорд: Издательство Оксфордского университета. - 27.
Fiske I, Chandler R (2011) Без пометки: пакет R для подгонки иерархических моделей встречаемости и численности диких животных. J Stat Softw 43: 1–23. - 28.
R Development Core Team (2011) R: Язык и среда для статистических вычислений. Вена, Австрия, ISBN 3-1-07-0, http: // www.R-project.org/. R Фонд статистических вычислений. - 29.
Йи Т.В. (2010) Пакет VGAM для категориального анализа данных. J Stat Softw 32: 1–34. - 30.
Hines JE (2014) ПРИСУТСТВИЕ — Программное обеспечение для оценки занятости участка и связанных параметров. USGS-PWRC http://www.mbr-pwrc.usgs.gov/software/presence.html. По состоянию на 19 мая 2014 г. - 31.
Guillera-Arroita G, Morgan BJT, Ridout MS, Linkie M (2011) Моделирование обитания видов для данных обнаружения, собранных вдоль разреза.J Agric Biol Envir Stat 16: 301–317. - 32.
Ройл Дж. А., Николс Дж. Д. (2003) Оценка численности по повторяющимся данным присутствия-отсутствия или точечным подсчетам. Экология 84: 777–790. - 33.
Laake J, Rextad E (2014) RMark — альтернативный подход к построению линейных моделей в MARK. В: Cooch E, White GC, редакторы. Программа MARK: A Gentle Introduction — Приложение C (издание 13). http://www.phidot.org/software/mark/docs/book/ Проверено 19 мая 2014 г. - 34.
White GC, Burnham KP (1999) Программа MARK: Оценка выживаемости в популяциях помеченных животных.Исследование птиц 46: 120–139. - 35.
Ланн Д., Джексон С., Бест Н., Томас А., Шпигельхальтер Д. (2012) Книга ОШИБКИ — Практическое введение в байесовский анализ: CRC Press — Чепмен и Холл. - 36.
Пламмер М. (2003) JAGS: программа для анализа байесовских графических моделей с использованием выборки Гиббса. Труды 3-го Международного семинара по распределенным статистическим вычислениям, Вена. - 37.
Кери М., Шауб М. (2012) Байесовский анализ населения с использованием WinBUGS — иерархическая перспектива.Уолтем: Academic Press. - 38.
Link WA (2003) Неидентифицируемость размера популяции по данным отлова-повторной поимки с неоднородными вероятностями обнаружения. Биометрия 59: 1123–1130. - 39.
Morgan BJT, Ridout MS (2008) Новая модель смеси для неоднородности захвата. App Statist 57: 433–446.
(PDF) Оптимальный контроль над инвазивными видами с неполной информацией об уровне заражения
Частично наблюдаемая марковская модель процесса принятия решений, описанная в разделе 2, является довольно общей, и
может использоваться для понимания того, насколько хорошо могут работать различные подходы к управлению. в более
реалистичных и сложных ситуациях.Например, модель может быть использована для решения оптимального управления
с большим количеством уровней заражения и с разными уровнями интенсивности мониторинга или обработок
, все из которых приведет к более сложному байесовскому обновлению убеждений. Другие дополнительные аспекты
, которые было бы полезно добавить, включают стратегии по снижению вероятности интродукции
и пространственной картины заражения. Однако добавление большей сложности увеличивает трудность поиска решений
.Другое необходимое направление будущих исследований — это поиск эвристических методов
, которые находят хорошие, но не обязательно оптимальные решения для сложных моделей.
Благодарности
Мы благодарим Дэвида Томберлина за то, что он познакомил нас с частично наблюдаемыми марковскими процессами принятия решений.
Мы также благодарим двух анонимных рецензентов и редактора за их полезные комментарии. Это исследование
поддержано Северной исследовательской станцией Лесной службы США.
Ссылки
Adams, R.М., Брайант, К.Дж., Маккарл, Б.А., Леглер, Д.М., О’Брайен, Дж.Дж., Солоу, А.Р., Вейхер, Р., 1995. Ценность улучшенной информации о погоде на дальние расстояния
. Современная экономическая политика 13 (3), 10–19.
