
Содержание
Статистические таблицы, их виды. Требования, предъявляемые к оформлению таблиц.
Поможем написать любую работу на аналогичную
тему
Получить выполненную работу или консультацию специалиста по вашему
учебному проекту
Узнать стоимость
Результаты сводки и группировки материалов статистического наблюдения, как правило, представляются в виде таблиц.
Статистической называется таблица, которая содержит сводную числовую характеристику исследуемой совокупности по одному или нескольким существенным признакам, взаимосвязанным логикой экономического анализа.
Табличной называется такая форма расположения числовой информации, при которой число располагается на пересечении четко сформулированного заголовка по вертикальному столбцу, называемому графой, и названия по соответствующей горизонтальной полосе — строке.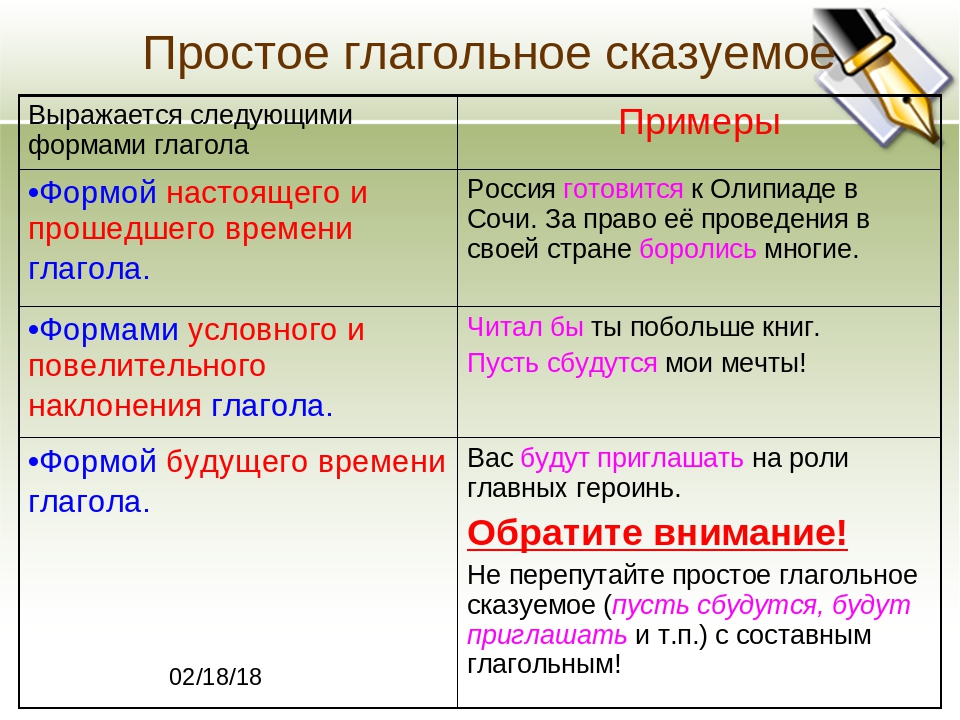
Статистическая таблица содержит три вида заголовков: общий, верхние и боковые. Общий заголовок отражает содержание всей таблицы (к какому месту и времени она относится), располагается над макетом таблицы по центру и является внешним заголовком. Верхние заголовки характеризуют содержание граф (заголовки сказуемого), а боковые (заголовки подлежащего) — строк. Они являются внутренними заголовками.
Остов таблицы, заполненный заголовками, образует макет таблицы; если на пересечении граф и строк записать цифры, то получается полная статистическая таблица.
Название таблицы
(общий заголовок)
Содержание строк | Наименование граф (верхние заголовки) | |||||
А | 1 | 2 | 3 | 4 | 5 | … |
Наименование строк (боковые заголовки) |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
| |
Итоговая строка |
|
|
|
|
| Итоговая графа |
Схема 2. 1. Остов (основа) статистической таблицы
1. Остов (основа) статистической таблицы
Цифровой материал может быть представлен абсолютными (численность населения РФ), относительными (индексы цен на продовольственные товары) и средними (среднемесячный доход служащего коммерческого банка) величинами.
По логическому содержанию таблица представляет собой «статистическое предложение», основными элементами которого являются подлежащее и сказуемое.
Подлежащим статистической таблицы называется объект, который характеризуется цифрами. Это может быть одна или несколько совокупностей, отдельные единицы совокупности в порядке их перечня или сгруппированные по каким-либо признакам, территориальные единицы и так далее.
Сказуемое статистической таблицы образует система показателей, которыми характеризуется объект изучения, то есть подлежащее таблицы. Сказуемое формирует верхние заголовки и составляет содержание граф с логически последовательным расположением показателей слева направо.
В зависимости от структуры подлежащего, от группировки единиц в нем, различают статистические таблицы простые и сложные, а последние, в свою очередь, подразделяются на групповые и комбинационные.
Простой называется такая таблица, в подлежащем которой дается перечень каких-либо объектов или территориальных единиц.
Простые таблицы различают монографические и перечневые. Монографические таблицы характеризуют не всю совокупность единиц изучаемого объекта, а только одну какую-либо группу из нее, выделенную по определенному признаку.
Подлежащее простой таблицы может быть сформировано по видовому, территориальному (например, численность населения по странам СНГ), временному и так далее принципам.
Простые таблицы не дают возможности выявить социально-экономические типы изучаемых явлений, их структуру, а также взаимосвязи и взаимозависимости между характеризующими их признаками.
Групповыми называются статистические таблицы, подлежащее которых содержит группировку единиц совокупности по одному количественному или атрибутивному признаку.
Комбинационными называются статистические таблицы, подлежащее которых содержит группировку единиц совокупности одновременно по двум и более признакам: каждая из групп, построенная по одному признаку, разбивается, в свою очередь, на подгруппы по какому-либо другому признаку и так далее.
Виды таблиц по разработке сказуемого.
В сказуемом статистической таблицы приводятся показатели, которые являются характеристикой изучаемого объекта.
По структурному строению сказуемого различают статистические таблицы с простой и сложной его разработкой.
При простой разработке сказуемого, показатель, определяющий его, не подразделяется на подгруппы и итоговые значения получаются путем простого суммирования значений по каждому признаку отдельно, независимо друг от друга.
Основные правила построения таблицы.
Статистические таблицы, как средство наглядного и компактного представления цифровой информации, должны быть статистически правильно оформлены.
1. Таблица должна быть компактной и содержать только те данные, которые непосредственно отражают исследуемое явление в статике и динамике и необходимы для познания его сущности.
Таблица должна быть компактной и содержать только те данные, которые непосредственно отражают исследуемое явление в статике и динамике и необходимы для познания его сущности.
2. Заголовок таблицы и названия граф и строк должны быть четкими, краткими, лаконичными, представлять собой законченное целое, органично вписывающееся в содержание текста.
3. Информация, располагаемая в столбцах (графах) таблицы, завершается итоговой строкой. Существуют различные способы соединения слагаемых граф с их итогом:
• строка «Итого» или «Всего» завершает статистическую таблицу;
• итоговая строка располагается первой строкой таблицы и соединяется с совокупностью ее слагаемых словами «В том числе».
4. Если названия отдельных граф повторяются между собой, содержат повторяющиеся термины или несут единую смысловую нагрузку, то необходимо им присвоить объединяющий заголовок.
5. Графы и строки полезно нумеровать.
6. Взаимосвязанные данные, характеризующие одну из сторон анализируемого явления целесообразно располагать в соседних друг с другом графах.
Взаимосвязанные данные, характеризующие одну из сторон анализируемого явления целесообразно располагать в соседних друг с другом графах.
7. Графы и строки должны содержать единицы измерения, соответствующие поставленным в подлежащем и сказуемом показателям.
8. Числа целесообразнее, по возможности, округлять. Если все числа одной и той же графы или строки даны с одним десятичным знаком, а одно из чисел имеет точно два знака после запятой, то числа с одним знаком после запятой следует дополнять нулем, тем самым подчеркнув их одинаковую точность.
9. В случае необходимости дополнительной информации — разъяснений к таблице, могут даваться примечания.
Внимание!
Если вам нужна помощь в написании работы, то рекомендуем обратиться к
профессионалам. Более 70 000 авторов готовы помочь вам прямо сейчас. Бесплатные
корректировки и доработки.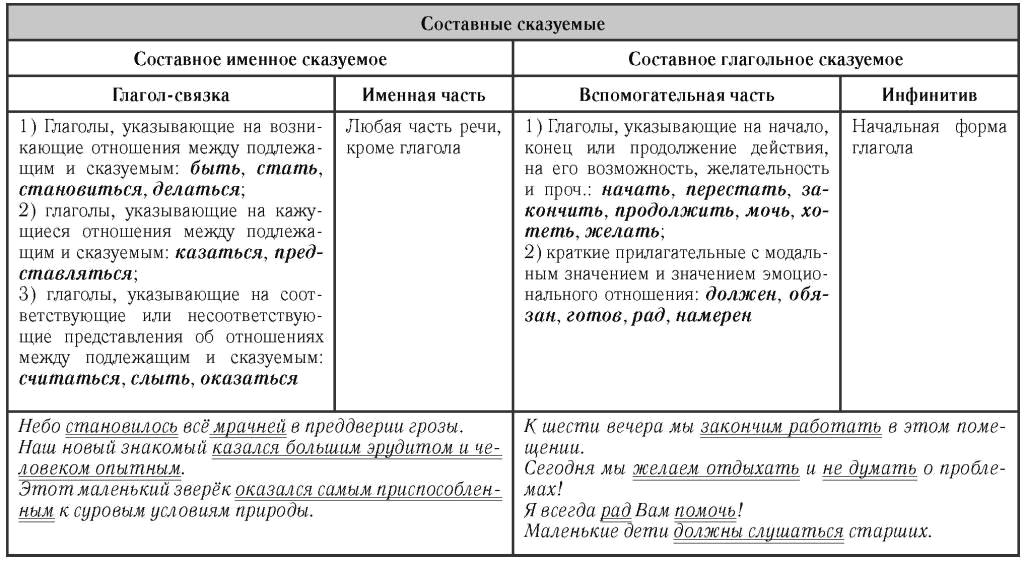 Узнайте стоимость своей работы.
Узнайте стоимость своей работы.
19. Статистические таблицы. Теория статистики
19. Статистические таблицы
В виде статистических таблиц оформляются результаты сводки и группировки материалов наблюдения.
Статистическая таблица – это особый способ краткой и наглядной записи сведений об изучаемых общественных явлениях. Статистическая таблица позволяет охватить материалы статистической сводки в целом.
По внешнему виду статистическая таблица представляет собой ряд пересекающихся горизонтальных и вертикальных линий, образующих по горизонтали строки, а по вертикали – графы (столбцы, колонки), которые в совокупности составляют как бы скелет таблицы.
В образовавшиеся внутри таблицы клетки записывается информация. Составленную таблицу принято называть макетом таблицы.
Статистическая таблица имеет свое подлежащее и сказуемое.
Подлежащее таблицы показывает, о каком явлении идет речь в таблице, и представляет собой группы и подгруппы, которые характеризуются рядом показателей.
Сказуемым таблицы называются числовые показатели, с помощью которых характеризуется объект, т. е. подлежащее таблицы.
Показатели, образующие подлежащее, располагают в левой части таблицы, а показатели, составляющие сказуемое, помещают справа.
Составленная и оформленная статистическая таблица должна иметь общий, боковые и верхние заголовки.
Простые таблицы не содержат в подлежащем систематизации изучаемых единиц статистической совокупности.
По характеру представляемого материала эти таблицы бывают собственно перечневые, территориальные и хронологические.
Простая таблица в подлежащем содержит перечисление единиц изучаемой совокупности.
Сведения простой таблицы применяют и для оценки изменения какого-либо явления во времени.
Групповые статистические таблицы дают более информативный материал для анализа изучаемых явлений благодаря образованным в их подлежащем группам по существенному признаку или выявлению связи между рядом показателей.
Комбинационными называют статистические таблицы, которые имеют в подлежащем группировку по двум или более группировочным признакам, связанным между собой.
Одними из ответственных моментов построения статистических таблиц являются разработка сказуемого, определение его содержания, правильное установление связи между группировочными признаками и показателями, их характеризующими.
Сказуемое статистических таблиц бывает простым и сложным. При простой разработке показатели сказуемого располагаются последовательно один за другим. Распределяя показатели на группы по одному или нескольким признакам в определенном сочетании, получают сложное сказуемое.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРес
3.
 Статистические таблицы. Общая теория статистики: конспект лекции
Статистические таблицы. Общая теория статистики: конспект лекции
3. Статистические таблицы
После того как данные статистического наблюдения собраны и даже сгруппированы, их трудно воспринимать и анализировать без определенной, наглядной систематизации. Результаты статистических сводок и группировок получают оформление в виде статистических таблиц.
Статистическая таблица – таблица, которая дает количественную характеристику статистической совокупности и представляет собой форму наглядного изложения полученных в результате статистической сводки и группировки числовых (цифровых) данных. По внешнему виду она представляет собой комбинацию вертикальных и горизонтальных строк. В ней обязательно должны быть общие боковые и верхние заголовки. Еще одной особенностью статистической таблицы является наличие в ней подлежащего (характеристика статистической совокупности) и сказуемого (показателя, характеризующего совокупности). Статистические таблицы являются формой наиболее рационального изложения результатов сводки или группировки.
Подлежащее таблицы представляет ту статистическую совокупность, о которой идет речь в таблице, т. е. перечень отдельных или всех единиц совокупности либо их групп. Чаще всего подлежащее помещается в левой части таблицы и содержит перечень строк.
Сказуемое таблицы – это те показатели, с помощью которых дается характеристика явления, отображаемого в таблице.
Подлежащее и сказуемое таблицы могут располагаться по-разному. Это технический вопрос, главное, чтобы таблица была легко читаемой, компактной и легко воспринималась.
В статистической практике и исследовательских работах используются таблицы различной сложности. Это зависит от характера изучаемой совокупности, объема имеющейся информации, задач анализа. Если в подлежащем таблицы содержится простой перечень каких-либо объектов или территориальных единиц, таблица называется простой. В подлежащем простой таблицы нет каких-либо группировок статистических данных. Простые таблицы имеют самое широкое применение в статистической практике. Характеристика городов Российской Федерации по численности населения, средней зарплате и иному представляется простой таблицей. Если подлежащее простой таблицы содержит перечень территорий (например, областей, краев, автономных округов, республик и т. д.), то такая таблица называется территориальной.
Характеристика городов Российской Федерации по численности населения, средней зарплате и иному представляется простой таблицей. Если подлежащее простой таблицы содержит перечень территорий (например, областей, краев, автономных округов, республик и т. д.), то такая таблица называется территориальной.
Простая таблица содержит только описательные сведения, ее аналитические возможности ограничены. Глубокий анализ исследуемой совокупности, взаимосвязей признаков предполагает построение более сложных таблиц – групповых и комбинационных.
Групповые таблицы в отличие от простых содержат в подлежащем не простой перечень единиц объекта наблюдения, а их группировку по одному существенному признаку. Простейшим видом групповой таблицы являются таблицы, в которых представлены ряды распределения. Групповая таблица может быть более сложной, если в сказуемом приводится не только число единиц в каждой группе, но и ряд других важных показателей, количественно и качественно характеризующих группы подлежащего. Такие таблицы часто используются в целях сопоставления обобщающих показателей по группам, что позволяет сделать определенные практические выводы. Более широкими аналитическими возможностями располагают комбинационные таблицы.
Такие таблицы часто используются в целях сопоставления обобщающих показателей по группам, что позволяет сделать определенные практические выводы. Более широкими аналитическими возможностями располагают комбинационные таблицы.
Комбинационными называются статистические таблицы, в подлежащем которых группы единиц, образованные по одному признаку, подразделяются на подгруппы по одному или нескольким признакам. В отличие от простых и групповых таблиц комбинационные позволяют проследить зависимость показателей сказуемого от нескольких признаков, которые легли в основу комбинационной группировки в подлежащем.