Браун, К., Линч, Л., Зильберман, Д., 2002. Экономика борьбы с болезнями растений, передаваемыми насекомыми. Американский журнал
Экономика сельского хозяйства 84 (2), 279–291.
Кассандра, A.R., 1994. Оптимальные политики для частично наблюдаемого марковского процесса принятия решений. CS 94-14.Кафедра вычислительной техники
наук. Брауновский университет, Провиденс, Род-Айленд.
Костелло, К., Адамс, Р., Поласки, С., 1998. Значение прогнозов Эль-Ниньо в управлении лососем: стохастическая динамическая оценка.
. Американский журнал экономики сельского хозяйства 80, 765–777.
Костелло, К., Макаусленд, К., 2003. Протекционизм, торговля и меры ущерба от интродукции экзотических видов. Американский
Журнал экономики сельского хозяйства 85 (4), 964–975.
Костелло, К., Солоу, А., 2003. О закономерностях обнаружения интродуцированных видов. Труды Национальной академии наук
100 (6), 3321–3323.
Диксит А.К., Пиндик Р.С., 1994. Инвестиции в условиях неопределенности. Издательство Принстонского университета.
Eiswerth, M.E., Johnson, W.S., 2002. Управление некоренными инвазивными видами: выводы из динамического анализа. Экология
и экономика ресурсов 23 (3), 319–342.
Eiswerth, M.E., van Kooten, G.C., 2002. Неопределенность, экономика и распространение инвазивных видов растений.Американский журнал
Экономика сельского хозяйства 84 (5), 1317–1322.
Федер, Г., 1979. Пестициды, информация и борьба с вредителями в условиях неопределенности. Американский журнал экономики сельского хозяйства
61 (1), 97–103.
Finnoff, D., Tschirhart, J., 2005. Выявление, предотвращение и контроль инвазивных видов растений. Ecological Economics 52 (3), 397–
416.
Finnoff, D., Shogren, J.F., Leung, B., Lodge, D., 2007. Рискуйте: предпочитая предотвращение контролю над биологическими захватчиками.
Экологическая экономика 62 (2), 216–222.
Hanemann, W.M., 1989. Информация и концепция стоимости опциона. Журнал экономики и менеджмента окружающей среды 16
(1), 23–37.
Хейккила Дж., Пелтола Дж., 2004. Анализ системы защиты от колорадского жука в Финляндии. Экономика сельского хозяйства 31 (2–
3), 343–352.
Хоран, Р.Д., Перрингс, К., Лупи, Ф., Булт, Э., 2002. Стратегии предотвращения биологического загрязнения в условиях незнания: случай инвазивных видов
.Американский журнал экономики сельского хозяйства 84 (5), 1303–1310.
Кинг, Р.П., Суинтон, С.М., Либекер, Д.У., Ориад, К.А., 1998. Экономика борьбы с сорняками и ценность борьбы с сорняками.
Информация. В: Hatfield, J.L., Buhler, D.D., Steward, B.A. (Ред.), Комплексное управление сорняками и почвой. Жим спящего медведя.
Kovacs, K.F., Haight, R.G., McCullough, D.G., Mercader, R.J., Sieger, N.W., Liebhold, A.M., 2010. Стоимость потенциального изумрудного пепла
повреждений бурава в U.Сообщества С., 2009-2019 гг. Экологическая экономика 69, 569–578.
Леунг, Б., Лодж, Д.М., Финнофф, Д., Шогрен, Дж. Ф., Льюис, М. А., Ламберти, Г., 2002. Унция профилактики или фунт лечения:
Анализ биоэкономического риска инвазивных видов. Труды Лондонского королевского общества, биологические науки 269 (1508),
2407–2413.
Леунг Б., Финнофф Д., Шогрен Дж. Ф., Лодж Д. М., 2005. Управление инвазивными видами: практические правила для быстрой оценки. Экологический
Экономика 55 (1), 24–36.
Ловелл, С.