Наряду с перечисленными выше таблицами в статистической практике применяют таблицы сопряженности (или таблицы частот). В основе построения таких таблиц лежит группировка единиц совокупности по двум или более признакам, которые называются уровнями. Например, население делится по полу (мужской, женский) и т. п. Таким образом, признак А имеет n градаций (или уровней) A1 A2, An (в примере n = 2). Далее изучается взаимодействие признака А с другим признаком – В, который подразделяется на k градаций (факторов) B1, B2, Bк. В нашем примере признак В – принадлежность к какой-либо профессии, а B1, B2,., Bk принимают конкретные значения (доктор, водитель, учитель, строитель и т. д.). Группировка по двум и более признакам используется для оценки взаимосвязей между признаками А и В.
Далее изучается взаимодействие признака А с другим признаком – В, который подразделяется на k градаций (факторов) B1, B2, Bк. В нашем примере признак В – принадлежность к какой-либо профессии, а B1, B2,., Bk принимают конкретные значения (доктор, водитель, учитель, строитель и т. д.). Группировка по двум и более признакам используется для оценки взаимосвязей между признаками А и В.
В «свернутом» виде результаты наблюдений можно представить таблицей сопряженности, состоящей из n строк и k столбцов, в ячейках которых проставлены частоты событий nij, т. е. количество объектов выборки, обладающих комбинацией уровней Аi и Bj. Если между переменными A и B имеется взаимно-однозначная прямая или обратная функциональная связь, то все частоты nij концентрируются по одной из диагоналей таблицы. При связи не столь сильной некоторое число наблюдений попадает и на недиагональные элементы. В этих условиях перед исследователем стоит задача выяснить, насколько точно можно предсказать значение одного признака по величине другого.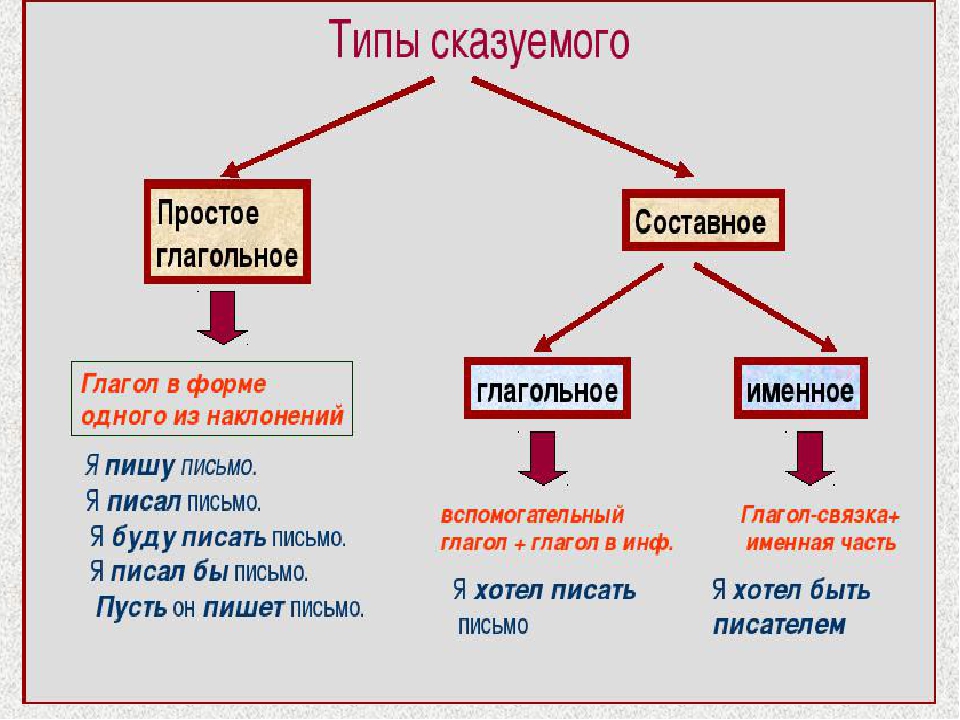 Таблица частот называется одномерной, если в ней табулирована только одна переменная. Таблица, в основе которой лежит группировка по двум признакам (уровням), которые табулируются по двум признакам (факторам), называется таблицей с двумя входами. Таблицы частот, в которых табулируются значения двух или более признаков, называются таблицами сопряженности.
Таблица частот называется одномерной, если в ней табулирована только одна переменная. Таблица, в основе которой лежит группировка по двум признакам (уровням), которые табулируются по двум признакам (факторам), называется таблицей с двумя входами. Таблицы частот, в которых табулируются значения двух или более признаков, называются таблицами сопряженности.
Из всех видов статистических таблиц наиболее широкое применение имеют простые таблицы, реже применяются групповые и особенно комбинационные статистические таблицы, а таблицы сопряженности строят для проведения специальных видов анализа. Статистические таблицы служат одним из важных способов выражения и изучения массовых общественных явлений, но лишь при условии их правильного построения.
Форма любой статистической таблицы должна наилучшим образом отвечать сущности выражаемого ею явления и целям его изучения. Это достигается путем соответствующей разработки подлежащего и сказуемого таблицы. Внешне таблица должна быть небольшой и компактной, иметь название, указание единиц измерения, а также времени и места, к которым относятся сведения. Заголовки строк и граф в таблице даются кратко, но точно и ясно. Чрезмерное загромождение таблицы цифровыми данными, неряшливое оформление затрудняют ее чтение и анализ. Перечислим основные правила построения статистических таблиц.
Заголовки строк и граф в таблице даются кратко, но точно и ясно. Чрезмерное загромождение таблицы цифровыми данными, неряшливое оформление затрудняют ее чтение и анализ. Перечислим основные правила построения статистических таблиц.
1. Статистическая таблица должна быть компактной и отражать только те исходные данные, которые прямо отражают исследуемое социально-экономическое явление в статике и динамике.
2. Заголовок статистической таблицы и название граф и строк должны быть четкими, краткими, лаконичными. В заголовке должны быть отражены объект, признак, время и место совершения события.
3. Графы и строки следует нумеровать.
4. Графы и строки должны содержать единицы измерения, для которых существуют общепринятые сокращения.
5. Лучше всего располагать сопоставляемую в ходе анализа информацию в соседних графах (либо одну под другой). Это облегчает процесс ее сравнения.
6. Для удобства чтения и работы числа в статистической таблице следует проставлять в середине граф, строго одно под другим: единицы под единицами, запятая под запятой.
7. Числа целесообразно округлять с одинаковой степенью точности (до целого знака, до десятой доли).
8. Отсутствие данных обозначается знаком умножения «ч», если данная позиция не подлежит заполнению, отсутствие сведений обозначается многоточием (…), либо н. д., либо н. св., при отсутствии явления ставится знак тире (-).
9. Для отображения очень малых чисел используют обозначение 0.0 или 0.00.
10. Если число получено на основании условных расчетов, то его берут в скобки, сомнительные числа сопровождают вопросительным знаком, а предварительные – знаком «!».
В случае необходимости дополнительной информации статистические таблицы сопровождаются сносками и примечаниями, в которых разъясняются, например, сущность специфического показателя, примененной методологии и т. д. Сносками пользуются для того, чтобы указать на ограничивающие обстоятельства, которые надо принять во внимание при чтении таблицы.
При соблюдении этих правил статистическая таблица становятся основным средством представления, обработки и обобщения статистической информации о состоянии и развитии изучаемых социально-экономических явлений.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРес
Статистические таблицы и графическое изображение статистических данных (стр. 1 из 4)
Статистические таблицы.
План.
1. Понятие о статистической таблице. Элементы статистической таблицы.
2. Виды таблиц по характеру подлежащего.
3. Виды таблиц по разработке сказуемого.
4. Основные правила построения таблиц.
5. Чтение и анализ таблицы.
1. Понятие о статистической таблице. Элементы статистической таблицы.
Результаты сводки и группировки материалов статистического наблюдения, как правило, излагаются в виде таблиц, делающих информацию обозримой.
Таблица является наиболее рациональной, наглядной и компактной формой представления статистического материала.
Таким образом, статистической называется таблица, которая содержит сводную числовую характеристику исследуемой совокупности по одному или нескольким существенным признакам, взаимосвязанным логикой экономического анализа.Статистическая таблица — форма рационального и наглядного изложения цифровых характеристик исследуемых явлений.
Статистическое обобщение информации и представление ее в виде сводных статистических таблиц дает возможность характеризовать размеры, структуру и динамику изучаемых явлений. Часто к статистической таблице дается общий заголовок, в котором указывается содержание таблицы, место и время, к которым относятся приводимые в таблице данные, а также единицы измерения, если они одинаковы для всех приведенных сведений.
Элементы статистической таблицы
Основные элементы статистической таблицы, представленные на рис.1, составляют ее основу.
* Примечания к таблице
Рис. 1. Остов (основа) статистической таблицы
Статистическая таблица содержит три вида заголовков:
· общий;
· верхний;
· боковые.
Общий заголовок отражает содержание всей таблицы (к какому месту и времени она относится), располагается над ее макетом по центру и является внешним заголовком. Верхние заголовки характеризуют содержание граф (заголовки сказуемого), а боковые (заголовки подлежащего) – срок. Они являются внутренними заголовками. Заголовки таблицы должны быть краткими и раскрывать содержание показателей.
Цифровой материал может быть представлен абсолютными (численность населения РФ), относительными (индексы цен на продовольственные товары) и средними (среднемесячный доход служащего коммерческого банка) величинами.
В случае необходимости таблицы могут сопровождаться примечанием, используемым с целью пояснения заголовков, методики расчета некоторых показателей, источников информации и т.д.
По логическому содержанию таблица представляет собой «статистическое предложение», основными элементами которого являются подлежащее и сказуемое.
Подлежащим статистической таблицы называется объект, характеризующийся цифрами. Это могут быть одна или несколько совокупностей, отдельные единицы совокупностей (фирмы, объединения) в порядке их перечня или сгруппированные по каким – либо признакам (отдельные территориальные единицы или временные периоды в хронологических таблицах и т.д.). Обычно подлежащее таблицы дается в левой части, в наименовании строк.
Это могут быть одна или несколько совокупностей, отдельные единицы совокупностей (фирмы, объединения) в порядке их перечня или сгруппированные по каким – либо признакам (отдельные территориальные единицы или временные периоды в хронологических таблицах и т.д.). Обычно подлежащее таблицы дается в левой части, в наименовании строк.
Сказуемое статистической таблицы образует система показателей, которыми характеризуется объект изучения, т.е. подлежащее таблицы. Сказуемое формирует верхние заголовки и составляет содержание граф с логически последовательным расположением показателей слева направо.
Расположение подлежащего и сказуемого может меняться местами, что зависит от достижения каждым исследователем в отдельности наиболее полного и лучшего способа прочтения и анализа исходной информации об исследуемой совокупности.
2. Виды таблиц по характеру подлежащего.
Вид статистической таблицы зависит от построения подлежащего. С этой точки зрения таблицы бывают:
— простые;
— сложные:
— групповые;
— комбинационные.
Простой называют таблицу, в которой объект исследования не подразделяется на группы. В этом случае возможны два варианта:
1) таблица содержит данные по совокупности в целом;
2) таблица содержит данные о каждой единице совокупности.
Последнее оправдано в том случае, если число единиц невелико. Например, в таблице приведены данные по каждому из 13 городов — миллионеров Российской Федерации. Таблица с данными о каждой единице может использоваться как рабочий материал для каких-либо последующих расчетов.
В простой таблице в подлежащем дается простой перечень каких-либо объектов или территориальных единиц, т.е. в подлежащем нет группировки единиц совокупности. Простые таблицы бывают монографические и перечневые. Монографические таблицы характеризуют не всю совокупность единиц изучаемого объекта, а только одну какую-либо группу из него, выделенную по определенному, заранее сформированному признаку.
Простыми перечневыми таблицами называются таблицы, подлежащее которых содержит перечень единиц изучаемого объекта.
Примером простой таблицы служит табл. 1.
Таблица 1
Объем основных услуг связи Российской Федерации
Источник: Социальное положение и уровень жизни населения России. Статистический сборник. М.: Госкомстат России, 2000. С. 411.
Подлежащее этой таблицы вынесено в заголовок таблицы; сама таблица — это сказуемое, причем значения показателей даны в динамике.
Групповая таблица — это таблица, в которой подлежащее, т. е. объект исследования, подразделяется на группы по какому-либо одно признаку (табл. 2).
Таблица 2
Распределение по уровню образования (по данным выборочных обследований населения РФ по проблемам занятости)
Источник: Социальное положение и уровень жизни населения России. Статистический сборник. М.: Госкомстат России, 2000. С. 80.
Комбинационная таблица включает подлежащее, в котором объект исследования разделен на группы по двум и более признакам. Например, табл. 3 станет комбинационной, если безработные будут подразделены на группы не только по уровню образования, но и по полу. При этом возможны следующие варианты построения таблицы.
При этом возможны следующие варианты построения таблицы.
1-й вариант: подлежащее расположено в левой части таблицы—группы, выделенные по одному признаку, подразделяются на подгруппы по другому признаку. Схематично это выглядит таким образом:
2-й вариант: подлежащее расположено в левой и верхней частях таблицы. Таблица имеет вид:
(%)
3. Виды таблиц по разработке сказуемого.
В сказуемом статистической таблицы, как уже говорилось, приводятся показатели, которые являются характеристикой изучаемого объекта. Эту характеристику можно давать небольшим числом показателей или целой системой показателей.
По структурному строению сказуемого различают статистические таблицы с простой и сложной его разработкой.
При простой разработке сказуемого показатель, определяющий его, не подразделяется на подгруппы, и итоговые значения получаются путем простого суммирования значений по каждому признаку отдельно независимо друг от друга. Примером простой разработки сказуемого может служить следующий фрагмент статистической таблицы.
Распределение акций среди работников приватизированных предприятий промышленности
После заполнения данного фрагмента таблицы получается подробная характеристика приватизированных предприятий по структуре их субъектов – владельцев. По каждому предприятию можно получить информацию о числе и ценовых условиях продажи акций.
Сложная разработка сказуемого предполагает деление признака, формирующего его, на подгруппы.
Распределение акций среди работников приватизированных предприятий промышленности
При сложной разработке сказуемого получается более полная и подробная характеристика объекта.
Сказуемое таблицы, виды таблиц по сказуемому
Статистическая таблица, виды таблиц.
Статистической называется таблица, которая содержит свободную числовую характеристику исследуемой совокупности по одному или нескольким существенным признакам, взаимосвязанным логикой экономического анализа.
Вид статистической таблицы определятеся характером разработки показателей ее полежащего.
Различают три вида статистических таблиц:
§ простые
§ групповые
§ комбинационные
Простые таблицы содержат перечень отдельных единиц, входящих в состав совокупности анализируемого экономического явления. В групповых таблицах цифровая информация в разрезе отдельных составных частей исследуемой совокупности данных объединяется в определенные группы в соответствии с каким-либо признаком. Комбинированные таблицысодержат отдельные группы и подгруппы, на которые подразделяются экономические показатели, характеризующие изучаемое экономическое явление. При этом такое подразделение осуществляется не по одному, а по нескольким признакам. в групповых таблицах осуществляется простая группировка показателей, а в комбинированных — комбинированная группировка. Простые таблицы вообще не содержат никакой группировки показателей. Последний вид таблиц содержит лишь несгруппированный набор сведений об анализируемом экономическом явлении.
Подлежащее таблицы, виды таблиц по подлежащему.
Подлежащее таблицы — это объект статистического изучения, то есть отдельные единицы совокупности, их группы или вся совокупность в целом.
В зависимости от структуры подлежащего и группировки в нем единиц различают статистические таблицы простые и сложные, а последние, в свою очередь, подразделяются на групповые и комбинационные.
В простой таблице в подлежащем дается простой перечень каких – либо объектов или территориальных единиц, т.е. в подлежащем нет группировки единиц совокупности. Простые таблицы бывают монографические и перечневые. Монографические таблицы характеризуют не всю совокупность единиц изучаемого объекта, а только одну какую-либо группу из него, выделенную по определенному, заранее сформулированному признаку
Групповыми называются статистические таблицы, подлежащее которых содержит группировку единиц совокупности по одному количественному или атрибутивному признаку. Сказуемое в групповых таблицах состоит из числа показателей, необходимых для характеристики подлежащего.
Комбинационныминазываются статистические таблицы, подлежащее которых содержит группировку единиц совокупности одновременно по двум и более признакам: каждая из групп, построенная по одному признаку, разбивается, в свою очередь, на подгруппы по какому – либо другому признаку и т.д
Групповые и комбинационные таблицы позволяют глубже раскрыть сущность и закономерность изучаемых социально – экономических явлений и процессов.
Сказуемое таблицы, виды таблиц по сказуемому
В сказуемом статистической таблицы, как уже говорилось, приводятся показатели, которые являются характеристикой изучаемого объекта. Эту характеристику можно давать небольшим числом показателей или целой системой показателей.
По структурному строению сказуемого различают статистические таблицы с простой и сложной его разработкой.
При простой разработке сказуемого показатель, определяющий его, не подразделяется на подгруппы, и итоговые значения получаются путем простого суммирования значений по каждому признаку отдельно независимо друг от друга. Примером простой разработки сказуемого может служить следующий фрагмент статистической таблицы.
Примером простой разработки сказуемого может служить следующий фрагмент статистической таблицы.
Сложная разработка сказуемогопредполагает деление признака, формирующего его, на подгруппы.
При сложной разработке сказуемого получается более полная и подробная характеристика объекта.
Комбинированная разработка показателей по условиям продажи акций и их видам позволяет углубить экономико – статистический анализ рынка акций и его структуры по приватизированным предприятиям.
Однако сложная разработка сказуемого может привести к безмерному увеличению размерности статистических таблиц, что, в свою очередь, снижает их наглядность, чтение и анализ.
Поэтому исследователь при построении статистических таблиц должен руководствоваться оптимальным соотношением показателей сказуемого и учитывать как положительные, так и отрицательные моменты сложной разработки показателей сказуемого.
4 Понятие статистической таблицы — СтудИзба
Тема 4. Понятие статистической таблицы. Виды статистических таблиц.
Виды статистических таблиц.
1. Понятие статистических таблиц. Составные части и элементы таблицы.
2. Виды статистических таблиц
3. Правила составления и оформления статистических таблиц.
-1-
Результаты статистической сводки материалов даются в виде статистических таблиц.
Статистическая таблица – это форма систематизированного, рационального и наглядного изложения цифрового материала характеризующего изучаемые явления и процессы.
Название таблицы
(общее заглавие)
В статистической таблице есть подлежащие и сказуемое.
Подлежащим называется объект изучения (единицы статистической совокупности, которые характеризуются числовыми показателями).
Сказуемым называется перечень числовых показателей, которым характеризуется объект изучения, т.е. подлежащие.
-2-
В зависимости от построения подлежащего статистические таблицы подразделяются на:
1. простые
простые
2. групповые
3. комбинационные.
Простыми называются такие таблицы, в подлежащем которых нет группировок.
Простые таблицы бывают:
· перечневыми
· хронологическими
· территориальными
В перечневых простых таблицах в подлежащем даётся перечень единиц составляющих объект изучения (промышленность).
Если в подлежащем таблицы дан перечень территорий, то такая называется территориальной простой.
Если в подлежащем таблицы дан перечень дат или периодов времени, то такая таблица называется хронологической.
Групповыми таблицами называется такие статистические таблицы, в которых изучаемый объект разделён в подлежащем на группы по тому или иному признаку. Иначе говоря, групповые таблицы образуются при использовании метода группировок.
Комбинационными таблицами называются такие, подлежащие которых разбивается на группы не по одному, а по двум или более признакам. При построении таблиц это будет означать, что каждая из групп выделенная при построении групповой таблицы разбивается ещё на подгруппы по какому-либо новому признаку.
-3-
Практикой выработаны следующие основные правила составления и оформления статистических таблиц:
1. Таблица должна быть, по возможности небольшой по размерам.
2. Название таблицы, заглавие строк подлежащего и граф сказуемого должны быть сформулированы точно, ясно и кратко, должны иметь единицы измерения, в названии таблицы следует указать территорию и период, к которым относятся приводимые данные. (Баланс трудовых ресурсов по Сев. Каз. Обл. за 1999 г.).
3. Строки подлежащего и графы сказуемого обычно различаются по принципу от частного к общему, т.е. сначала показывают слагаемые, а в конце подлежащего или сказуемого подводят итоги.
4. Строки и графы в таблице обычно нумеруются, для того чтобы удобнее было ссылаться на цифры в таблице.
5. При заполнении таблицы пользуются следующими условными обозначениями:
· Если данное явление совокупности не имеет места, то ставят «-».
· Если сведения о данном явлении отсутствует, то пишут «нет св. », «н. св.»
», «н. св.»
· Если сведения имеются, но числовые значения меньше принятой в таблице точности, то пишут «0,0», «0,00».
· Если данная позиция или клеточка на пересечении строки и графы вообще не подлежит заполнению, то ставят «X».
ВОПРОС Статистические таблицы: понятие, элементы, виды.
Статистическая таблица — форма наиболее рационального изложения полученных в результате статистической сводки и группировки числовых (цифровых) данных По внешнему виду она представляет собой комбинацию вертикальных и горизонтальных строк, содержащую боковые и верхние заголовки. Статистическая таблица содержит подлежащее и сказуемое.
Различают три вида статистических таблиц:
простые
групповые
комбинационные
Простые таблицы содержат перечень отдельных единиц, входящих в состав совокупности анализируемого экономического явления. В групповых таблицах цифровая информация в разрезе отдельных составных частей исследуемой совокупности данных объединяется в определенные группы в соответствии с каким-либо признаком. Комбинированные таблицы содержат отдельные группы и подгруппы, на которые подразделяются экономические показатели, характеризующие изучаемое экономическое явление. При этом такое подразделение осуществляется не по одному, а по нескольким признакам. в групповых таблицах осуществляется простая группировка показателей, а в комбинированных — комбинированная группировка. Простые таблицы вообще не содержат никакой группировки показателей. Последний вид таблиц содержит лишь несгруппированный набор сведений об анализируемом экономическом явлении.
Комбинированные таблицы содержат отдельные группы и подгруппы, на которые подразделяются экономические показатели, характеризующие изучаемое экономическое явление. При этом такое подразделение осуществляется не по одному, а по нескольким признакам. в групповых таблицах осуществляется простая группировка показателей, а в комбинированных — комбинированная группировка. Простые таблицы вообще не содержат никакой группировки показателей. Последний вид таблиц содержит лишь несгруппированный набор сведений об анализируемом экономическом явлении.
статистическме таблицы:понятие,элементы,виды.
Табличный способ изложения статистических показателей
Статистическая таблица — способ рационального изложения и наглядного представления статистических данных; систематическое размещение числовых данных в серии рядов и колонок с целью обеспечения понимания и сопоставления данных.
Результаты статистической сводки и группировки, как правило, помещаются в статистических таблицах и графиках, представляющих собой рациональное, наглядное, компактное и систематизированное изложение статистических показателей. Это — четвертый элемент сводки и группировки.
Это — четвертый элемент сводки и группировки.
С технической стороны статистическая таблица представляет собой ряд взаимно пересекающихся горизонтальных и вертикальных линий.
Горизонтальные линии таблицы именуются строками, а вертикальные — графами (столбцами, колонками). Каждая строка и графа имеют свое наименование (заголовок), соответствующее содержание показателей, помещенных в таблице, а таблица в целом имеет общее наименование, определяющее ее содержание.
Любая правильно составленная статистическая таблица содержит два основных элемента: подлежащее и сказуемое. Подлежащее — это объект изучения или перечень единиц совокупности (их групп), которые характеризуются в таблице. Как правило, но не обязательно, подлежащее располагается в крайней левой графе на месте боковых заголовков. Сказуемое — это перечень показателей, которыми характеризуется подлежащее. Сказуемое обычно располагается в графах правее подлежащего, но это требование также не обязательное.
При разработке таблиц в процессе сводки и группировки статистических показателей следует иметь в виду, чтобы это не было простым собиранием данных, размешенных в произвольном порядке. Каждая таблица должна заключать в себе аналитическое изложение результатов наблюдения, чтобы в последовательном ряду строк и граф развертывалась цифровая картина тех явлений, которые подлежат изучению и анализу.
Каждая таблица должна заключать в себе аналитическое изложение результатов наблюдения, чтобы в последовательном ряду строк и граф развертывалась цифровая картина тех явлений, которые подлежат изучению и анализу.
Таблицы бывают простые, групповые и комбинационные.
Простые таблицы — это перечневые, территориальные и хронологические. Перечневые простые таблицы имеют в подлежащем элементарный перечень однородных признаков, составляющих единый объект изучения. Например, дается перечень ступеней образования: начальное, среднее, высшее. В подлежащем простой территориальной таблицы приводятся территории районов, городов, областей, которые в последующих графах характеризуются теми или иными количественными показателями, например, по уровню регистрации рождений, смертей, браков или разводов. Хронологическими простыми называются таблицы, в подлежащем которых даны периоды времени (годы, кварталы, месяцы).
Деление простых таблиц на перечисленные виды очень условно, поскольку эти виды могут сочетаться между собой по-разному, образуя перечневую хронологическую таблицу или территориальную хронологическую. Во всех простых таблицах сказуемое, как правило, одно.
Во всех простых таблицах сказуемое, как правило, одно.
В групповых таблицах подлежащее подразделяется на отдельные группы по какому-то одному признаку. Например, гражданские дела, рассмотренные судом, делятся на трудовые, жилищные, семейные, имущественные, финансовые, которые в свою очередь могут распределяться по результатам рассмотрения дел (иск удовлетворен, в иске отказано, иск оставлен без рассмотрения) и т. д. Сказуемое групповых таблиц также может быть сложным, отражающим различные стороны подлежащего.
Комбинационные таблицы характеризуют юридически значимые явления через многие признаки и свойства, отраженные как в подлежащем, так и в сказуемом. Примером может служить таблица 1, где преступления экономической направленности вначале расчленяются в подлежащем на важнейшие группы (по главам УК), а группы — на отдельные наиболее опасные и распространенные виды (по статьям УК). Кроме этого, в подлежащем этой таблицы выделяются преступления, по которым предварительное следствие обязательно, тяжкие и особо тяжкие; связанные с потребительским рынком, финансово-кредитной системой и другими важными формами экономической деятельности. Сказуемое этой таблицы также многоплане во. Кроме общего числа выявленных преступлений по каждой позиции боковых заголовков, там приводится их удельный вес в общем числе преступлений экономической направленности, выделяются преступления, совершенные в крупных или особо крупных размерах, либо причинившие крупный ущерб, и вновь выделяется их удельный вес.
Сказуемое этой таблицы также многоплане во. Кроме общего числа выявленных преступлений по каждой позиции боковых заголовков, там приводится их удельный вес в общем числе преступлений экономической направленности, выделяются преступления, совершенные в крупных или особо крупных размерах, либо причинившие крупный ущерб, и вновь выделяется их удельный вес.
При всей сложности качественно-количественных характеристик того или иного явления они, как правило, взаимосвязаны между собой, поскольку отражают одно и то же явление, только с разных сторон. Типичным примером комбинационных таблиц высокой сложности могут быть формы отчетов по государственной или ведомственной отчетности.
Разработка таблицы начинается с создания макета, который формируется, исходя из наличного фактического материала, целевого назначения будущей таблицы и требований ее наглядности. Наряду с этим статистическая деятельность выработала ряд практически значимых правил, которые желательно соблюдать при разработке статистических таблиц.
Таблица должна быть оптимальной по своему размеру. С одной стороны, содержать все необходимые показатели, с другой — не быть перегруженной избыточной статистической информацией. Если необходимой информации много, что делает ее сложной в понимании, то целесообразно разработать несколько взаимосвязанных таблиц, снабдив их конкретными пояснениями. Отчет о следственной работе, приведенный в качестве примера, по своей структуре построен именно таким образом.
Каждая таблица должна иметь четкое общее название, а также названия подлежащего и сказуемого, их групп и разделов. Таблицы без названий понимаются с трудом. Кроме того, в них должны быть указаны единицы измерения, территория, период времени и другие необходимые сведения, привязывающие таблицу к конкретному содержанию, объему данных, времени и пространству.
Строки подлежащего и графы сказуемого могут размещаться от частного к общему или наоборот. Итоговые показатели обычно помещаются на последней строке или графе. Однако исходя из задач, решаемых таблицей, итоговые показатели могут быть приведены и в первой строке.
Однако исходя из задач, решаемых таблицей, итоговые показатели могут быть приведены и в первой строке.
Для удобства пользования (в том числе и для ссылок), особенно если таблица большая и располагается на нескольких листах, ее строки и графы могут нумероваться (обозначаться) порядковыми числами или буквами по алфавиту.
Использование предикатов в запросах
Использование предикатов в запросах
Предикат — это условное выражение, которое в сочетании с логическими операторами И и ИЛИ составляет набор условий в WHERE,
Предложение HAVING или ON. В SQL предикат, имеющий значение UNKNOWN, интерпретируется как FALSE.
Предикат, который может использовать индекс для извлечения строк из таблицы, называется sargable .Это название происходит от фразы с аргументом поиска . Предикаты, которые включают сравнения столбца с константами, другими столбцами или выражениями, могут быть саргируемыми.
Предикаты, которые включают сравнения столбца с константами, другими столбцами или выражениями, могут быть саргируемыми.
Предикат в следующем утверждении является sargable. SQL Anywhere может эффективно оценить его, используя первичный индекс
таблица Сотрудники.
На плане это выглядит так: Сотрудники <Сотрудники>
Напротив, следующий предикат не подлежит разложению.Хотя столбец EmployeeID индексируется в первичном индексе, с использованием
этот индекс не ускоряет вычисление, потому что результат содержит всю или все строки, кроме одной.
На плане это выглядит так: Сотрудники
Точно так же никакой индекс не может помочь в поиске всех сотрудников, чье имя оканчивается на букву k. Опять же, единственное средство
Для вычисления этого результата нужно исследовать каждую из строк по отдельности.
Функции
В общем случае предикат, который имеет функцию для имени столбца, не может быть саргирован. Например, индекс не будет использоваться для
следующий запрос:
Чтобы избежать использования функции, вы можете переписать запрос, чтобы сделать его доступным для сортировки. Например, вы можете перефразировать приведенный выше запрос:
Запрос, использующий функцию, становится доступным, если вы сохраняете значения функции в вычисляемом столбце и строите индекс на
этот столбец.Вычисляемый столбец — это столбец, значения которого получены из других столбцов в таблице. Например, если у вас есть столбец с именем OrderDate
который содержит дату заказа, вы можете создать вычисляемый столбец с именем OrderYear, который содержит значения за год, извлеченный
из столбца OrderDate.
Затем вы можете добавить индекс в столбец OrderYear обычным способом:
Если вы затем выполните следующую инструкцию, сервер базы данных распознает, что существует индексированный столбец, содержащий этот
информации и использует этот индекс для ответа на запрос.
Домен вычисляемого столбца должен быть эквивалентен домену выражения COMPUTE для подстановки столбца
быть произведенным. В приведенном выше примере, если бы YEAR (OrderDate) вернул строку вместо целого числа, оптимизатор не заменил бы вычисляемый столбец для выражения,
и индекс IDX_year не мог использоваться для извлечения требуемых строк.
Для получения дополнительной информации о вычисляемых столбцах см. Работа с вычисляемыми столбцами.
Примеры
В каждом из этих примеров атрибуты x и y являются столбцами одной таблицы. Атрибут z содержится в отдельной таблице. Предположим, что для каждого из этих атрибутов существует индекс.
| Sargable | Не подлежит продаже |
|---|---|
| x = 10 | x <> 10 |
| x НУЛЬ | x НЕ ПУТЬ |
| x > 25 | x = 4 ИЛИ y = 5 |
| x = z | x = y |
| x ДЮЙМ (4, 5, 6) | x НЕ В (4, 5, 6) |
| x КАК ‘pat%’ | x КАК ‘% tern’ |
| x = 20 — 2 | х + 2 = 20 |
Иногда может быть неочевидно, является ли предикат саргируемым. В этих случаях вы можете переписать предикат
В этих случаях вы можете переписать предикат
так что это sargable. Для каждого примера вы можете переписать предикат x LIKE ‘pat%’, используя тот факт, что u является следующей буквой в алфавите после t: x > = ‘pat’ и x <'pau'. В этой форме индекс атрибута x помогает находить значения в ограниченном диапазоне. К счастью, SQL Anywhere выполняет именно это преобразование для
вы автоматически.
Предикат sargable, используемый для индексированного поиска по таблице, — это предикат , соответствующий . Предложение WHERE может иметь много совпадающих предикатов. Наиболее подходящий предикат может зависеть от стратегии соединения.
Оптимизатор повторно оценивает свой выбор совпадающих предикатов при рассмотрении альтернативных стратегий соединения. См. Обнаружение пригодных для использования условий посредством вывода предикатов.
Предикаты, помещенные в представления или производные таблицы
Оператор SQL, который ссылается на представление, также может включать предикат. Рассмотреть возможность
Рассмотреть возможность
вид v2 (a, b) :
СОЗДАТЬ ПРОСМОТР v2 (a, b) AS SELECT sales_person, MAX (продажи) ОТ ПРОДАЖ ГРУППА ПО продавцу
Следующий оператор ссылается на представление и включает предикат:
ВЫБРАТЬ * ОТ v2 ГДЕ a = 'LUCCHESSI'
Когда Дерби преображается
этот оператор, сначала преобразовав представление в производную таблицу, он помещает
предикат на верхнем уровне нового запроса, за пределами области действия
производная таблица:
SELECT a, b FROM (SELECT sales_person, MAX (продажи) ОТ ПРОДАЖ ГДЕ sales_person = 'LUCCHESSI' ГРУППА ПО продавцу) v1 (а, б)
В примере в предыдущем разделе (см. Сглаживание вида) Derby смог сгладить
производную таблицу в основной SELECT, чтобы предикат во внешнем SELECT мог
быть оцененным в полезной точке запроса.Это невозможно в этом
пример, потому что базовое представление не удовлетворяет всем требованиям
выравнивания обзора.
Однако, если источником всех ссылок на столбцы в предикате является
просто
ссылка на столбец в базовом представлении или таблице, Derby — это
возможность подтолкнуть предикат вниз к нижележащему представлению. Толкать
Толкать
вниз означает, что квалификация, описанная предикатом, может быть оценена
когда оценка оценивается. В нашем примере ссылка на столбец в
внешний предикат a в нижележащем представлении является простым
ссылка столбца на базовую базу
Таблица.Итак, окончательное преобразование этого оператора после предиката
вниз:
ВЫБРАТЬ a, b FROM (SELECT sales_person, MAX (sales) из отдела продаж ГДЕ sales_person = 'LUCCHESSI' ГРУППА ПО продавцу) v1 (a, b)
Без трансформации Дерби
нужно сканировать всю таблицу t1 , чтобы сформировать все группы, только чтобы бросить
из всех групп, кроме одной. С преобразованием Дерби
возможность сделать эту квалификационную часть производной таблицы.
Если бы существовал предикат, ссылающийся на столбец b , он не мог бы
быть сдвинутым вниз, потому что в нижележащем представлении столбец b не является простым
ссылка на столбец.
Преобразование раскрывающегося списка предикатов включает предикаты, которые ссылаются на несколько
таблицы из базового соединения.
предикатов (datascience.predicates) — документация по datascience 0.15.7
>>> из таблицы импорта данных
>>> t = Таблица (). with_columns ([
... "Размеры", ["S", "M", "L", "XL"],
... 'Талии', [30, 34, 38, 42],
...])
>>> t.where ('Размеры', are.equal_to ('L'))
Размеры | Талии
L | 38
>>> t.where ('Талии', выше (38))
Размеры | Талии
XL | 42
>>> т.где ('Талии', are.above_or_equal_to (38))
Размеры | Талии
L | 38
XL | 42
>>> t.where ('Талии', ниже (38))
Размеры | Талии
S | 30
M | 34
>>> t.where ('Талии', are.below_or_equal_to (38))
Размеры | Талии
S | 30
M | 34
L | 38
>>> t.where ('Талии', are.strictly_between (30, 38))
Размеры | Талии
M | 34
>>> t.where ('Талии', между (30, 38))
Размеры | Талии
S | 30
M | 34
>>> t.where ('Талии', are.between_or_equal_to (30, 38))
Размеры | Талии
S | 30
M | 34
L | 38
>>> т.где ('Размеры', are.equal_to ('L'))
Размеры | Талии
L | 38
>>> t.where ('Талии', are.not_above (38))
Размеры | Талии
S | 30
M | 34
L | 38
>>> t.where ('Талии', are.not_above_or_equal_to (38))
Размеры | Талии
S | 30
M | 34
>>> t. where ('Талии', are.not_below (38))
Размеры | Талии
L | 38
XL | 42
>>> t.where ('Талии', are.not_below_or_equal_to (38))
Размеры | Талии
XL | 42
>>> t.where ('Талии', are.not_strictly_between (30, 38))
Размеры | Талии
S | 30
L | 38
XL | 42
>>> т.где ('Талии', are.not_between (30, 38))
Размеры | Талии
L | 38
XL | 42
>>> t.where ('Талии', are.not_between_or_equal_to (30, 38))
Размеры | Талии
XL | 42
>>> t.where ('Размеры', are.conpting ('L'))
Размеры | Талии
L | 38
XL | 42
>>> t.where ('Размеры', are.not_conpting ('L'))
Размеры | Талии
S | 30
M | 34
>>> t.where ('Размеры', are.conhibited_in ('MXL'))
Размеры | Талии
M | 34
L | 38
XL | 42
>>> t.where ('Размеры', are.conhibited_in ('L'))
Размеры | Талии
L | 38
>>> т.где ('Размеры', are.not_conolated_in ('MXL'))
Размеры | Талии
S | 30
where ('Талии', are.not_below (38))
Размеры | Талии
L | 38
XL | 42
>>> t.where ('Талии', are.not_below_or_equal_to (38))
Размеры | Талии
XL | 42
>>> t.where ('Талии', are.not_strictly_between (30, 38))
Размеры | Талии
S | 30
L | 38
XL | 42
>>> т.где ('Талии', are.not_between (30, 38))
Размеры | Талии
L | 38
XL | 42
>>> t.where ('Талии', are.not_between_or_equal_to (30, 38))
Размеры | Талии
XL | 42
>>> t.where ('Размеры', are.conpting ('L'))
Размеры | Талии
L | 38
XL | 42
>>> t.where ('Размеры', are.not_conpting ('L'))
Размеры | Талии
S | 30
M | 34
>>> t.where ('Размеры', are.conhibited_in ('MXL'))
Размеры | Талии
M | 34
L | 38
XL | 42
>>> t.where ('Размеры', are.conhibited_in ('L'))
Размеры | Талии
L | 38
>>> т.где ('Размеры', are.not_conolated_in ('MXL'))
Размеры | Талии
S | 30
Работа с предикатами сравнения и сгруппированными запросами
Причина, по которой SQL-92 включает квалификатор ANY и синонимичный SOME, связана с двусмысленностью слова any. Если я спрошу: «Кто-нибудь из вас знает, как написать оператор SQL SELECT с предложением WHERE?» Я использую любой как экзистенциальный квантификатор для обозначения «хотя бы один» или «несколько». С другой стороны, если я говорю: «Я могу печатать быстрее, чем любой из вас», я использую любое слово в качестве универсального квантификатора, означающего «все».«Таким образом, когда вы пишете WHERE в операторе SELECT, например, если СУБД должна интерпретировать любой как экзистенциальный квантификатор, чтобы означать» Отображение столбцов в строке из
С другой стороны, если я говорю: «Я могу печатать быстрее, чем любой из вас», я использую любое слово в качестве универсального квантификатора, означающего «все».«Таким образом, когда вы пишете WHERE в операторе SELECT, например, если СУБД должна интерпретировать любой как экзистенциальный квантификатор, чтобы означать» Отображение столбцов в строке из
если b больше, чем хотя бы одно из значений в «? Или СУБД должна рассматривать любое значение как универсальный квантификатор, означающий» Отображать столбцы в строке из
если b больше всех значений в «?
ВЫБРАТЬ * ИЗ
ГДЕ b> ЛЮБОЙ
Чтобы прояснить путаницу, разработчики SQL-92 добавили SOME (которое имеет только одно значение — «один или несколько») к стандарту SQL-92 и сохранили экзистенциальное ANY как синоним обратной совместимости.
Понимание УНИКАЛЬНОГО предиката
Предикат UNIQUE в предложении WHERE позволяет выполнять оператор DELETE, INSERT, SELECT или UPDATE в зависимости от того, создает ли подзапрос в предикате UNIQUE таблицу результатов, в которой все строки не дублируются (то есть все строки в таблице результатов уникальны). Если строки таблицы результатов подзапроса уникальны, СУБД выполняет оператор SQL для тестируемой строки.И наоборот, если в таблице результатов есть хотя бы один набор повторяющихся строк, СУБД пропускает выполнение команды SQL и переходит к проверке следующей строки в таблице.
Если строки таблицы результатов подзапроса уникальны, СУБД выполняет оператор SQL для тестируемой строки.И наоборот, если в таблице результатов есть хотя бы один набор повторяющихся строк, СУБД пропускает выполнение команды SQL и переходит к проверке следующей строки в таблице.
Например, чтобы получить список продавцов, которые либо не продавали, либо совершили только одну продажу в течение сентября 2000 года, вы можете выполнить запрос, подобный:
ВЫБЕРИТЕ emp_ID, first_name, last_name ОТ сотрудников Где УНИКАЛЬНО (ВЫБЕРИТЕ продавца ИЗ счетов-фактур ГДЕ invoice_date> = '01.09.2000' И invoice_date <= '30.09.2000' И счета-фактуры.продавец = сотрудники.emp_ID)
Всегда используется вместе с подзапросом, синтаксис UNIQUE:
[НЕ] УНИКАЛЬНЫЙ
Если таблица результатов, созданная подзапросом в предикате UNIQUE, либо не имеет строк, либо не имеет повторяющихся строк, предикат UNIQUE возвращает TRUE. В текущем примере таблица результатов подзапроса содержит единственный столбец SALESPERSON. Следовательно, если идентификатор продавца появляется не более чем в одной строке в таблице результатов (что означает, что человек совершил не более одной продажи в течение периода), внешний оператор SELECT отобразит идентификатор и имя сотрудника. С другой стороны, если в таблице результатов подзапроса есть один или несколько наборов повторяющихся строк, предикат UNIQUE оценивается как FALSE, и СУБД переходит к проверке следующей строки в таблице EMPLOYEES.
Следовательно, если идентификатор продавца появляется не более чем в одной строке в таблице результатов (что означает, что человек совершил не более одной продажи в течение периода), внешний оператор SELECT отобразит идентификатор и имя сотрудника. С другой стороны, если в таблице результатов подзапроса есть один или несколько наборов повторяющихся строк, предикат UNIQUE оценивается как FALSE, и СУБД переходит к проверке следующей строки в таблице EMPLOYEES.
| Примечание | При проверке повторяющихся значений в таблице результатов подзапроса предикат UNIQUE игнорирует любые значения NULL.Таким образом, если подзапрос в предикате UNIQUE дает таблицу результатов Продавец cust_ID sales_total ----------- ------- ----------- 101 ПУСТО 100.00 101 1000 NULL 101 NULL NULL 101 1000 100,00 предикат будет оцениваться как ИСТИНА, потому что никакие две строки не имеют столбцов со всеми одинаковыми значениями, отличными от NULL. |

Некоторые СУБД поддерживают предикат UNIQUE.Поэтому обязательно ознакомьтесь с руководством по системе, прежде чем использовать его в своем коде SQL. Если ваша СУБД не поддерживает предикат, вы всегда можете использовать агрегатную функцию COUNT в предложении WHERE для достижения той же цели. Например, запрос
ВЫБЕРИТЕ emp_ID, first_name, last_name ОТ сотрудников ГДЕ (ВЫБРАТЬ количество (продавец) ИЗ счетов-фактур ГДЕ invoice_date> = '01.09.2000' И invoice_date <= '30.09.2000' И счета-фактуры.продавец = сотрудники.emp_ID) <= 1
выдаст те же результаты, что и предыдущий пример запроса, в котором использовался предикат UNIQUE для вывода списка продавцов с нулевой или одной продажей за сентябрь 2000 года.
Использование предиката OVERLAPS для определения перекрытия одного DATETIME другого
Предикат OVERLAPS использует синтаксис
(,
{|}) ПЕРЕГРУЗКИ
(,
{|})
где
::
{DATE} | {TIME) | {TIMESTAMP}
::
{DATE) | [TIME} | {TIMESTAMP} |
{ИНТЕРВАЛ}
::
'' {ГОД | МЕСЯЦ | ДЕНЬ | ЧАС | МИНУТА | СЕКУНДА}
, чтобы вы могли проверить два хронологических периода времени на совпадение.
Например, предикат OVERLAPS
(ДАТА '01-01-2000 ', ИНТЕРВАЛ' 03 'МЕСЯЦЕВ) ПЕРЕГРУЗКИ (ДАТА '03-15-2000 ', ИНТЕРВАЛ' 10 'ДНЕЙ)
оценивается как ИСТИНА, поскольку часть второго диапазона дат (с 15.03.200 по 25.03.2000) находится в пределах (или перекрывает) часть первого диапазона дат (с 01.01.2000 по 04.01.2000). ). Точно так же предикат OVERLAPS
(ВРЕМЯ '09: 23: 00 ', ВРЕМЯ '13: 45: 00') ПЕРЕЗАГРУЗКИ (ВРЕМЯ '14: 00: 00 ', ВРЕМЯ '14: 25: 00')
оценивается как ЛОЖЬ, потому что никакая часть второго периода времени не лежит в пределах (или перекрывает) часть первого периода времени.
Многие продукты СУБД не поддерживают предикат OVERLAPS. Если у вас есть, вы, скорее всего, будете использовать предикат OVERLAPS в хранимой процедуре, которая принимает даты, время и интервалы в качестве параметров типа данных CHARACTER. Параметры CHARACTER, используемые для хранения дат или временных интервалов, появятся в предикате OVERLAPS вместо буквальных значений, показанных в текущих примерах. Сейчас важно знать, что предикат OVERLAPS возвращает TRUE, если какая-либо часть второго временного интервала попадает в первый, и вы можете указать любой из двух временных интервалов как дату / время начала и дату / время окончания, или дата / время начала и продолжительность (или интервал).
Сейчас важно знать, что предикат OVERLAPS возвращает TRUE, если какая-либо часть второго временного интервала попадает в первый, и вы можете указать любой из двух временных интервалов как дату / время начала и дату / время окончания, или дата / время начала и продолжительность (или интервал).
Общие сведения о предложении GROUP BY и сгруппированных запросах
В совете 122 «Понимание того, как агрегатные функции в операторе SELECT создают единую строку результатов», вы узнали, как агрегатные функции SQL (AVG (), COUNT (), MAX () и MIN ()) суммируют данные из одна или несколько таблиц для получения единой строки результатов. Как и агрегатные функции, предложение GROUP BY суммирует данные.Однако вместо создания одной строки общего итога предложение GROUP BY создает несколько промежуточных итогов - по одному для каждой группы строк в таблице.
Например, если вы хотите узнать общую стоимость покупок, сделанных клиентами в течение предыдущего года, вы можете использовать агрегатную функцию SUM () в операторе SELECT, аналогичном
.
ВЫБЕРИТЕ СУММ (invoice_total) КАК "Общий объем продаж" ИЗ счетов-фактур ГДЕ invoice_date> = (GETDATE () - 365)
, в результате чего будет получена таблица результатов с единственной (общей) строкой, подобной:
Тотальная распродажа ----------- 47369
С другой стороны, если вы хотите разбить общий объем продаж по клиентам, добавьте предложение GROUP BY, такое как в запросе
ВЫБЕРИТЕ cust_ID, SUM (invoice_total) КАК "Общий объем продаж" ИЗ счетов-фактур ГДЕ invoice_date> = (GETDATE () - 365) ГРУППА ПО cust_ID
, чтобы указать СУБД создать таблицу результатов с промежуточным итогом объема продаж для каждого клиента, например:
cust_ID Общий объем продаж ------- ----------- 1 7378 5 7378 7 22654 8 1290 9 8669
Запрос, который включает предложение GROUP BY (например, показанный в текущем примере), называется сгруппированным запросом , потому что СУБД группирует (или суммирует) строк, выбранных из исходной таблицы (таблиц), как одну строку значений для каждой группы. Столбцы, названные в предложении GROUP BY (CUST_ID, в текущем примере), известны как столбцы группировки , потому что СУБД использует значения этих столбцов, чтобы решить, какие строки из исходной таблицы принадлежат к каким группам во промежуточной таблице.
Столбцы, названные в предложении GROUP BY (CUST_ID, в текущем примере), известны как столбцы группировки , потому что СУБД использует значения этих столбцов, чтобы решить, какие строки из исходной таблицы принадлежат к каким группам во промежуточной таблице.
После того, как СУБД организует промежуточную таблицу результатов в группы строк, в которых каждая строка в группе имеет одинаковые значения для всех группирующих столбцов, система вычисляет значение агрегатных функций (перечисленных в предложении SELECT) для строк в группа.Наконец, результаты агрегатной функции вместе со значениями других элементов, перечисленных в предложении SELECT, добавляются в окончательную таблицу результатов в виде одной строки для каждой группы.
Общие сведения об ограничениях на сгруппированные запросы
Сгруппированный запрос (определенный как любой оператор SELECT, включающий предложение GROUP BY) подлежит ограничениям как для столбцов, перечисленных в предложении GROUP BY, так и для выражений выходных значений, перечисленных в предложении SELECT.
Все столбцы группировки (столбцы, перечисленные в предложении GROUP BY) должны быть столбцами из таблиц, перечисленных в предложении FROM. Таким образом, вы не можете группировать строки на основе буквальных значений, результатов агрегатной функции или значения любого другого вычисляемого выражения.
Элементы в списке выбора сгруппированного запроса (ссылки на столбцы, агрегатные функции, литералы и другие выражения в предложении SELECT) должны иметь одно (скалярное) значение для каждой группы строк.Таким образом, каждый элемент в предложении SELECT сгруппированного запроса может быть:
- Группирующий столбец
- Литерал (константа)
- Агрегатная функция, которую СУБД применяет к строкам в группе для получения единственного значения, представляющего количество строк (COUNT (), COUNT (*)) или агрегированное значение столбца (MAX (), MIN (), AVG () ) для каждой группы
- Выражение, включающее комбинацию одного или нескольких из других (трех) допустимых элементов предложения SELECT
Поскольку сгруппированные запросы используются для суммирования (или промежуточных итогов) данных в группах (как определено группировкой столбцов, перечисленных в предложении GROUP BY), предложение SELECT сгруппированного запроса (почти) всегда будет включать по крайней мере один из столбцов группировки и одну или несколько агрегатных (столбцовых) функций. В конце концов, сгруппированный запрос, например
В конце концов, сгруппированный запрос, например
ВЫБЕРИТЕ cust_ID ИЗ счетов-фактур ГДЕ inv_date> = (GETDATE () - 365) ГРУППА ПО cust_ID
, который имеет только ссылки на столбцы в своем предложении SELECT, может быть выражен проще как оператор SELECT DISTINCT, например:
ВЫБРАТЬ РАЗЛИЧНЫЙ cust_ID ИЗ СЧЕТОВ ГДЕ inv_date> = (GETDATE () - 365)
И наоборот, если предложение SELECT имеет только агрегатные функции, такие как запрос
ВЫБЕРИТЕ СУММ (invoice_total) КАК "Общий объем продаж", AVG (invoice_total) AS 'Средний счет-фактура' ИЗ счетов-фактур ГДЕ invoice_date> = (GETDATE () - 365) ГРУППА ПО cust_ID
нельзя сказать, какая строка результатов запроса поступила из какой группы.Например, таблица результатов для текущего примера
Общий средний счет за продажу ----------- --------------- 7378 7378.000000 7378 7378.000000 22654 663,5000000 1290 258,000000 8669 4334.500000
дает вам общий объем продаж и средний счет для каждого клиента. Однако после просмотра данных в таблице результатов вы не можете определить, какие общие продажи и средний счет какому клиенту принадлежат.
Использование предложения GROUP BY для группировки строк на основе значения одного столбца
Как вы узнали из совета 88 «Использование оператора SELECT для отображения столбцов из строк в одной или нескольких таблицах», оператор SELECT позволяет отображать все строки в таблице, которые удовлетворяют критериям поиска, указанным в предложении WHERE запроса. (Если нет предложения WHERE, инструкция SELECT отобразит значения данных столбца из всех строк в таблице.) Чтобы разделить строки, возвращаемые оператором SELECT, на группы и отобразить только одну строку значений данных для каждой группы, выполните групповой запрос, добавив предложение GROUP BY к оператору SELECT.
При выполнении группового запроса СУБД выполняет следующие шаги:
- Создает промежуточную таблицу на основе декартова произведения (см.
 Совет 281, «Понимание декартовых произведений») таблиц, перечисленных в предложении FROM запроса.
Совет 281, «Понимание декартовых произведений») таблиц, перечисленных в предложении FROM запроса. - Применяет критерии поиска в предложении WHERE (если есть), удаляя все строки из промежуточной таблицы (созданной на шаге 1), для которых предложение WHERE оценивается как FALSE.
- Распределяет оставшиеся строки в промежуточной таблице в группы так, чтобы значение в столбце группировки (указанном в предложении GROUP BY) было одинаковым для каждой строки в группе.
- Вычисляет значение каждого элемента в предложении SELECT для каждой группы строк и создает одну строку результатов запроса для каждой группы.
- Если запрос включает предложение HAVING, применяет условие поиска к строкам в таблице результатов и удаляет те итоговые строки, для которых предложение HAVING оценивается как FALSE.
- Если оператор SELECT включает предложение DISTINCT (о котором вы узнали из совета 231 «Использование предложения DISTINCT для исключения дубликатов из набора строк»), удаляет все повторяющиеся строки из таблицы результатов.
- Если есть предложение ORDER BY, сортирует строки, оставшиеся в таблице RESULTS, в соответствии со столбцами, перечисленными в предложении ORDER BY. (Вы узнали о предложении ORDER BY в совете 95 «Использование предложения ORDER BY для определения порядка строк, возвращаемых оператором SELECT.")
Например, когда вы выполняете сгруппированный запрос, такой как
Состояние ВЫБРАТЬ, СЧЁТ (*) КАК 'Счетчик клиентов' ОТ клиентов ГРУППА ПО состоянию
СУБД выдаст таблицу результатов, показывающую количество клиентов, которые у вас есть в каждом штате. Поскольку предложение FROM имеет только одну таблицу (CUSTOMERS), промежуточная таблица, созданная на шаге 1, состоит из всех строк в таблице CUSTOMERS. Поскольку предложения WHERE нет, СУБД не удаляет строки из промежуточной таблицы.На шаге 3 СУБД сгруппирует строки промежуточной таблицы в группы, в которых значение группирующего столбца (STATE) будет одинаковым для каждой строки в каждой из групп.
Затем СУБД применяет функцию столбца COUNT (*) к каждой группе, чтобы создать строку таблицы результатов, которая содержит код состояния и количество клиентов (строк) в группе для каждой группы в таблице. Поскольку нет ни предложения HAVING, ни DISTINCT, СУБД не будет удалять какие-либо строки из таблицы результатов, аналогичные тем, которые показаны в нижней панели окна приложения MS-SQL Server, показанном на рисунке 270.1.
Рисунок 270.1: Запрос анализатора запросов MS-SQL Server и таблица результатов для сгруппированного по одному столбцу запроса
| Примечание | Поскольку предложение ORDER BY отсутствует, расположение строк в таблице результатов в порядке возрастания по столбцу группировки (STATE) является случайным. СУБД отобразит строки в таблице результатов в том порядке, в котором они расположены во временной таблице.Таким образом, не забудьте включить предложение ORDER BY, если вы хотите, чтобы СУБД сортировала строки в таблице результатов в порядке возрастания или убывания в соответствии со значениями в одном или нескольких столбцах. |
Использование предложения GROUP BY для группировки строк на основе нескольких столбцов
В совете 270 «Использование предложения GROUP BY для группировки строк на основе значения одного столбца» вы узнали, как использовать предложение GROUP BY для создания таблицы результатов со сводными (промежуточными) строками на основе группировки строк исходной таблицы на основе по значениям в одном столбце группировки.Оператор SELECT с одним столбцом в предложении GROUP BY является простейшей формой сгруппированного запроса. Если группы строк в таблице зависят от значений в нескольких столбцах, просто перечислите все столбцы, необходимые для определения групп в предложении GROUP BY запроса. Не существует верхнего предела количества столбцов, которые вы можете перечислить в предложении GROUP BY оператора SELECT, и единственное ограничение на группировку столбцов состоит в том, что каждый из них должен быть столбцом в одной из таблиц, перечисленных в предложении FROM запроса.Однако имейте в виду, что независимо от того, сколько столбцов вы перечисляете в предложении GROUP BY, стандартный SQL будет отображать только один уровень групповых промежуточных итогов в таблице результатов запроса.
Например, в совете 270 вы узнали, что можете использовать сгруппированный запрос
.
Состояние ВЫБРАТЬ, СЧЁТ (*) КАК 'Счетчик клиентов' ОТ клиентов ГРУППА ПО состоянию
, чтобы получить таблицу результатов, показывающую количество клиентов, которые у вас были в каждом штате.Если теперь вы хотите разбить количество клиентов штата по продавцам в каждом штате, вы можете выполнить запрос, аналогичный
.
ВЫБЕРИТЕ состояние, продавец, COUNT (*) AS 'Customer Count' ОТ клиентов ГРУППА ПО штатам, продавец
для создания таблицы результатов, например
государственный продавец Количество клиентов ----- ----------- -------------- АЗ 101 1 CA 101 3 LA 101 2 Привет 102 1 LA 102 2 NV 102 2 TX 102 1 АЗ 103 1 LA 103 1 НМ 103 1 TX 103 1
, который группирует клиентов по ПРОДАВЦАМ и в пределах ГОСУДАРСТВА.Обратите внимание, однако, что новый запрос производит только строку промежуточных итогов для каждой пары (СОСТОЯНИЕ, ПРОДАВЕЦ). Стандартный SQL не даст вам и промежуточный итог на основе SALESPERSON и промежуточный итог на основе STATE в той же таблице результатов, даже если вы указали оба столбца в предложении GROUP BY.
| Примечание | Поскольку стандартный SQL дает вам только один уровень промежуточных итогов для каждой уникальной комбинации всех столбцов группировки (столбцы, перечисленные в предложении GROUP BY), вам придется использовать программный SQL для передачи таблицы результатов в прикладную программу, которая может создавайте столько уровней промежуточных итогов, сколько хотите.Другой вариант - изменить порядок строк в таблице результатов с помощью предложения ORDER BY (что вы научитесь делать в совете 272, «Использование предложения ORDER BY для изменения порядка строк в группах, возвращаемых предложением GROUP BY») . Хотя предложение ORDER BY само по себе не создает промежуточных итогов, оно упрощает вам вручную вычисление второго уровня промежуточных итогов, группируя вместе строки с одинаковыми значениями столбцов. Последний способ получить несколько промежуточных итогов непосредственно из одного оператора SQL - использовать предложение MS-SQL Server Transact-SQL COMPUTE (о котором вы узнаете в совете 273 «Использование предложения MS-SQL Transact-SQL COMPUTE для отображения подробностей и общее количество строк в той же таблице результатов ").К сожалению, предложение COMPUTE не является частью стандарта SQL-92, и вы сможете использовать его только в СУБД MS-SQL Server. |
Использование предложения ORDER BY для изменения порядка строк в группах, возвращаемых предложением GROUP BY
В совете 95 «Использование предложения ORDER BY для указания порядка строк, возвращаемых оператором SELECT», вы узнали, как использовать предложение ORDER BY для сортировки строк таблицы результатов, возвращаемых несгруппированным запросом.Предложение ORDER BY в сгруппированном запросе работает как предложение ORDERED BY в несгруппированном запросе. Например, чтобы отсортировать таблицу результатов из сгруппированного запроса
Состояние ВЫБРАТЬ, СЧЁТ (*) КАК 'Счетчик клиентов' ОТ клиентов ГРУППА ПО состоянию
в порядке убывания количества клиентов в каждом состоянии, перепишите оператор SELECT, включив в него предложение ORDER BY:
Состояние ВЫБРАТЬ, СЧЁТ (*) КАК 'Счетчик клиентов' ОТ клиентов ГРУППА ПО состоянию ЗАКАЗАТЬ ПО «Счету клиентов» DESC
Обратите внимание, что вы не ограничены сортировкой результатов запроса на основе любого из столбцов, перечисленных в предложении GROUP BY.Как и во всех запросах, столбцы, перечисленные в предложении ORDER BY, ограничены только столбцами или заголовками, указанными в предложении SELECT запроса. Следовательно, каждое из следующих предложений ORDER BY допустимо для оператора SELECT в текущем примере:
ЗАКАЗАТЬ ПО состоянию ЗАКАЗАТЬ по состоянию «Количество клиентов» ЗАКАЗАТЬ ПО состоянию "Количество клиентов" ЗАКАЗАТЬ ПО «Счету клиентов»
Как упоминалось в совете 271 «Использование предложения GROUP BY для группировки строк на основе нескольких столбцов», вы можете использовать предложение ORDER BY, чтобы упростить ручное вычисление второго (или третьего, или четвертого, или так далее) уровня. промежуточных итогов при просмотре таблицы результатов сгруппированного запроса с несколькими столбцами группировки.Например, расположение строк в таблице результатов из сгруппированного запроса (STATE, SALESPERSON) в совете 271 позволяет легко вручную подсчитать количество клиентов для каждого продавца, даже если запрос предоставляет только промежуточный итог для каждого (STATE, ПРОДАВЕЦ) пара. Просто проведите горизонтальную линию поперек страницы при каждом изменении ПРОДАВЦА и сложите значения CUSTOMER COUNT в блок (группу) строк.
И наоборот, если вы хотите вычислить промежуточные итоги для количества клиентов по штатам, задача усложняется, потому что идентичные сокращения состояний не сгруппированы вместе в таблице результатов.Однако, если вы измените предложение ORDER BY в сгруппированном запросе следующим образом
ВЫБЕРИТЕ состояние, продавец, COUNT (*) AS 'Customer Count' ОТ клиентов ГРУППА ПО штатам, продавец Состояние ORDER BY, «Количество клиентов»
вы можете создать таблицу результатов, аналогичную
государственный продавец Количество клиентов ----- ----------- -------------- АЗ 101 1 АЗ 103 1 CA 101 3 Привет 102 1 LA 101 2 LA 102 2 LA 103 1 НМ 103 1 NV 102 2 TX 102 1 TX 103 1
, который упрощает ручное подведение итогов количества клиентов штата, перечисляя количество клиентов группы для идентичных кодов состояния рядом друг с другом.
Использование предложения MS SQL Transact SQL COMPUTE для отображения подробных и итоговых строк в одной и той же таблице результатов
Предложение MS-SQL Server Transact-SQL COMPUTE позволяет выполнять агрегатные (столбчатые) функции (SUM (), AVG (), MIN (), MAX (), COUNT ()) для строк в таблице результатов. Таким образом, вы можете использовать предложение COMPUTE в операторе SELECT для создания таблицы результатов с как подробными, так и сводными данными.
Например, предложение COMPUTE в операторе SELECT
ВЫБРАТЬ * ИЗ клиентов ГДЕ состояние В ('CA', 'NV')
ВЫЧИСЛИТЬ СУММ (всего_покупок), СРЕДНЕГО (всего_покупок,
COUNT (cust_ID)
создаст таблицу результатов, аналогичную
.
cust_id cust_name государственный продавец total_purchases ------- ------------- ----- ----------- -------------- - 1 Клиент CA 1 CA 101 78252.0000 2 CA Клиент 2 CA 101 45852.0000 6 NV Заказчик 1 NV 102 12589.0000 7 CA Клиент 3 CA 101 75489.0000 12 NV Заказчик 2 NV 102 56789.0000 сумма =============== 268971,0000 в среднем =============== 53794,2000 cnt ========== 5
, который содержит ряды подробной информации о клиентах компании в Калифорнии и Неваде и заканчивается итоговыми строками, показывающими количество клиентов в отчете вместе с общим итоговым итогом и средними продажами для группы в целом.
| Примечание | Строго говоря, оператор SELECT с предложением COMPUTE нарушает основное правило реляционных запросов, поскольку его результат не является таблицей. Поскольку MS-SQL Sever добавляет две строки заголовка и итоговую строку для каждой агрегатной функции в предложении COMPUTE, запрос возвращает комбинацию строк разных типов. |
Хотя это чрезвычайно полезно для подсчета строк и суммирования числовых значений в таблице результатов, использование предложения COMPUTE BY в операторе SELECT ограничено следующими правилами:
- В предложении COMPUTE можно использовать только столбцы из предложения SELECT.
- Агрегатные функции в предложении COMPUTE нельзя ограничить как DISTINCT.
- Предложение COMPUTE нельзя использовать в инструкции SELECT INTO.
- В предложении COMPUTE можно использовать только имена столбцов (но не заголовки столбцов).
Использование предложений COMPUTE и COMPUTE BY в MS SQL Transact SQL для отображения многоуровневых промежуточных итогов
В совете 271 «Использование предложения GROUP BY для группировки строк на основе нескольких столбцов» вы узнали, как использовать сгруппированный запрос (оператор SELECT с предложением GROUP BY) для группировки данных исходной таблицы и отображения их в таблице результатов. в виде одной итоговой строки для каждой группы.Вы также узнали, что сгруппированный запрос отображает только один уровень промежуточных итогов. Следовательно, вы не можете использовать стандартный сгруппированный запрос для отображения промежуточных итогов групп и общих итогов в одной таблице результатов. Однако, если вы используете COMPUTE BY и предложение COMPUTE в одном несгруппированном запросе , вы можете сгенерировать таблицу результатов, которая имеет как промежуточные, так и общие итоги. (Другими словами, вы можете сгенерировать многоуровневые промежуточные итоги, добавив предложение COMPUTE BY и предложение COMPUTE к оператору SELECT, в котором нет предложения GROUP BY.)
Например, предложения COMPUTE BY и COMPUTE в запросе
ВЫБЕРИТЕ состояние, продавца, всего_покупок ОТ клиентов
ГДЕ состояние IN ('LA', 'CA')
ЗАКАЗАТЬ ПО штату, продавцу
ВЫЧИСЛИТЬ СУММ (total_purchases) ПО штату, продавцу
ВЫЧИСЛИТЬ СУММ (всего_покупок)
отобразит промежуточные и общие итоги в таблице результатов, аналогичной:
государственный продавец total_purchases ----- ----------- --------------- CA 101 78252.0000 CA 101 45852.0000 CA 101 75489.0000 сумма =============== 199593.0000 LA 101 74815.0000 LA 101 15823.0000 сумма ===============.0000 LA 102 96385.0000 LA 102 85247.0000 сумма =============== 181632,0000 LA 103 45612.0000 сумма =============== 45612.0000 сумма =============== 517475.0000В дополнение к ограничениям предложения COMPUTE (о которых вы узнали из совета 273 «Использование предложения MS-SQL Transact-SQL COMPUTE для отображения подробных и общих строк в одной и той же таблице результатов»), запрос с COMPUTE BY также должен придерживаться следующих правил:
- Чтобы включить предложение COMPUTE BY, оператор SELECT должен иметь предложение ORDER BY.
- Столбцы, перечисленные в предложении COMPUTE BY, должны либо соответствовать, либо быть подмножеством столбцов, перечисленных в предложении ORDER BY. Более того, столбцы в двух предложениях (ORDER BY и COMPUTE BY) должны быть в одном порядке, слева направо, должны начинаться с одного и того же столбца и не должны пропускать какие-либо столбцы.
- Предложение COMPUTE BY не может содержать никаких имен заголовков - только имена столбцов.
Последнее ограничение «без заголовков» может означать, что невозможно выполнить запрос, который использует предложение COMPUTE BY для «суммирования» промежуточных итогов агрегатной функции (ов) в сгруппированном запросе, таком как:
ВЫБЕРИТЕ состояние, продавец, SUM (total_purchases) AS 'Tot_Purchases " ОТ клиентов ГРУППА ПО штатам, продавец ЗАКАЗАТЬ ПО штату, продавцу
В конце концов, TOT_PURCHASES в таблице результатов - это заголовок, а не имя столбца.Таким образом, столбец с промежуточным итогом покупок для каждой пары (STATE, SALESPERSON) не подходит для использования в предложении COMPUTE BY.
Однако, если вы выполните оператор CREATE VIEW, например
СОЗДАТЬ ПРОСМОТР vw_state_emp_tot_purchases AS ВЫБЕРИТЕ состояние, продавец, SUM (total_purchases) AS 'Tot_Purchases)
, который создает виртуальную таблицу , которая использует заголовок агрегатной функции (TOT_PURCHASES в текущем примере) в качестве столбца, вы можете использовать предложение COMPUTE BY для подведения промежуточных итогов агрегированного столбца.В текущем примере TOT_PURCHASES - это столбец в представлении VW_STATE_EMP_TOT_PURCHASES. Следовательно, если вы ссылаетесь на представление как на (виртуальную) таблицу в предложении FROM инструкции SELECT, вы можете использовать предложение COMPUTE BY в запросе, таком как
ВЫБРАТЬ состояние, продавец, tot_purchases ОТ vw_state_emp_tot_purchases ЗАКАЗАТЬ ПО штату, продавцу ВЫЧИСЛИТЬ СУММ (total_purchases) ПО состоянию
для отображения промежуточных итогов продаж для каждого ПРОДАВЦА по ГОСУДАРСТВУ (совокупные промежуточные итоги из сгруппированного запроса), а также «итоговых сумм» и отображения продаж по СОСТОЯНИЮ в той же таблице результатов.
Понимание того, как значения NULL обрабатываются предложением GROUP BY
Проблема, которую создают значения NULL, когда они встречаются в одном (или нескольких) столбцах группировки в сгруппированном запросе, аналогична проблеме, которую эти значения создают для агрегатных функций и критериев поиска. Поскольку группа определяется как набор строк, в которых составное значение столбцов группировки одинаково, какая группа должна включать строку, в которой значение одного или нескольких столбцов, определяющих группу, неизвестно (NULL)?
Если бы СУБД следовала правилу, используемому для критериев поиска в предложении WHERE, то GROUP BY создала бы отдельную группу для каждой строки со значением NULL в любом из столбцов группировки.В конце концов, результат проверки на равенство двух значений NULL в предложении WHERE всегда равен FALSE, потому что NULL не равно NULL в соответствии со стандартом SQL. Следовательно, если строка имеет группирующий столбец со значением NULL, ее нельзя поместить в ту же группу с другой строкой, которая имеет значение NULL в том же столбце группировки, потому что все строки в одной группе должны иметь совпадающие значения группирующего столбца (и NULL <> NULL)
Поскольку они обнаружили, что создание отдельной группы для каждой строки с NULL в столбце группирования сбивает с толку и не имеет полезного значения, разработчики SQL написали стандарт SQL, в котором значения NULL считаются равными для целей предложения GROUP BY.Следовательно, если две строки имеют значения NULL в одних и тех же столбцах группировки и совпадают значения в оставшихся столбцах группировки, отличные от NULL, СУБД сгруппирует строки вместе.
Например, сгруппированный запрос
ВЫБЕРИТЕ состояние, продавец, SUM (amount_purchased) КАК "Всего покупок" ОТ клиентов ГРУППА ПО штатам, продавец ЗАКАЗАТЬ ПО штату, продавцу
отобразит таблицу результатов, аналогичную
.
государственный продавец Всего закупок ----- ----------- --------------- НУЛЬ НУЛЬ 61438.0000 NULL 101 196156.0000 AZ NULL 75815.0000 AZ 103 36958.0000 CA 101 78252.0000 LA NULL 181632.0000
для КЛИЕНТОВ, которые содержат следующие строки:
государственный продавец amount_purchased ----- ----------- ---------------- NULL NULL 45612.0000 NULL NULL 15826.0000 ПУСТО 101 45852.0000 ПУСТО 101 74815.0000 ПУСТО 101 75489.0000 АЗ НОЛЬ 75815.0000 AZ 103 36958.0000 CA 101 78252.0000 LA NULL 96385.0000 LA NULL 85247.0000
Использование предложения HAVING для фильтрации строк, включенных в таблицу результатов сгруппированного запроса
Предложение HAVING, как и предложение WHERE, о котором вы узнали в совете 91 «Использование оператора SELECT с предложением WHERE для выбора строк на основе значений столбца», используется для фильтрации строк с атрибутами (значениями столбцов), которые не удовлетворяют критерии поиска пункта.При выполнении запроса СУБД использует критерии поиска в WHERE в качестве фильтра, просматривая таблицу, указанную в предложении FROM запроса (или декартово произведение таблиц, если предложение FROM имеет несколько таблиц) по одной строке за раз. . Система сохраняет для дальнейшей обработки только те строки, значения столбцов которых соответствуют условиям поиска в предложении WHERE. После того, как предложение WHERE (если оно есть) отсеивает нежелательные строки, СУБД использует предложение HAVING в качестве фильтра для удаления групп строк (вместоотдельные строки), совокупные или отдельные значения столбцов которых не удовлетворяют условию поиска в предложении HAVING.
Например, предложение WHERE в запросе
ВЫБЕРИТЕ RTRIM (first_name) + '' + last_name AS 'Имя сотрудника', СУММ (amt_purchased) КАК "Общий объем продаж" ОТ клиентов, сотрудников ГДЕ customers.salesperson = employee.emp_ID ГРУППА ПО RTRIM (имя) + '' + фамилия ИМЕЕТ СУММ (amt_purchased)> 250000 ЗАКАЗАТЬ ПО «ОБЩЕМУ ПРОДАЖУ»
сообщает СУБД, что необходимо просмотреть промежуточную таблицу, созданную из декартова произведения таблиц CUSTOMERS и EMPLOYEES, по одной строке за раз и удалить все строки, в которых значение в столбце EMP_ID не равно значению в столбце SALESPERSON.
Затем СУБД группирует оставшиеся строки по имени сотрудника (как указано в предложении GROUP BY). Затем СУБД проверяет каждую группу строк, используя критерии поиска в предложении HAVING. В текущем примере система вычисляет сумму столбца AMT_PURCHASED для каждой группы строк и удаляет строки в любой группе, где агрегатная функция (SUM (AMT_PURCHASED)) возвращает значение, равное или меньшее 250 000.
Хотя критерии поиска в предложении HAVING могут проверять значения отдельных столбцов, а также результаты агрегированных функций, более эффективно помещать тесты значений отдельных столбцов в предложение WHERE запроса (vs.его предложение HAVING). Например, запрос
ВЫБЕРИТЕ emp_ID, RTRIM (first_name) + '' + last_name КАК "Имя сотрудника", СУММ (amt_purchased) КАК "Общий объем продаж" ОТ клиентов, сотрудников ГДЕ customers.salesperson = employee.emp_ID ГРУППА ПО RTRIM (имя) + '' + фамилия ИМЕЕТ (СУММ (amt_purchased) <250000) И (emp_ID> = 102) ЗАКАЗАТЬ ПО «ОБЩЕМУ ПРОДАЖУ»
, который проверяет значение столбца EMP_ID в предложении HAVING для исключения любых сотрудников с общим объемом продаж, равным или превышающим 250 000, которые имеют значение EMP_ID менее 102 из окончательной таблицы результатов, менее эффективен, чем запрос:
ВЫБЕРИТЕ emp_ID, RTRIM (first_name) + '' + last_name КАК "Имя сотрудника", СУММ (amt_purchased) КАК "Общий объем продаж" ОТ клиентов, сотрудников ГДЕ (покупатели.продавец = сотрудники.emp_ID) И (emp_ID> = 102) ГРУППА ПО RTRIM (имя) + '' + фамилия ИМЕЕТ (SUM (amt_purchased) <250000) ЗАКАЗАТЬ ПО «ОБЩЕМУ ПРОДАЖУ»
, который проверяет значение EMP_ID в предложении WHERE (для получения той же таблицы результатов).
В первом запросе (с проверкой столбца EMP_ID в предложении HAVING) СУБД вычислит сумму столбца AMT_PURCHASED для нескольких групп сотрудников (тех, у которых значения столбца EMP_ID в диапазоне 001-101), чтобы исключить только эти строки в этих группах, когда система проверяет значение EMP_ID группы.Второй запрос позволяет избежать объединения строк со значениями столбца EMP_ID менее 102 в группы и вычисления общих продаж для этих групп путем исключения строк из промежуточной таблицы результатов до того, как СУБД объединит строки в группы и применит агрегатную функцию (SUM ()) в HAVING для каждой группы.
Понимание разницы между предложением WHERE и предложением HAVING
СУБД использует критерии поиска в предложениях WHERE и HAVING для фильтрации нежелательных строк из промежуточных таблиц, созданных при выполнении запроса.Однако каждое предложение влияет на другой набор строк. В то время как предложение WHERE фильтрует отдельные строки в декартовом произведении таблиц, перечисленных в предложении FROM оператора SELECT, предложение HAVING экранирует нежелательные группы (строк) из групп, созданных оператором GROUP BY запроса. Таким образом, вы можете использовать предложение WHERE в любом операторе SELECT, в то время как предложение HAVING следует использовать только в сгруппированном запросе (оператор SELECT с предложением GROUP BY).
Если вы используете предложение HAVING без предложения GROUP BY, СУБД рассматривает все строки в исходной таблице как единую группу.Таким образом, агрегатные функции в предложении HAVING применяются к одной и только одной группе (всем строкам во входной таблице), чтобы определить, должны ли строки группы быть включены в результаты запроса или исключены из них.
Например, запрос
ВЫБРАТЬ СУММ (amt_purchased) ОТ клиентов ИМЕЕТ СУММ (amt_purchased) <250000
поместит сумму значений в столбце AMT_PURCHASED в таблицу результатов, только если общая сумма столбца AMT_PURCHASED для всей таблицы CUSTOMERS меньше 250 000.
На практике вы почти никогда не увидите предложение HAVING в операторе SELECT без предложения GROUP BY. В конце концов, какой смысл отображать агрегированное значение для столбца таблицы, только если оно удовлетворяет еще одному критерию поиска? Более того, если вы попытаетесь ограничить агрегирование подмножеством строк во входной таблице, например «покажите мне общие покупки для любого клиента из Калифорнии, Невады или Луизианы, у которого общая сумма покупок составляет менее 250 000 долларов США», изменив запрос в текущий пример на
ВЫБРАТЬ СУММ (amt_purchased) ОТ клиентов
ИМЕЕТ (SUM (amt_purchased) <250000)
И (состояние IN ('CA', 'NV', 'LA'))
Тогда СУБД прервет выполнение запроса и отобразит сообщение об ошибке, подобное:
Сервер: Msg 8119, уровень 16, состояние 1, строка 1 Колонка "клиенты".состояние 'недопустимо в предложении имеющего потому что он не содержится в агрегатной функции и предложения GROUP BY нет.
В результате вы бы переписали оператор SELECT (правильно) как сгруппированный запрос
Состояние ВЫБРАТЬ, СУММ (amt_purchased) ОТ клиентов
ГДЕ СОСТОЯНИЕ В ('CA', 'NV', 'LA')
ГРУППА ПО состоянию
ИМЕЕТ СУММ (amt_purchased) <250000
, в котором предложение HAVING следует сразу за предложением GROUP BY.
Сейчас важно знать, что предложение WHERE полезно как в сгруппированных, так и в несгруппированных запросах, в то время как предложение HAVING должно появляться только сразу после предложения GROUP BY в сгруппированном запросе.
Общие сведения о правилах SQL для использования предложения HAVING в сгруппированном запросе
Как вы узнали из совета 276 «Использование предложения HAVING для фильтрации строк, включенных в таблицу результатов сгруппированного запроса» и совета 277 «Понимание различий между предложением WHERE и предложением HAVING», вы можете использовать предложение WHERE. или предложение HAVING для исключения строк или включения строк в результаты запроса.Поскольку СУБД использует критерии поиска в предложении WHERE для фильтрации одной строки данных за раз, выражения в предложении WHERE должны быть вычислимыми для отдельных строк. Между тем, выражение (я) в критериях поиска в предложении HAVING должно оцениваться как одно значение для группы строк. Таким образом, условия поиска в предложении WHERE состоят из выражений, в которых используются ссылки на столбцы и литеральные значения (константы). С другой стороны, условия поиска в предложении HAVING обычно состоят из выражений с одной или несколькими агрегатными функциями (столбцами) (такими как COUNT (), COUNT (*), MIN (), MAX (), AVG () или СУММ ()).
При выполнении группового запроса с предложением HAVING СУБД выполняет следующие шаги:
- Создает промежуточную таблицу из декартова произведения таблиц, перечисленных в предложении FROM оператора SELECT. Если в предложении FROM есть только одна таблица, тогда промежуточная таблица будет копией одной исходной таблицы.
- Если есть предложение WHERE, применяет свои условия поиска, чтобы отфильтровать нежелательные строки из промежуточной таблицы.
- Располагает строки промежуточной таблицы в группы строк, в которых все столбцы группировки имеют одинаковые значения.
- Применяет каждое условие поиска в предложении HAVING к каждой группе строк. Если группа строк не удовлетворяет одному или нескольким критериям поиска, удаляет строки группы из промежуточной таблицы.
- Вычисляет значение каждого элемента в предложении SELECT запроса и создает одну (сводную) строку для каждой группы строк. Если элемент предложения SELECT ссылается на столбец, использует значение столбца из любой строки в группе в итоговой строке.Если элемент предложения SELECT является агрегатной функцией, вычисляет значение функции для группы суммируемых строк и добавляет это значение в итоговую строку группы.
- Если запрос включает ключевое слово DISTINCT (как в SELECT DISTINCT), удаляет все повторяющиеся строки из таблицы результатов.
- Если есть предложение ORDER BY, сортирует таблицу результатов по значениям в столбцах, перечисленных в предложении ORDER BY.
Общие сведения о том, как SQL обрабатывает нулевой результат из предложения HAVING
Предложение HAVING, как и предложение WHERE, может иметь одно из трех значений: TRUE, FALSE или NULL.Если предложение HAVING оценивается как TRUE для группы строк, СУБД использует значения в строках группы для создания итоговой строки в таблице результатов. И наоборот, если предложение HAVING оценивается как FALSE или NULL для группы строк, СУБД не суммирует строки группы в таблице результатов. Таким образом, СУБД обрабатывает предложение HAVING с NULL-значением так же, как и предложение WHERE с NULL-значением - она пропускает строки, которые привели к значению NULL из таблицы результатов.
Имейте в виду, что значения NULL в столбцах группы не всегда приводят к тому, что условие поиска в предложении HAVING оценивает NULL.Например, запрос
Состояние ВЫБРАТЬ, СЧЁТ (*) КАК 'Счетчик клиентов', (COUNT (*) - COUNT (amt_purchased)) КАК 'NULL Sales Count' SUM (amt_purchased) КАК "Продажи" ОТ клиентов ГРУППА ПО состоянию ИМЕЕТ СУММ (amt_purchased) <50000
создаст таблицу результатов, аналогичную той, которая показана на панели результатов в нижней половине окна анализатора запросов MS-SQL Server, показанном на рис. 279.1, даже если три из четырех значений AMT_PURCHASED имеют значение NULL в группе строк клиентов из Калифорнии.
Рисунок 279.1: Запрос анализатора запросов MS-SQL Server и таблица результатов для сгруппированного запроса с предложением HAVING
Как вы узнали из совета 119 «Использование агрегатной функции SUM () для нахождения суммы значений в столбце», агрегатная функция SUM () пропускает NULL при суммировании значений столбца. Следовательно, в текущем примере условие поиска в предложении HAVING оценивается как TRUE для клиентов из Калифорнии, поскольку агрегат SUM () игнорирует три значения NULL AMT_PURCHASED в группе и возвращает агрегированный результат, отличный от NULL (25000).
С другой стороны, если все значений в столбце AMT_PURCHASED равны NULL для группы строк (например, для клиентов из Калифорнии), функция SUM () вернет NULL. В результате предложение HAVING будет оцениваться как NULL, а оператор SELECT не будет суммировать строки группы в своей таблице результатов. В текущем примере, если все строки клиентов из Калифорнии имеют значение NULL в столбце AMT_PURCHASED, оператор SELECT создаст таблицу результатов, аналогичную
.
State Customer Count NULL Количество продаж Количество продаж ----- -------------- ---------------- ---------- А2 2 0 33399.0000
, в котором не упоминаются клиенты из Калифорнии.
Однако, если вы измените пример запроса, добавив условие поиска IS NULL, как показано ниже:
Состояние ВЫБРАТЬ, СЧЁТ (*) КАК 'Счетчик клиентов', (COUNT (*) - COUNT (amt_purchased)) КАК 'NULL Sales Count' SUM (amt_purchased) КАК "Продажи" ОТ клиентов ГРУППА ПО состоянию ИМЕЕТ (SUM (amt_purchased) <50000) ИЛИ (СУММ (amt_purchased) НУЛЬ)
предложение HAVING будет иметь значение TRUE для клиентов из Калифорнии (, потому что агрегатная функция SUM () возвращает значение NULL), а оператор SELECT отобразит таблицу результатов, подобную следующей:
State Customer Count NULL Счетчик продаж Продажи ----- -------------- ---------------- ---------- АЗ 2 0 33394.0000 CA 4 4 NULL
Сейчас важно понять, что любая группа строк, для которой предложение HAVING оценивается как NULL (или FALSE), будет исключена из таблицы результатов сгруппированного запроса.
Частей предложения, подлежащего и предиката
Понимание подлежащего и предиката - ключ к хорошему написанию предложений. Подлежащее полного предложения - это то, о чем или о чем идет речь в предложении, а предикат говорит об этом предмете.
Собака убежала.
Собака является субъектом предложения, потому что предложение что-то говорит об этой собаке. И о чем это говорит? Там написано, что собака сбежала. Итак, в этом примере субъектом является «собака», а предикат - «побежал».
Собака побежала за кошкой.
Здесь у нас есть более подробная информация, но тема все еще «собака». Как мы можем узнать, что речь идет о «собаке», а не о «кошке», если предложение, кажется, касается обоих животных?
Чтобы определить подлежащее в предложении, сначала найдите глагол, а затем спросите «кто?» или что?" В этом предложении глагол «побежал».Если мы спросим: «Кто сбежал?» ответ: «собака убежала». Вот как мы узнаем, что «собака» является предметом предложения.
О чем идет речь в следующем предложении:
Вчера после обеда студенты жаловались на короткие перемены.
В предложении говорится о нескольких вещах: вчера, обед, студенты и перемены. Как мы можем узнать, какой из них является предметом приговора? Сначала мы находим глагол: «жаловались». Затем мы спрашиваем: «Кто жаловался?» И сразу же мы понимаем, что предметом предложения являются «студенты».Предикат всегда включает глагол и что-то говорит о подлежащем; в этом примере мы видим, что студенты «жаловались на короткие перемены».
«Вас понял»
В некоторых предложениях не так-то просто найти предмет. Вот пример предложения без подлежащего:
Сядьте в этот стул.
Мы видим глагол «иди, сядь», но кто это делает? Единственное существительное - «стул», но, конечно, стул не собирается «иди, сядь!»
В этом предложении говорящий дает прямую команду другому человеку и мог бы сказать: «Иди и сядь на этот стул.«Правило, которое следует запомнить для предложения, которое представляет собой команду, состоит в том, что если субъект не назван, мы можем предположить, что субъектом является« вы ».
«Здесь» нет предмета
Еще один пример, на который следует обратить внимание, - это предложение, которое начинается с «там» и имеет форму глагола «быть». Хотя слово «там» стоит в начале предложения, рядом с глаголом, оно не является подлежащим. Посмотрим, сможете ли вы найти подлежащее и сказуемое в этом предложении:
На столе было три разных десерта.
Сначала найдите глагол: «были устроены». Затем спросите: «Кто или что устроили?» Ответ - «три разных десерта», что и есть правильная тема.
Простой субъект и простой предикат
Субъект предложения включает существительное или местоимение вместе со всеми словами, которые его изменяют или описывают. Простое подлежащее - это существительное или местоимение само по себе.
Голубая рубашка с ярким рисунком была ее любимым верхом.
В этом предложении «рубашка» является простым подлежащим, и все описательные слова говорят нам больше об этой рубашке.Предметом является «рубашка» и все ее модификаторы (голубая рубашка с цветным рисунком), а простым предметом является просто «рубашка».
Предикат предложения основан на простом предикате, которым является глагол. Все остальные слова в сказуемом больше говорят о подлежащем, а некоторые слова могут изменять глагол. В приведенном выше примере слово «был» - это глагол, и поэтому это простое сказуемое.
Составной субъект и составной предикат
Иногда в предложении есть составное подлежащее , когда в подлежащем два или более существительных :
Бобби и его друзья выбежали на улицу поиграть в баскетбол.
Глагол «побежал», и мы спрашиваем: «кто сбежал?» Ответ - «Бобби и его друзья», которые составляют предмет.
Составное сказуемое включает два или более глагола , относящихся к подлежащему:
Маленькая девочка взяла свою куклу и забралась в кровать.
Глаголы «поднял» и «взобрался». Мы спрашиваем: «Кто взял? кто поднялся? » Ответ один и тот же для обоих глаголов: «маленькая девочка».
Как писать лучшие предложения
Как знание темы и предиката может помочь вам стать лучшим писателем? Взгляните на следующие примеры и посмотрите, сможете ли вы найти подлежащие и предикаты.
В кино с друзьями ели попкорн с большим количеством масла и соли.
Быстро приближающийся поезд по шатким путям, дрожащий на повороте.
В обоих примерах есть действие, и оба они что-то говорят об существительных, но ни один из них не является действительным предложением, потому что ни один из них не имеет подлежащего и предиката. Давайте перепишем примеры и составим полные предложения:
1. Пока мы были в кино, мы с друзьями ели попкорн с большим количеством масла и соли.
Теперь мы можем найти глагол «ели» и спросить «кто?» Ответ - составной предмет: «мои друзья и я».
2. Быстро приближающийся поезд свернул по шатким путям, дрожа на повороте.
OR
Быстро приближающийся поезд содрогнулся, заходя за поворот на шатких путях.
Обе версии этого примера теперь включают глагол «свернул» или «задрожал» с одним и тем же предметом «поезд» в каждой версии.
Подлежащее и глагольное соглашение
Еще один важный момент, о котором следует помнить, это то, что подлежащее и сказуемое должны «согласовываться» в числе:
Человек, держащий коробки, следующий в очереди.
Несмотря на то, что слово «коробки» стоит во множественном числе, глагол в единственном числе, потому что субъектом предложения является существительное в единственном числе «человек». Помните, что при принятии решения о том, следует ли использовать глагол в единственном или множественном числе, учитывайте только подлежащее!
| Номер | Описание |
|---|---|
| BMC184400 | Правило № 3018: По возможности следует избегать гибридных соединений.Рассмотрите возможность изменения запроса или добавления OPTIMIZE FOR N ROWS. Может потребоваться обновление статистики или изменение структуры запроса. Пояснение: Информационное сообщение. Действия пользователя: Рассмотрите возможность обновления статистики или реструктуризации запроса. |
| BMC184402 | Правило № 3020: доступ к таблице будет осуществляться с помощью сканирования табличного пространства. Каждая страница в табличном пространстве будет сканироваться DB2, чтобы дать ответ. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184403 | Правило № 3021: Совет. Если этот оператор не извлекает большинство строк в этой таблице, рассмотрите возможность добавления индекса для наиболее ограниченных столбцов в предикате. Изучите столбцы в индексе этой таблицы и, если возможно, добавьте их в предикат. Объяснение: Производительность можно повысить, если оптимизатор использует индекс. Действия пользователя: Добавьте столбцы из существующего индекса в предикат или добавьте индекс для столбцов в существующем предикате. |
| BMC184404 | Правило № 3022: Доступ к таблице будет осуществляться с помощью индекса. DB2 сначала обратится к индексу, чтобы квалифицировать строки. Объяснение: DB2 может полностью избежать чтения страниц данных, если все необходимые данные существуют в индексе. Действия пользователя: Избегайте индексирования столбцов с низкой мощностью или неравномерным распределением. Также избегайте индексов в столбцах, которые часто обновляются, потому что это требует обработки удаления и вставки. |
| BMC184406 | Правило № 3024: доступ к таблице будет осуществляться с использованием доступа к индексу с однократной выборкой. Explanation: Доступ к индексу One-Fetch - это наиболее эффективный путь доступа, который можно выбрать, если вы извлекаете только одну строку, используете функцию MIN или MAX и ведущие столбцы составного индекса. имеют равные предикаты.Доступ к индексу One-Fetch нельзя использовать, если существует более одной таблицы, указаны дополнительные функции столбцов или если указано предложение GROUP BY. Действия пользователя: В DB2 V6 и ниже рекомендуется иметь возрастающий индекс для функции MIN и убывающий индекс для функции MAX. В DB2 V7 доступ к индексу One-Fetch доступен независимо от того, идет ли индекс по возрастанию или по убыванию. Для DB2 V7 просмотрите восходящие и нисходящие индексы, созданные для поддержки функций столбцов MIN и MAX, на предмет возможных ненужных накладных расходов. |
| BMC184408 | Правило № 3026: Доступ к таблице будет осуществляться с помощью сканирования индекса. Соответствующий предикат содержит ключевое слово IN для одного из предикатов. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184410 | Правило № 3028: Доступ к таблице будет осуществляться с помощью нескольких сканирований индекса (ACCESSTYP = M) относительно новой таблицы. Объяснение: Для доступа к одной таблице будет использоваться несколько индексов. ACCESSTYPE M отражает начало пути доступа с несколькими индексами. Действия пользователя: Доступ с одним индексом может быть более эффективным. Сравните индексы этого приложения с предикатами. |
| BMC184412 | Правило № 3030: Доступ к таблице будет осуществляться с помощью сканирования нескольких индексов (ACCESSTYPE = MX) по имени доступа к индексу: Объяснение: Для доступа к одной таблице будет использоваться несколько индексов. ACCESSTYPE MX означает, что индексы должны сканироваться на предмет последующего объединения или пересечения. Действия пользователя: Доступ с одним индексом может быть более эффективным. Сравните индексы этого приложения с предикатами. |
| BMC184414 | Правило № 3032: Доступ к таблице будет осуществляться через пересечение нескольких индексов (ACCESSTYPE = MI). Объяснение: Для доступа к одной таблице будет использоваться несколько индексов. ACCESSTYPE MI отражает выполнение пересечения (AND). Действия пользователя: Доступ с одним индексом может быть более эффективным. Сравните индексы этого приложения с предикатами. |
| BMC184416 | Правило № 3034: Доступ к таблице будет осуществляться путем объединения нескольких индексов (ACCESSTYPE = MU). Объяснение: Для доступа к одной таблице будет использоваться несколько индексов. ACCESSTYPE MU отражает выполнение объединения (OR). Действия пользователя: Доступ с одним индексом может быть более эффективным. Сравните индексы этого приложения с предикатами. |
| BMC184418 | Правило № 3036: доступ к индексу будет осуществляться с соответствующими столбцами. Столбцы: Объяснение: Данные можно найти для определенной строки с помощью нескольких операций ввода-вывода. Если для выполнения инструкции SELECT доступ к страницам данных не требуется, процесс называется сканированием индекса соответствия без ссылки на данные. Действия пользователя: Нет. |
| BMC184419 | Правило № 3037: предикаты, соответствующие индексу <имя-доступа>, плохо фильтруются.В среднем каждый доступ к индексу извлекает из таблицы nnn строк. Предел равен nnn. Объяснение: Большое количество строк, извлеченных из таблицы, указывает на неэффективное использование индекса. Действия пользователя: Попробуйте добавить дополнительные предикаты для неиспользуемых столбцов ключа индекса. |
| BMC184420 | Правило № 3038: доступ к индексу будет осуществляться путем сопоставления подмножества доступных столбцов. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184421 | Правило № 3039: для коррелированного подзапроса или соединения вложенного цикла предикаты, соответствующие индексу <имя-доступа>, плохо фильтруются. В среднем каждый доступ к индексу извлекает из таблицы nnn строк. Предел равен nnn. Объяснение: Большое количество строк, извлеченных из таблицы, указывает на неэффективное использование индекса.Для коррелированного подзапроса или соединения с вложенным циклом DB2 повторяет доступ много раз. Действия пользователя: Попробуйте добавить дополнительные предикаты для неиспользуемых столбцов ключа индекса. |
| BMC184422 | Правило № 3040: индекс <имя_доступа> использует сканирование индекса без совпадения. DB2 не может точно сопоставить столбец или столбцы, определенные в индексе. Приблизительное количество страниц для чтения (nnn) превышает стандарт установки (nnn). Объяснение: Все конечные страницы и RID были прочитаны, но совпадающие столбцы не найдены. Сканирование индекса без совпадения может считаться хорошим путем доступа, если используется проверка индекса, OPTIMIZE FOR n ROWS используется с ORDER BY, совпадающим с индексом, или когда несегментированное табличное пространство содержит более одной таблицы. Действия пользователя: Просмотрите ситуации, в которых допустимо сканирование индекса без совпадений. |
| BMC184423 | Правило № 3041: Совет: если индекс состоит из COL1, COL2 и COL3, а инструкция предоставляет предикаты для COL2 и COL3, добавьте COL1 к предикату (если возможно), или измените индекс, или создайте новый индекс с COL2 или COL3 в качестве первого столбца. Объяснение: Оптимизатору не удалось сопоставить ни один столбец в индексе. Сканирования можно избежать, изменив индекс или предикат. Действия пользователя: Добавьте недостающие столбцы в предикат, или добавьте столбцы в предикате в индекс, или создайте новый индекс со столбцами в предикате. |
| BMC184424 | Правило № 3042: сканирование несоответствующего индекса при доступе к Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184425 | Правило № 3043: оператор SQL содержит предикат с коэффициентом фильтрации nnn> nnn, который можно разрешить с фильтром в столбце Explanation: Предикат в названном столбце плохо просматривается из-за высокого коэффициента фильтрации. Действия пользователя: Просмотрите определение индекса. |
| BMC184426 | Правило № 3044: индекс содержит достаточно информации, чтобы удовлетворить эту часть запроса без доступа к базовой таблице. Объяснение: DB2 может полностью избежать чтения страниц данных, если все необходимые данные существуют в индексе. Действия пользователя: Это рекомендуемый путь доступа. |
| BMC184427 | Правило № 3045: оператор SQL содержит предикат с коэффициентом фильтрации nnn Объяснение: Ключи индекса не включают именованный столбец. Предикат имеет низкий коэффициент фильтрации. Действия пользователя: Рассмотрите возможность добавления столбца в индекс. |
| BMC184428 | Правило № 3046: страницы данных таблицы будут доступны для удовлетворения этой части запроса. Это требует дополнительных накладных расходов. Объяснение: Страницы данных таблицы должны быть доступны для оператора UPDATE или DELETE, или если выбранные столбцы отсутствуют в индексе. Действия пользователя: Просмотрите столбцы в своем запросе, чтобы узнать, можно ли удалить какие-либо из них, чтобы включить путь доступа только для индекса. |
| BMC184430 | Правило № 3048: будет вызвана сортировка для удаления повторяющихся строк в новой таблице. Это требует дополнительных затрат на обработку. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184432 | Правило № 3050: сортировка будет вызываться в новой таблице, чтобы выполнить объединение с сканированием слиянием.Внутренняя таблица не кластеризуется по столбцам соединения. Это может привести к дополнительным накладным расходам. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184434 | Правило № 3052: сортировка будет вызываться в новой таблице для удовлетворения гибридного соединения. Индекс внутренней таблицы не был хорошо сгруппирован. Это может привести к дополнительным накладным расходам. Объяснение: Если индекс является индексом кластеризации, для этого запроса может быть полезна реорганизация табличного пространства.Для хорошо сгруппированной внутренней таблицы не требуется сортировка по RID. Действия пользователя: Нет. |
| BMC184435 | Правило № 3053: Совет. Если индекс является индексом кластеризации, для этого запроса может быть полезна реорганизация табличного пространства. Внутренняя таблица с хорошей кластеризацией не требует сортировки по RID. Объяснение: Когда индекс кластеризован, записи вставляются как можно ближе к порядку, определенному индексом.Это улучшает производительность, особенно когда задействовано много записей. Реорганизация поможет сохранить индекс в кластерном порядке и повысить производительность. Действия пользователя: Рассмотрим реорганизацию табличного пространства. |
| BMC184436 | Правило № 3054: сортировка будет вызываться для удовлетворения ORDER BY на новой таблице. Это требует дополнительных затрат на обработку. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184438 | Правило № 3055: сортировка будет вызвана для удовлетворения количественного предиката в новой таблице. Это требует дополнительных затрат на обработку. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184440 | Правило № 3056: сортировка будет вызываться для удовлетворения GROUP BY в новой таблице.Это требует дополнительных затрат на обработку. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184442 | Правило № 3058: будет вызвана сортировка для удаления повторяющихся строк в составной таблице. Это требует дополнительных затрат на обработку. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184444 | Правило № 3060: сортировка будет вызываться в составной таблице, чтобы выполнить объединение с сканированием слиянием. Внешняя таблица не кластеризуется по столбцам соединения. Это может привести к дополнительным накладным расходам. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184446 | Правило № 3062: сортировка будет вызываться в составной таблице для удовлетворения гибридного соединения.Внешняя таблица не кластеризуется по столбцам соединения. Это может привести к дополнительным накладным расходам. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184448 | Правило № 3064: сортировка будет вызываться для удовлетворения ORDER BY в составной таблице. Это требует дополнительных затрат на обработку. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184450 | Правило № 3066: сортировка будет вызываться для удовлетворения количественного предиката в составной таблице. Это требует дополнительных затрат на обработку. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184452 | Правило № 3068: сортировка будет вызываться для удовлетворения GROUP BY в составной таблице.Это требует дополнительных затрат на обработку. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184454 | Правило № 3070: Соответствующие столбцы не полностью используют все столбцы индекса. Сопоставляя большее количество столбцов, вы можете улучшить обработку индекса. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184456 | Правило № 3072: Режим LOCK для этого доступа - Intent SHARE. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184462 | Правило № 3078: Режим БЛОКИРОВКИ для этого доступа - ОБНОВЛЕНИЕ. Объяснение: Владелец блокировки может только читать заблокированные данные.Однако владелец может преобразовать блокировку в блокировку X, а затем изменить данные. Процессы, которые являются параллельными с U-блокировкой, могут получить S-блокировки и прочитать данные, но ни один параллельный процесс не может получить U-блокировку. Владелец блокировки не нуждается в блокировках страниц. U-блокировки снижают вероятность взаимоблокировок, когда владелец блокировки читает данные, чтобы определить, обновлять ли их. Действия пользователя: Нет. |
| BMC184468 | Правило № 3084: данные будут извлечены с использованием последовательной предварительной выборки. Объяснение: Последовательная предварительная выборка позволяет выполнять операции ввода-вывода для данных до того, как данные будут фактически запрошены программой. Это позволит приложению не ждать завершения операций ввода-вывода. Как правило, он будет использоваться для сканирования табличных пространств и несоответствующих индексов. Действия пользователя: Нет. |
| BMC184472 | Правило № 3088: оценка функции столбца будет выполняться при извлечении данных. Объяснение: Это наиболее эффективный тип оценки функции столбца. Действия пользователя: Нет. |
| BMC184474 | Правило № 3090: оценка функции столбца будет выполняться при сортировке данных. Пояснение: Это должно произойти на этапе 2 или при обработке RDS. Это не так эффективно, как обработка на этапе 1. Действия пользователя: Нет. |
| BMC184476 | Правило № 3092: оценка функции столбца не используется ИЛИ оценка функции столбца будет определяться во время выполнения. Объяснение: Значение оценки функции столбца в PLAN_TABLE было пустым. Это означает, что функция столбца будет оцениваться после извлечения данных и после любой сортировки. Действия пользователя: Нет. |
| BMC184478 | Правило № 3094: Многоиндексная операция № шага nnn Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184480 | Правило № 3095: Доступно будущее правило. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184482 | Правило № 3096: Число параллельных операций ввода-вывода, активированных этим запросом: nnn Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184484 | Правило № 3098: Идентификатор группы, связанный с параллельным вводом-выводом: nnn Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184486 | Правило № 3100: Число параллельных операций ввода-вывода, используемых для соединения составной таблицы с новой таблицей: nnn Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184488 | Правило № 3102: Идентификатор группы, связанный с объединенными параллельными вводами / выводами: nnn Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184490 | Правило № 3104: общее количество объектов, необходимых для обработки этого запроса, превышает установленный предел и может отрицательно повлиять на производительность. Обратитесь к администратору базы данных. Предел - nnn. Объяснение: Этот оператор SQL содержит значения, превышающие установленный вами предел. Действия пользователя: Узнайте вместе с администратором баз данных, почему это значение было выбрано для ограничения установки. |
| BMC184492 | Правило № 3106: Таблицы, на которые ссылаются как составные таблицы, часто называются внешней таблицей при обработке соединения. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184494 | Правило № 3108: Таблицы, на которые ссылаются как на новые таблицы, часто называют внутренней таблицей при обработке соединения. Пояснение: Информационное сообщение. Действия пользователя: Нет. |
| BMC184496 | Правило № 3210: блокировка отсутствует. Объяснение: Оптимизатор DB2 вернул пустое значение для столбца TSLOCKMODE в PLAN_TABLE. Блокировка отсутствует. Действия пользователя: Нет. |
| BMC184498 | Правило № 3212: режим LOCK не может быть определен во время BIND.Режим БЛОКИРОВКИ - NS. Объяснение: Если оператор связан с уровнем изоляции UR (незафиксированное чтение), блокировки не будут выполняться. Если уровень изоляции - CS (стабильность курсора), RS (стабильность чтения) или RR (повторяющееся чтение), режим блокировки во время выполнения будет SHARE. Действия пользователя: Нет. |
Анализ предикатов
Анализ предикатов
ASA SQL User's Guide
Оптимизация и выполнение запросов
Преобразования семантических запросов
Анализ предикатов
Предикат - это условное выражение, которое в сочетании с логическими операторами AND и OR составляет набор условий в WHERE, Предложение HAVING или ON.В SQL предикат, имеющий значение UNKNOWN, интерпретируется как FALSE.
Предикат, который может использовать индекс для извлечения строк из таблицы, называется sargable . Это название происходит от фразы с аргументом поиска . Предикаты, которые включают сравнения столбца с константами, другими столбцами или выражениями, могут быть саргируемыми.
Предикат в следующем утверждении является sargable. Adaptive Server Anywhere может эффективно оценить его, используя первичный индекс таблицы сотрудников.
ВЫБРАТЬ * ОТ сотрудника ГДЕ employee.emp_id = 123
employee
В отличие от этого, следующий предикат , а не sargable. Хотя столбец emp_id индексируется в первичном индексе, использование этого индекса не ускоряет вычисление, поскольку результат содержит всю или все строки, кроме одной.
ВЫБРАТЬ * ОТ сотрудника где employee.emp_id <> 123
employee
Аналогичным образом, никакой индекс не может помочь в поиске всех сотрудников, чье имя оканчивается на на букву «k».Опять же, единственный способ вычислить этот результат - исследовать каждую строку по отдельности.
Функции
В общем случае предикат, который имеет функцию для имени столбца, не может быть саргирован. Например, индекс не будет использоваться в следующем запросе:
ВЫБРАТЬ * из sales_order WHERE year (order_date) = '2000'
Иногда вы можете переписать запрос, чтобы избежать использования функции, что сделает его доступным для сортировки. Например, вы можете перефразировать приведенный выше запрос:
ВЫБРАТЬ * из sales_order ГДЕ order_date> '1999-12-31' AND order_date <'2001-01-01'
Запрос, использующий функцию, становится доступным для сортировки, если вы сохраняете значения функции в вычисляемом столбце и строите индекс для этого столбца.Вычисляемый столбец - это столбец, значения которого получены из других столбцов в таблице. Например, если у вас есть столбец с именем order_date, который содержит дату заказа, вы можете создать вычисляемый столбец с именем order_year, который содержит значения для года, извлеченные из столбца order_date.
ИЗМЕНИТЬ ТАБЛИЦУ sales_order ДОБАВИТЬ order_year INTEGER Вычислить год (order_date)
Затем вы можете добавить индекс в столбец order_year обычным способом:
СОЗДАТЬ ИНДЕКС idx_year ON sales_order (order_year)
Если вы затем выполните следующую инструкцию
ВЫБРАТЬ * из sales_order WHERE year (order_date) = '2000'
сервер распознает, что существует индексированный столбец, содержащий эту информацию, и использует этот индекс для ответа на запрос.
Домен вычисляемого столбца должен быть эквивалентен домену выражения COMPUTE, чтобы можно было выполнить замену столбца. В приведенном выше примере, если бы год (order_date) вернул строку вместо целого числа, оптимизатор не заменил бы вычисляемый столбец для выражения, и, следовательно, индекс idx_year не мог использоваться для получения требуемых строк.
Для получения дополнительной информации о вычисляемых столбцах см. Работа с вычисляемыми столбцами.
Примеры
В каждом из этих примеров атрибуты x и y являются столбцами одной таблицы. Атрибут z содержится в отдельной таблице. Предположим, что для каждого из этих атрибутов существует индекс.
| Sargable | Несаргируемый |
|---|---|
| х = 10 | x <> 10 |
| x НУЛЬ | x НЕ ПУТЬ |
| x > 25 | x = 4 ИЛИ y = 5 |
| x = z | x = y |
| x IN (4, 5, 6) | x НЕ В (4, 5, 6) |
| x КАК 'pat%' | x КАК '% tern' |
| х = 20-2 | х + 2 = 20 |
Иногда может быть неочевидно, является ли предикат саргируемым.В этих случаях вы можете переписать предикат, чтобы сделать его доступным для саргетинга. Для каждого примера вы можете переписать предикат x LIKE 'pat%', используя тот факт, что «u» является следующей буквой в алфавите после «t»: x > = 'pat' и x <' пау '. В этой форме индекс атрибута x помогает находить значения в ограниченном диапазоне. К счастью, Adaptive Server Anywhere выполняет это преобразование автоматически.
Предикат sargable, используемый для индексированного поиска по таблице, - это предикат , соответствующий .Предложение WHERE может иметь несколько совпадающих предикатов. Что наиболее подходит, может зависеть от стратегии соединения. Оптимизатор повторно оценивает свой выбор совпадающих предикатов при рассмотрении альтернативных стратегий соединения.
.